Failover và Load Balancing - các khái niệm cơ bản
Theo Bizfly Cloud tìm hiểu - Trong thế giới mạng máy tính, khi nhắc đến các tính năng Failover và Load Balancing, ta thể liên tưởng đến một khái niệm như "lợi ích cộng đồng" khi chia sẻ công việc, giúp tăng hiệu suất làm việc tổng thể — tăng lưu thông, tối ưu hóa hiệu suất và giảm thiểu downtime tối đa.
Fail-over là gì?
Mục tiêu của fail-over là cho phép công việc thường chỉ được thực hiện bởi một máy chủ có thể thực hiện được bởi một máy chủ khác khi một trong 2 máy chủ xảy ra sự cố.
Ví dụ: Server A sẽ phản hồi tất cả các yêu cầu nếu không có bất kỳ lỗi phần cứng nào hoặc không có người nào truy cập vào cáp mạng của nó hoặc không có bất kỳ thảm họa nào xảy ra với trung tâm dữ liệu. Và trong trường hợp Server A không thể đáp ứng được các yêu cầu, thì Server B có thể tiếp quản.
Hoặc nếu bạn chỉ đơn giản là cần một dịch vụ có tính sẵn sàng cao, fail-over cho phép bạn thực hiện bảo trì trên các máy chủ riêng lẻ (các node) mà không cần đến dịch vụ bảo trì truyền thống như trước.
Đối với fail-over của server B, lý tưởng nhất là nên đặt nó trên một ổ cắm điện riêng biệt và tại một trung tâm dữ liệu riêng biệt, hoặc nếu phương án đó không thể thực hiện, ít nhất bạn cũng nên cố gắng đặt nó trên một switch riêng biệt hơn so với server A. Về cơ bản càng tách bạch về vật lý bao nhiêu thì càng tốt bấy nhiêu.
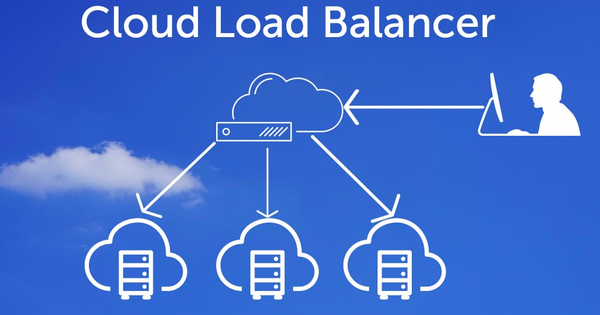
Load balancing - Cân bằng tải là gì?

Load balancing/Cân bằng tải
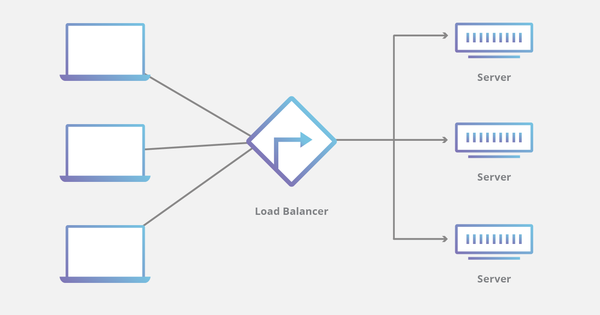
Cân bằng tải cho phép bạn lan rộng tải trên nhiều máy chủ. Bạn sẽ muốn thực hiện điều này trong điều kiện CPU hoặc đĩa IO hoặc dung lượng mạng trên một máy chủ cụ thể đã ở mức cực đại.
Các giải pháp thay thế cho cân bằng tải bao gồm 'mở rộng quy mô' theo chiều dọc, ví dụ, nhận được một phần cứng mạnh mẽ hơn như là các disc, CPU nhanh hơn hoặc network pipe lớn hơn.

https://www.vccloud.vn/load-balancer/?utm_source=techblog&utm_medium=banner696x100&utm_campaign=LB&utm_content=register
Triển khai Fail-over

Triển khai fail-over
Để triển khai Fail-over, bạn thường sẽ phải sao chép dữ liệu của mình trên nhiều máy khác nhau. Bạn có thể thực hiện sao chép thông qua rsync cron cho các tập tin / thư mục. Và thông qua (có thể là) nhân bản MySQL cho cơ sở dữ liệu.
Một cách để kích hoạt Fail-over là thay đổi địa chỉ IP mà domain của bạn trỏ đến. Thay đổi địa chỉ IP có thể diễn ra trong vòng vài phút sau khi cập nhật máy chủ DNS. Dù vậy, nếu một client PC/ máy khách đang ghi lại một IP thì có thể mất nhiều thời gian hơn để nhận thấy sự thay đổi.
Triển khai cân bằng tải
Một cách đơn giản để triển khai cân bằng tải là tách rời dịch vụ giữa các máy chủ, ví dụ: chạy web server trên một máy chủ và server cơ sở dữ liệu trên một máy chủ khác.
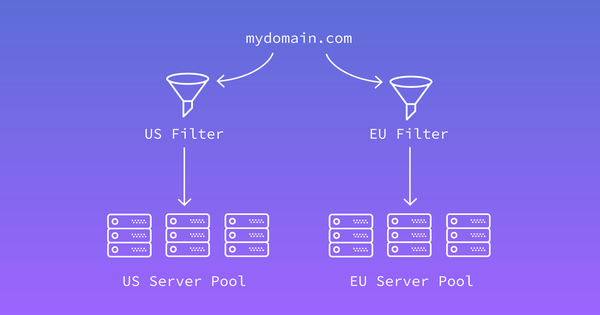
Triển khai theo cách này sẽ dễ dàng bởi sẽ không xảy ra vấn đề gì trong sao chép dữ liệu. Ví dụ: tất cả các file cần thiết đều nằm trên web server, tất cả dữ liệu cần thiết trong cơ sở dữ liệu đều có trên server cơ sở dữ liệu. Một tùy chọn cân bằng tải phổ biến khác là sử dụng nhiều front end server. Để phân phối các yêu cầu tới nhiều server, bạn có thể thiết lập nhiều địa chỉ IP cho một domain cụ thể. Sau đó khách hàng sẽ nhận được tất cả các địa chỉ này và tới một địa chỉ ngẫu nhiên. Như vậy, ta có tải được lan truyền đi khắp nơi.
Một cách khác để phân phối các yêu cầu là sử dụng một IP ảo (VIP) duy nhất mà tất cả các máy khách đều sử dụng. Và như vậy, máy tính trên IP 'ảo' đó sẽ chuyển tiếp các yêu cầu tới máy chủ thực, ví dụ như với haproxy.
Chúng ta cũng có thể thực hiện cân bằng tải thông qua các bộ cân bằng http như mod_proxy_balancer trong Apache 2.2 và Pound.
Vậy còn IP takeover/heartbeat thì sao?
Một công nghệ failover phổ biến là IP failover. Đây là trường hợp mà quy trình 'heartbeat' sẽ chạy trên server của bạn. Và trong trường hợp một server không nhìn thấy heartbeat của một server khác, nó sẽ chiếm IP của server đó (ví dụ: sẽ làm cho IP đó route tới chính nó, thay vì tới một server khác không gửi đi các heartbeat).
Và "shared storage"?
Đã có một vài thảo luận được đưa ra về hệ thống file chia sẻ hoặc theo cụm như sau:
Trong một môi trường lý tưởng, bạn sẽ có một hệ thống file mà bất kỳ server nào cũng có thể đọc / ghi được. Vị trí của hệ thống file sẽ được đặt trên các đĩa trong nhiều server khác nhau, vì vậy mà ở vị trí mà bất kỳ máy chủ hay đĩa nào bị lỗi thì cũng không ảnh hưởng đến tính sẵn sàng của hệ thống file.
Còn trong môi trường thực để làm được điều này bạn cần một hệ thống file theo cụm. Đó là một hệ thống file mà cần phải phối hợp với bất kỳ truy cập đĩa nào giữa các máy chủ khác nhau trong cụm. Để làm vậy, bạn cần phải có phần mềm giám sát (để kiểm tra khi một thiết bị bị hỏng) cũng như phần mềm khóa để đảm bảo rằng sẽ không có hai máy chủ bất kỳ nào thực hiện ghi vào cùng một địa điểm hoặc một máy chủ sẽ không đọc dữ liệu mà một máy chủ khác đang ghi.
Trong môi trường thực, ta có các hệ thống file theo cụm như RedHat, cho phép chạy các hệ thống file theo cụm. Dù vậy, việc thiết lập có thể là 'hơi' (thực ra là thực sự) phức tạp, và nó cũng đòi hỏi những phần cứng đặc biệt để chạy. Và thường thì hệ thống sẽ được triển khai trên một hệ thống shared file đơn nhất (ví dụ SAN) và không hỗ trợ khả năng failover trong trường hợp SAN bị lỗi (các nhà cung cấp SAN có thể sẽ nói với bạn sẽ không có các tình huống như vậy, nhưng trên thực tế thì vẫn có thể xảy ra các sự cố như mất điện hay thiên thạch rơi).
Đối với nhiều ứng dụng, thì giải pháp 'đơn giản' thường là để một máy chủ export một NFS share để các máy chủ khác có thể sử dụng. Và bạn sẽ thiết lập các sao lưu rsync thường xuyên giữa máy chủ đó với các máy chủ khác. Và trong trường hợp xảy ra lỗi, hãy export NFS share từ một máy chủ khác.
Theo https://rimuhosting.com
>> Có thể bạn quan tâm: Khi nào doanh nghiệp cần Load Balancer?


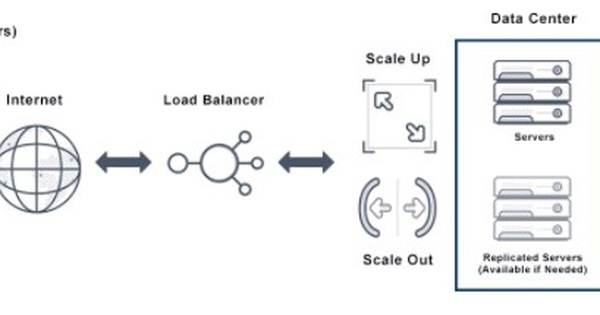

![[Infographic] Cách hoạt động của Cloud Load Balancing](https://techvccloud.mediacdn.vn/zoom/600_315/2019/3/29/cloud-load-balancing-1553827890524947651565-crop-155382789360193715660.jpg)