So sánh máy học có giám sát và máy học không có giám sát
Trong lĩnh vực machine learning, có hai phương pháp phổ biến là máy học có giám sát và máy học không có giám sát. Cả hai phương pháp này đều đóng vai trò quan trọng trong việc xử lý dữ liệu và đưa ra dự đoán. Hai phương pháp này có gì khác nhau? Hãy cùng tìm hiểu sự khác biệt ngay sau đây với Bizfly Cloud nhé!
Máy học có giám sát là gì?
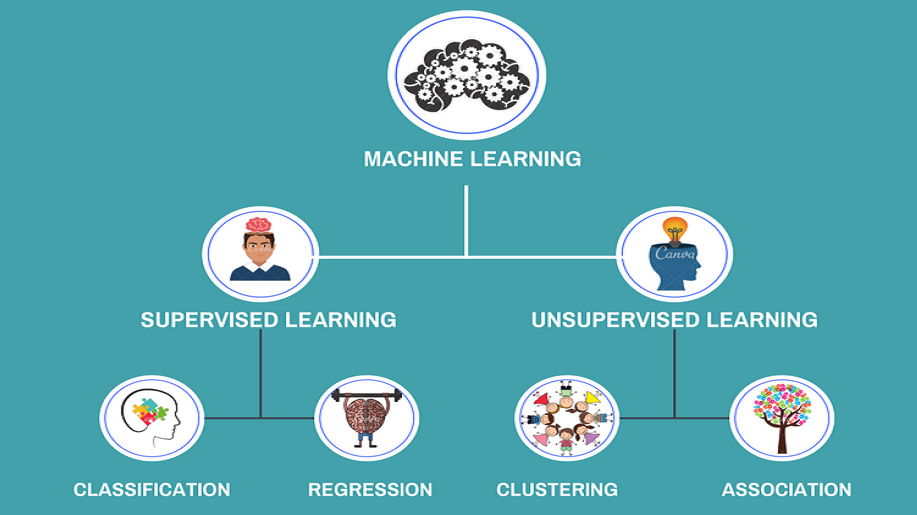
Máy học có giám sát (Supervised Learning) là một phương pháp học máy trong đó mô hình máy học hoạt động trên một tập dữ liệu đã được gán nhãn. Điều này có nghĩa là mô hình học từ các ví dụ đã biết và sau đó được sử dụng để dự đoán hoặc phân loại các dữ liệu mới. Cụ thể, trong Supervised Learning, mô hình học cách ánh xạ đầu vào sang đầu ra dựa trên các cặp dữ liệu huấn luyện đã biết trước. Đây là một trong những phương pháp học máy phổ biến nhất và được sử dụng rộng rãi trong nhiều ứng dụng khác nhau như nhận dạng hình ảnh, dịch ngôn ngữ, và dự đoán tài chính.
Máy học không có giám sát là gì?
Máy học không có giám sát (Unsupervised Learning) là một phương pháp học máy mà không yêu cầu dữ liệu đã được gán nhãn. Trong Unsupervised Learning, mô hình máy học học từ các dữ liệu không có nhãn và tự động tìm ra cấu trúc hoặc mẫu ẩn trong dữ liệu. Mục tiêu của Unsupervised Learning là tìm ra cấu trúc tự nhiên của dữ liệu mà không cần sự hướng dẫn từ bên ngoài.
So sánh máy học có giám sát và máy học không có giám sát về mặt phương pháp
Máy học có giám sát
Hồi quy: Hồi quy có liên quan đến dữ liệu liên tục (hàm giá trị). Trong hồi quy, giá trị đầu ra được dự đoán là số thực. Ví dụ các vấn đề mà hồi quy sẽ giải quyết
Dự đoán giá trị tương lai của cổ phiếu
Dự báo doanh thu doanh nghiệp
Dự báo tiêu thụ năng lượng
Dự đoán nhu cầu
Đánh giá rủi ro tín dụng
Dự đoán lương
Phân loại: Phân loại đề cập đến việc lấy một giá trị đầu vào và ánh xạ nó tới một giá trị riêng biệt. Trong các bài toán phân loại, đầu ra của chúng ta thường bao gồm các lớp hoặc danh mục. Đây có thể là những việc như cố gắng dự đoán những vật thể nào có trong hình ảnh (một con mèo/một con chó) hoặc liệu hôm nay trời có mưa hay không. Ví dụ về các vấn đề phân loại:
Phát hiện ngôn ngữ
Nhận dạng ký tự viết tay và số
Phát hiện gian lận (ví dụ: giao dịch ngân hàng đáng ngờ)
Phân loại phản hồi của khách hàng là tích cực hay tiêu cực
Chẩn đoán bệnh
Phát hiện thư rác
Máy học không có giám sát
Phân cụm: Phân cụm là một kỹ thuật học máy để nhóm dữ liệu chưa được gắn nhãn dựa trên những điểm tương đồng hoặc khác biệt của chúng. Phân cụm giúp tìm thấy các mẫu trong dữ liệu ngay cả khi không biết mình đang tìm kiếm gì. Ví dụ về các vấn đề phân cụm:
Đưa ra đề xuất cá nhân hóa cho sản phẩm, phim hoặc nhạc
Giảm kích thước hình ảnh bằng cách nhóm pixel tương tự với nhau
Xác định nhóm trên mạng xã hội phù hợp dựa trên sự kết nối và tương tác giữa các cá nhân
Phát hiện hành vi bất thường như xâm nhập mạng, giao dịch ngân hàng không minh bạch
Phân tích liên kết: Tập trung vào việc xác định sự xuất hiện đồng thời hoặc sự phụ thuộc giữa các mục mà không có sự hiện diện của nhãn hoặc kết quả được xác định trước. Phân tích liên kết thường được sử dụng để tìm ra các liên kết hoặc quy tắc thú vị (ví dụ: trong phân tích giỏ hàng trong đó mục tiêu là xác định các mặt hàng thường xuyên được mua cùng nhau, chẳng hạn như hàng hóa thường được mua cùng nhau trong cửa hàng tạp hóa). Kết quả hoặc đầu ra của phân tích liên kết thường ở dạng “nếu X thì Y”, chỉ ra rằng khi sản phẩm X xuất hiện, khả năng cao là Y cũng có mặt . Ví dụ về các phân tích liên kết:
Tạo đề xuất được cá nhân hóa dựa trên mối tương quan mua hàng giữa các danh mục
Xác định các tổ hợp sản phẩm hoặc dịch vụ cụ thể có tính liên kết
Tìm hiểu mối tương quan giữa các triệu chứng, phương pháp điều trị và kết quả của bệnh nhân
Giảm kích thước: Kỹ thuật được sử dụng trong học máy khi chúng ta có nhiều thông tin cần xử lý giúp giảm số lượng tính năng làm cho dữ liệu dễ dàng làm việc và hiểu hơn. Ví dụ về các vấn đề giảm kích thước:
Nén và nâng cao hình ảnh và video, giảm dung lượng lưu trữ cần thiết trong khi vẫn giữ được thông tin hình ảnh quan trọng
Giảm độ phức tạp của dữ liệu, các nhà khoa học có thể phân tích và giải thích dữ liệu di truyền

So sánh máy học có giám sát và máy học không có giám sát
Tiêu chí | Học máy được giám sát | Học máy không giám sát |
Dữ liệu đầu vào | Các thuật toán được đào tạo bằng cách sử dụng dữ liệu được dán nhãn. | Các thuật toán được sử dụng đối với dữ liệu không được gắn nhãn |
Độ phức tạp tính toán | Đơn giản | Phức tạp |
Độ chính xác | Cao | Kém chính xác hơn |
Phân tích dữ liệu | Sử dụng phân tích ngoại tuyến | Sử dụng phân tích dữ liệu theo thời gian thực |
Thuật toán được sử dụng | Hồi quy tuyến tính và hậu cần, Rừng ngẫu nhiên, phân loại nhiều lớp, cây quyết định, Máy vectơ hỗ trợ, Mạng thần kinh,... | Phân cụm K-Means, phân cụm phân cấp, thuật toán KNN, Apriori,... |
Dữ liệu đào tạo | Sử dụng dữ liệu huấn luyện để suy ra mô hình. | Không có dữ liệu đào tạo được sử dụng. |
Mô hình phức tạp | Không thể học các mô hình lớn hơn và phức tạp hơn so với học có giám sát. | Có thể học các mô hình lớn hơn và phức tạp hơn bằng cách học không giám sát. |
Ví dụ | Nhận dạng ký tự quang học. | Tìm khuôn mặt trong ảnh. |
Có thể sử dụng máy học có giám sát và máy học không có giám sát cùng nhau không?
Câu trả lời là có, kết hợp máy học có giám sát và máy học không có giám sát cùng nhau ta được máy học bán giám sát.
Máy học bán giám sát là một phương pháp kết hợp các điểm mạnh của học có giám sát và không giám sát trong các tình huống mà chúng ta có tương đối ít dữ liệu được dán nhãn và nhiều dữ liệu không được gắn nhãn.
Quá trình dán nhãn dữ liệu theo cách thủ công rất tốn kém và tẻ nhạt, trong khi dữ liệu không được gắn nhãn lại rất phong phú và dễ lấy. Vì lý do này, thay vì gắn nhãn cho toàn bộ tập dữ liệu, chúng ta chỉ có thể gắn nhãn cho một phần của tập dữ liệu. Cụ thể hơn, các thuật toán máy học bán giám sát sử dụng dữ liệu được gắn nhãn để tìm hiểu các mẫu và mối quan hệ, sau đó áp dụng cho dữ liệu không được gắn nhãn để đưa ra dự đoán hoặc phân loại.
Bằng cách này, máy học bán giám sát giải quyết một số thách thức chính của hai phương pháp còn lại:
Không giống như học không giám sát, máy học bán giám sát có thể xử lý nhiều loại vấn đề, từ phân loại và hồi quy đến phân cụm hoặc liên kết.
Không giống như học có giám sát, máy học bán giám sát cần một lượng nhỏ dữ liệu được dán nhãn, do đó cần ít thời gian chuẩn bị dữ liệu hơn.
Trên đây là một số điểm khác biệt cơ bản giữa máy học có giám sát và máy học không có giám sát. Dù mỗi phương pháp đều có ưu điểm và hạn chế riêng, nhưng cả hai đều đóng vai trò quan trọng trong việc phân tích và xử lý dữ liệu.