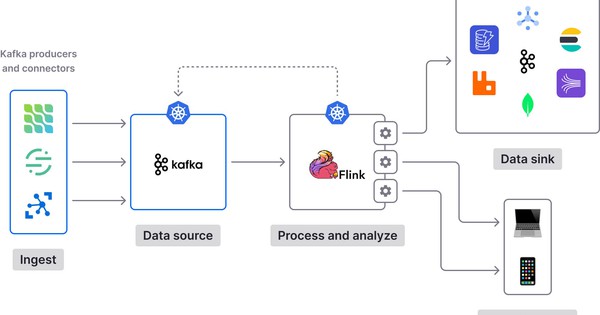
Kafka Connect là gì? Cách hoạt động và hướng dẫn triển khai
Kafka Connect là một thành phần cốt lõi của hệ sinh thái Apache Kafka, giúp dễ dàng kết nối Kafka với các nguồn dữ liệu và đích đến khác nhau một cách tự động, ổn định và mở rộng. Trong bài viết này, chúng ta sẽ cùng Bizfly Cloud tìm hiểu chi tiết về Kafka Connect là gì, các thành phần chính, cách hoạt động, hướng dẫn triển khai từng bước để hiểu rõ nhất về framework này.
Kafka Connect là gì?

Kafka Connect là một framework/công cụ mã nguồn mở trong hệ sinh thái Apache Kafka
Kafka Connect là một framework của Apache Kafka, được thiết kế để giúp dễ dàng tích hợp dữ liệu giữa Kafka và các hệ thống bên ngoài như cơ sở dữ liệu, hệ thống lưu trữ tệp, hệ thống phân phối message khác hoặc các dịch vụ đám mây. Thay vì phải viết mã thủ công phức tạp để đồng bộ dữ liệu, Kafka Connect cung cấp các connector sẵn có hoặc tùy chỉnh, giúp giảm thiểu thời gian và công sức, đồng thời đảm bảo tính mở rộng, khả năng chịu lỗi và quản lý dễ dàng.
Một điểm mạnh của Kafka Connect chính là khả năng hoạt động như một dịch vụ nền, liên tục theo dõi các nguồn dữ liệu và đẩy dữ liệu vào Kafka hoặc xuất dữ liệu ra các hệ thống khác một cách tự động. Nhờ đó, các doanh nghiệp có thể xây dựng hệ sinh thái dữ liệu linh hoạt, thích nghi nhanh với yêu cầu thay đổi mà không cần sửa đổi lớn trong hệ thống.
Ngoài ra, Kafka Connect còn hỗ trợ quản lý trạng thái, phân vùng dữ liệu, cân bằng tải và đảm bảo độ chính xác của dữ liệu truyền qua lại, giúp nâng cao đáng kể khả năng xử lý dữ liệu quy mô lớn. Chính vì vậy, đây là công cụ không thể thiếu trong các kiến trúc dữ liệu hiện đại dựa trên Kafka.
Các thành phần chính của Kafka Connect
Khi tìm hiểu về Kafka Connect, điều quan trọng là phải nắm rõ các thành phần cấu thành giúp nó vận hành trơn tru. Mỗi thành phần đều đóng vai trò riêng, hỗ trợ quá trình kết nối, đồng bộ dữ liệu diễn ra liên tục, hiệu quả.
Các thành phần chính gồm có:
1. Distributed & Standalone Mode (Chế độ phân tán và chế độ độc lập)
Kafka Connect có thể chạy dưới dạng chế độ phân tán hoặc chế độ độc lập. Chế độ độc lập phù hợp cho môi trường nhỏ, ít connector hoặc thử nghiệm, trong khi chế độ phân tán phù hợp với các hệ thống lớn, yêu cầu mở rộng cao và khả năng chịu lỗi tốt hơn. Việc lựa chọn chế độ phù hợp sẽ ảnh hưởng lớn đến khả năng mở rộng và quản lý của hệ thống.
Chế độ phân tán cho phép nhiều worker cùng làm việc song song, chia sẻ tải và khắc phục lỗi dễ dàng hơn. Ngược lại, chế độ độc lập đơn giản hơn, thích hợp cho các tác vụ nhẹ hoặc môi trường phát triển, thử nghiệm. Tùy thuộc vào quy mô và mục đích sử dụng, các tổ chức có thể linh hoạt lựa chọn phù hợp.
2. Connectors (Connector - Bộ kết nối)
Các connector chính là các plugin hoặc module giúp kết nối Kafka với các hệ thống nguồn hoặc đích. Có hai loại connector phổ biến:
- Source Connector: Lấy dữ liệu từ hệ thống bên ngoài rồi đẩy vào Kafka.
- Sink Connector: Lấy dữ liệu từ Kafka ra hệ thống đích như database, hệ thống phân phối khác.
Mỗi connector có thể được tùy chỉnh hoặc sử dụng sẵn theo nhu cầu. Điều đặc biệt là cộng đồng Kafka và các nhà cung cấp đã phát triển rất nhiều connector đa dạng, giúp việc tích hợp trở nên dễ dàng hơn.
3. Workers (Các worker)
Workers chính là các tiến trình chạy Kafka Connect để thực hiện nhiệm vụ kết nối dữ liệu. Trong chế độ phân tán, nhiều worker sẽ phối hợp để đảm bảo cân bằng tải và khả năng phục hồi. Trong chế độ độc lập, chỉ cần một worker đơn lẻ. Workers quản lý các connector, giám sát trạng thái, xử lý lỗi và duy trì hoạt động liên tục.
4. Configuration (Cấu hình)
Phần cấu hình xác định cách thức hoạt động của các connector cũng như toàn hệ thống Kafka Connect. Bao gồm các tham số như địa chỉ Kafka, các tùy chọn liên quan đến kết nối, phân vùng, chế độ hoạt động, các thiết lập về logging, lỗi, v.v. Cấu hình chính xác là yếu tố then chốt để hệ thống vận hành ổn định.
5. Offset Storage (Lưu trữ offset)
Đây là nơi Kafka Connect lưu trữ thông tin về vị trí tiêu thụ dữ liệu của connector, giúp đảm bảo quá trình đọc và ghi dữ liệu đúng thứ tự, tránh bị mất mát hoặc trùng lặp dữ liệu. Người dùng có thể chọn lưu offset trong Kafka hoặc trong hệ thống lưu trữ bên ngoài như RDBMS hoặc file.
Kafka Connect hoạt động như thế nào?
Hiểu rõ cách Kafka Connect hoạt động sẽ giúp bạn dễ dàng tối ưu và xử lý các trường hợp phát sinh. Quá trình này bắt đầu từ việc định nghĩa các connector, sau đó các worker sẽ thực thi và quản lý việc lấy dữ liệu hoặc đẩy dữ liệu một cách liên tục.
Quá trình hoạt động của Kafka Connect có thể được chia thành các bước chính:
1. Khởi tạo và cấu hình
Bạn sẽ bắt đầu bằng việc cấu hình các connector phù hợp với hệ thống của mình. Các tham số cấu hình sẽ xác định nguồn dữ liệu, đích đến, tần suất, chế độ hoạt động, và các tùy chọn khác. Sau đó, các connector này sẽ được đăng ký vào Kafka Connect.
2. Phân phối và quản lý
Trong chế độ phân tán, nhiều worker sẽ nhận nhiệm vụ cùng lúc, chia sẻ tải dựa trên cấu hình và khả năng xử lý. Hệ thống sẽ tự động cân bằng tải, đảm bảo rằng không worker nào bị quá tải hoặc bỏ sót tác vụ. Các worker này sẽ theo dõi trạng thái của connector, xử lý lỗi hoặc sự cố bất ngờ.
3. Di chuyển dữ liệu liên tục
Các source connector sẽ liên tục lấy dữ liệu từ nguồn, sau đó gửi tới Kafka theo các phân vùng. Các sink connector sẽ lấy dữ liệu từ Kafka và đưa ra hệ thống đích. Quá trình này luôn diễn ra một cách liên tục, nhờ vào cơ chế offset để đảm bảo dữ liệu không bị trùng lặp hoặc bỏ sót.
4. Giám sát và duy trì
Hệ thống Kafka Connect cung cấp khả năng giám sát trạng thái hoạt động của tất cả các connector và worker. Nếu có lỗi xảy ra, hệ thống sẽ cảnh báo hoặc tự động khởi động lại. Quản trị viên có thể kiểm tra logs, theo dõi hiệu suất và điều chỉnh cấu hình để đảm bảo hoạt động trơn tru.
5. Lưu trữ offset và theo dõi tiến trình
Offset là phần không thể thiếu để đảm bảo tính nhất quán và chính xác của dữ liệu. Kafka Connect sẽ lưu offset vào Kafka hoặc hệ thống khác, giúp duy trì trạng thái tiêu thụ. Khi có lỗi hoặc gián đoạn, hệ thống sẽ lấy lại vị trí offset và tiếp tục quá trình xử lý từ điểm dừng cuối cùng.
Hướng dẫn triển khai Kafka Connect từng bước
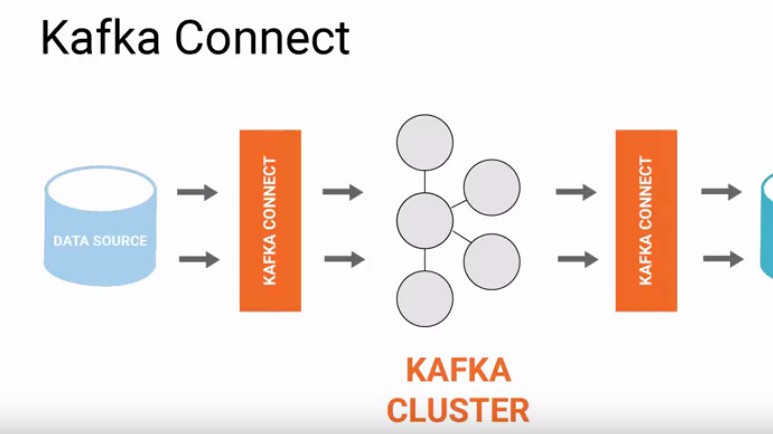
Việc triển khai Kafka Connect đúng cách sẽ đảm bảo hệ thống hoạt động ổn định, dễ bảo trì và mở rộng trong tương lai. Dưới đây là hướng dẫn chi tiết từng bước, từ chuẩn bị môi trường đến kiểm tra, giám sát và tối ưu hệ thống.

Triển khai Kafka Connect giúp tự động hóa luồng dữ liệu giữa Kafka và các hệ thống bên ngoài
Bước 1: Chuẩn bị môi trường
Trước tiên, bạn cần chuẩn bị các thành phần thiết yếu như máy chủ hoặc VM để chạy Kafka, Zookeeper và Kafka Connect. Đảm bảo rằng hệ thống của bạn đã cài đặt Java (phiên bản phù hợp) và có đủ tài nguyên để xử lý dữ liệu lớn.
Ngoài ra, hãy chuẩn bị các hệ thống nguồn và đích mà bạn muốn tích hợp, như các cơ sở dữ liệu, hệ thống lưu trữ hoặc dịch vụ cloud. Việc xác định rõ các hệ thống này sẽ giúp bạn chọn đúng loại connector, cấu hình phù hợp và tối ưu quá trình đồng bộ dữ liệu.
Việc cài đặt Kafka và Zookeeper đúng chuẩn là bước cực kỳ quan trọng, vì chúng là nền tảng để Kafka Connect hoạt động. Bạn cần đảm bảo các dịch vụ này khởi động thành công, không gặp lỗi và có thể giao tiếp tốt với các thành phần khác của hệ thống.
Bước 2: Cấu hình Worker
Tiếp theo, bạn cần cấu hình các worker cho Kafka Connect. Nếu triển khai theo chế độ độc lập, chỉ cần tạo file cấu hình đơn giản như connect-standalone.properties. Trong chế độ phân tán, bạn cần cấu hình các worker trong một cluster, tạo file cấu hình phù hợp và khởi động các worker này.
Các tham số cấu hình bao gồm địa chỉ Kafka, file chứa các connector, các thiết lập về offset, logging, và các tùy chọn liên quan đến hiệu năng. Việc cấu hình chính xác giúp hệ thống hoạt động ổn định, giảm thiểu lỗi và dễ dàng mở rộng sau này.
Không chỉ cấu hình cho worker, bạn còn cần chú ý đến quyền truy cập, bảo mật, và các thiết lập mạng để các thành phần có thể giao tiếp một cách an toàn, hiệu quả. Đây là bước then chốt để đảm bảo toàn bộ hệ thống vận hành liên tục.
Bước 3: Tạo Connector
Sau khi worker đã sẵn sàng, bạn sẽ tạo các connector phù hợp với nhu cầu. Việc này có thể thực hiện qua API REST của Kafka Connect hoặc qua các file cấu hình định dạng JSON hoặc properties.
Bạn cần xác định rõ các thông số như nguồn dữ liệu, đích đến, tần suất lấy dữ liệu, các chế độ xử lý lỗi, và các tùy chọn chuyên biệt khác. Một số connector phổ biến như JDBC Source/Sink, FileStream, Elasticsearch, S3, MongoDB… đều có thể sử dụng để dễ dàng tích hợp các hệ thống khác nhau.
Việc tạo connector đúng cách đóng vai trò quyết định đến hiệu năng cũng như độ chính xác của quá trình truyền dữ liệu. Khi đã hoàn tất cấu hình, hãy khởi động connector và kiểm tra trạng thái ban đầu để đảm bảo không có lỗi xảy ra.
Bước 4: Kiểm tra và giám sát
Cuối cùng, bạn cần liên tục theo dõi hoạt động của Kafka Connect để đảm bảo mọi thứ diễn ra suôn sẻ. Thông qua dashboard, logs hoặc các API giám sát, bạn có thể kiểm tra trạng thái các connector, worker, offset, và hiệu suất dữ liệu.
Nếu gặp lỗi hoặc phát hiện chồng chất các vấn đề, hãy xử lý kịp thời để tránh gián đoạn lớn. Ngoài ra, việc tối ưu cấu hình, cập nhật connector mới và kiểm tra khả năng mở rộng sẽ giúp hệ thống của bạn luôn vận hành ổn định, sẵn sàng đối mặt với yêu cầu ngày càng tăng của doanh nghiệp.
Ví dụ triển khai thực tế
Để minh họa rõ hơn, chúng ta sẽ đi qua một ví dụ cụ thể về việc tích hợp dữ liệu từ cơ sở dữ liệu MySQL vào Hệ thống lưu trữ dữ liệu Hadoop bằng Kafka Connect.
Trong trường hợp này, chúng ta sẽ sử dụng JDBC Source Connector để lấy dữ liệu từ MySQL và HDFS Sink Connector để đẩy dữ liệu vào HDFS. Quá trình này sẽ giúp minh chứng rõ ràng các bước, từ chuẩn bị đến giám sát, đồng thời cho thấy khả năng mở rộng của Kafka Connect trong các tình huống thực tế.
Đầu tiên, bạn cần cài đặt Kafka, Zookeeper và Kafka Connect, sau đó cấu hình các connector phù hợp. Tiếp theo, bạn sẽ theo dõi dữ liệu chạy liên tục, xử lý lỗi và tối ưu hiệu suất. Kết quả cuối cùng là một pipeline dữ liệu ổn định, tự động, giúp doanh nghiệp có thể phân tích dữ liệu một cách nhanh chóng và chính xác.
Trong thực tế, nhiều doanh nghiệp không chỉ quan tâm đến cách triển khai Kafka Connect mà còn tìm kiếm Dịch vụ Kafka để rút ngắn thời gian xây dựng hạ tầng, giảm áp lực vận hành và đảm bảo hệ thống streaming hoạt động ổn định ngay từ đầu. Khi kết hợp Kafka Connect với một nền tảng Kafka được quản trị sẵn, đội ngũ kỹ thuật có thể tập trung nhiều hơn vào bài toán tích hợp dữ liệu và phát triển ứng dụng.
Khi nào nên và không nên dùng Kafka Connect?
Việc chọn đúng công cụ giúp tối ưu hệ thống và tiết kiệm chi phí, thời gian là điều vô cùng quan trọng. Do đó, cần nắm rõ khi nào phù hợp để sử dụng Kafka Connect và khi nào không.
Nên dùng khi
- Bạn cần tích hợp dữ liệu liên tục, tự động và quy mô lớn giữa Kafka và các hệ thống bên ngoài.
- Có nhiều nguồn dữ liệu hoặc hệ thống đích cần đồng bộ, và mong muốn giảm thiểu việc viết mã thủ công.
- Yêu cầu độ trễ thấp, dữ liệu phải được xử lý gần như theo thời gian thực.
- Muốn hệ thống dễ mở rộng, chịu lỗi tốt và dễ bảo trì trong dài hạn.
Trong các trường hợp này, Kafka Connect mang lại lợi ích lớn về khả năng tự động hóa, khả năng mở rộng và quản lý tập trung, giúp doanh nghiệp tối ưu hoạt động dữ liệu.
Không nên dùng khi
- Dữ liệu cần xử lý phức tạp, tùy chỉnh cao mà connector không đáp ứng đủ yêu cầu.
- Hệ thống yêu cầu xử lý dữ liệu theo kiểu batch, không cần liên tục hoặc thời gian thực.
- Các hệ thống nguồn hoặc đích quá đặc thù, không có connector phù hợp, hoặc yêu cầu xử lý đặc biệt mà Kafka Connect không thể đáp ứng.
- Có giới hạn về tài nguyên hoặc không thể đảm bảo hoạt động liên tục của Kafka Connect do các lý do kỹ thuật hoặc bảo mật.
Trong các trường hợp này, phương pháp thủ công hoặc các công cụ tích hợp khác có thể phù hợp hơn, mặc dù sẽ tốn nhiều thời gian và công sức hơn.
Các lỗi thường gặp khi triển khai Kafka Connect
Triển khai Kafka Connect không phải lúc nào cũng suôn sẻ. Việc gặp lỗi là điều thường xuyên, đặc biệt trong giai đoạn đầu thiết lập. Hiểu rõ các lỗi phổ biến sẽ giúp bạn xử lý nhanh hơn và nâng cao hiệu quả vận hành.
Một số lỗi thường gặp gồm có:
- Lỗi cấu hình: Sai cú pháp, thiếu tham số cần thiết hoặc sai URL, port, tên người dùng, password… dẫn đến connector không hoạt động đúng hoặc không khởi động được.
- Lỗi kết nối mạng: Kafka Connect không thể liên lạc được với Kafka hoặc hệ thống nguồn/đích do vấn đề mạng hoặc firewall.
- Lỗi về offset: Dữ liệu bị mất hoặc bị trùng lặp do offset không được lưu đúng hoặc bị xóa mất.
- Tràn bộ nhớ hoặc quá tải: Worker hoặc connector xử lý quá nhiều dữ liệu cùng lúc gây treo hoặc chậm chạp.
- Lỗi liên quan đến phiên bản: Phiên bản connector không tương thích hoặc không phù hợp với Kafka hoặc hệ thống nguồn/đích.
- Vấn đề về bảo mật: Thiếu quyền truy cập, chứng thực không hợp lệ hoặc SSL/TLS không cấu hình đúng.
Việc theo dõi logs, sử dụng các công cụ giám sát, và kiểm thử kỹ cấu hình trước khi triển khai chính thức là cách tốt nhất để hạn chế các lỗi này.
Kết luận
Kafka Connect là một công cụ mạnh mẽ, giúp đơn giản hóa quá trình tích hợp dữ liệu trong hệ sinh thái Kafka. Với khả năng tự động hóa, mở rộng linh hoạt, khả năng chịu lỗi cao và cộng đồng phát triển mạnh mẽ, Kafka Connect đã trở thành lựa chọn hàng đầu cho các doanh nghiệp xây dựng hệ thống dữ liệu thời đại mới.
Tuy nhiên, để tận dụng tối đa các lợi ích của Kafka Connect, người dùng cần hiểu rõ các thành phần, cách hoạt động, biết cách cấu hình đúng và xử lý các lỗi phát sinh hiệu quả. Đồng thời, việc xác định đúng thời điểm phù hợp để sử dụng cũng đóng vai trò quan trọng trong thành công của dự án.
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn toàn diện về Kafka Connect, giúp bạn dễ dàng hơn trong việc triển khai, vận hành và khai thác tối đa công cụ này cho các mục tiêu dữ liệu của mình.