Kafka Stream là gì? Cách Kafka Streams xử lý dữ liệu thời gian thực
Kafka Streams là một trong những lựa chọn phổ biến khi cần xử lý dữ liệu theo thời gian thực. Thay vì phải dựng thêm nhiều hệ thống phức tạp, bạn có thể tận dụng trực tiếp hệ sinh thái Kafka để xử lý dữ liệu ngay khi nó được sinh ra.
Bài viết này Bizfly Cloud sẽ giúp bạn hiểu rõ Kafka Streams là gì, cách nó hoạt động và khi nào nên hoặc không nên dùng Kafka Streams.
Kafka stream (Kafka Streams) là gì?
Kafka Streams là một thư viện xử lý dữ liệu dạng stream được phát triển bởi Apache Kafka. Hiểu theo một cách đơn giản, nó giúp bạn xử lý dữ liệu liên tục (real-time), chạy như một ứng dụng bình thường và được tích hợp trực tiếp với Kafka.
Điểm đáng chú ý của nó chính là bạn không cần dựng thêm hệ thống như Spark hay Flink để xử lý stream. Với Kafka Streams, phần xử lý được nhúng luôn vào application.
Kafka Stream sở hữu khả năng tích hợp sẵn những chức năng phức tạp như: kết hợp dữ liệu từ các nguồn khác nhau, xử lý dữ liệu theo window, trạng thái,... những ứng dụng được xây dựng dựa trên Kafka Stream có thể thích nghi với quy mô lớn.
Vì sao Kafka Streams phù hợp xử lý dữ liệu thời gian thực
Trong các hệ thống hiện đại, dữ liệu không đến theo từng batch nữa mà đến liên tục. Vậy nên nếu xử lý chậm thì dữ liệu gần như mất giá trị.
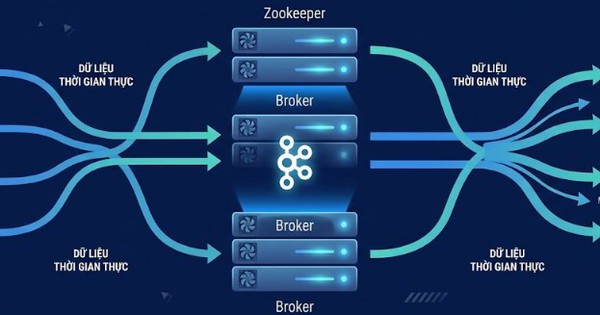
Kafka vốn được xây dựng để xử lý việc “đẩy - nhận” dữ liệu rất nhanh qua topic. Nhưng để biến dữ liệu đó thành giá trị thật sự thì lúc này lại cần một lớp xử lý ở giữa. Lúc này Kafka Streams phát huy tác dụng.
Một vài lý do khiến Kafka Streams được dùng nhiều trong việc xử lý dữ liệu thời gian thực hiện nay chính là:
- API khá dễ tiếp cận (so với các framework streaming khác)
- Không cần quản lý cluster riêng
- Xử lý phân tán sẵn
- Có hỗ trợ state, window ngay trong thư viện
Kafka Streams xử lý dữ liệu thời gian thực theo luồng như thế nào?
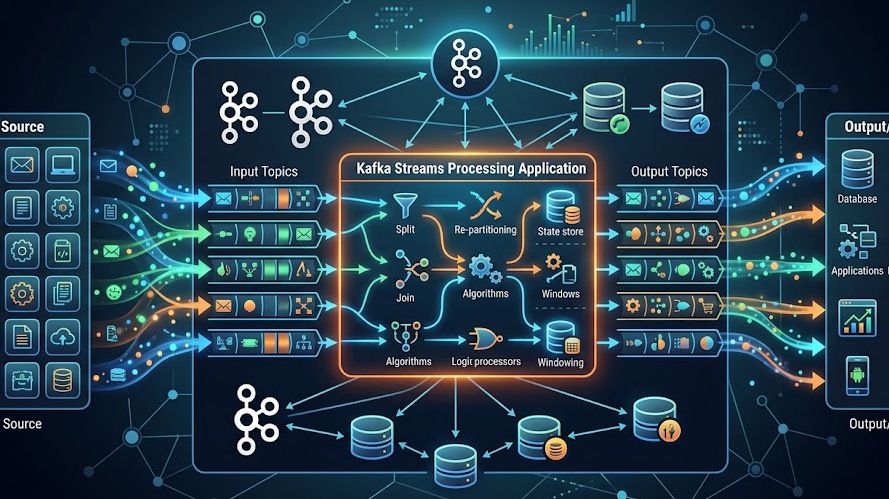
Khác với các phương pháp xử lý dữ liệu truyền thống dựa trên batch (lấy dữ liệu theo khoảng thời gian rồi xử lý), Kafka Streams tập trung vào xử lý dữ liệu theo dòng chảy liên tục. Dưới đây là quy trình cơ bản mà Kafka Streams sử dụng để xử lý dữ liệu theo luồng:

Kafka Streams là một thư viện Java mã nguồn mở, gọn nhẹ, được dùng để xây dựng ứng dụng
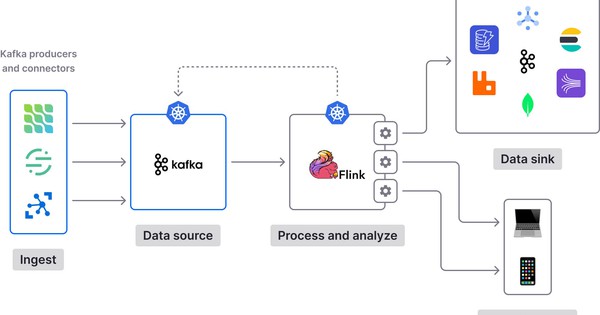
Bước 1: Nhận dữ liệu từ topic
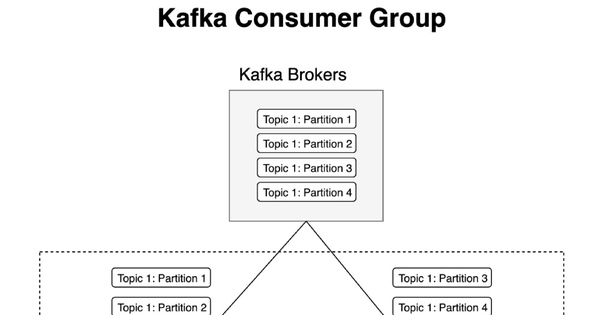
Dữ liệu được đẩy vào Kafka topic từ producer. Kafka Streams đóng vai trò consumer, liên tục đọc dữ liệu mới. Quá trình này giống như việc mở một "kênh tiếp thị" để luôn cập nhật các thông tin mới nhất, giúp hệ thống phản ứng ngay lập tức khi có dữ liệu mới xuất hiện.
Việc nhận dữ liệu theo thời gian thực từ các topic là điểm mạnh của Kafka Streams. Hệ thống có thể xử lý hàng triệu bản ghi mỗi giây mà vẫn đảm bảo độ trễ thấp, nhờ vào kiến trúc phân tán mạnh mẽ của Kafka và khả năng xử lý song song của Kafka Streams.
Bước 2: Tạo “pipeline xử lý” (topology) để biến đổi dữ liệu
Sau khi nhận dữ liệu, bước tiếp theo là xây dựng pipeline xử lý thông qua topology để biến đổi, lọc, tổng hợp hoặc phân tích dữ liệu theo yêu cầu của ứng dụng.
Kafka Streams sở hữu khả năng định nghĩa các vòng lặp, phân đoạn dữ liệu theo thời gian, đồng bộ và xử lý theo trạng thái. Nhờ vậy, các ứng dụng có thể xây dựng các quy trình xử lý phức tạp mà không cần phải xử lý thủ công từng bước.
Bước 3: Khi nào cần “nhớ” dữ liệu?
Trong quá trình xử lý luồng dữ liệu, không phải lúc nào cũng cần phải nhớ toàn bộ dữ liệu đã xử lý. Tuy nhiên, có những trường hợp đặc thù yêu cầu duy trì trạng thái để cung cấp các kết quả chính xác hơn hoặc để xử lý các phép tính liên tiếp dựa trên dữ liệu trước đó.
Ví dụ như đếm số lần truy cập trong một khoảng thời gian, tính tổng doanh thu hàng ngày hoặc phát hiện các sự kiện bất thường dựa trên lịch sử.
Kafka Streams hỗ trợ stateful processing, cho phép:
- Lưu trạng thái tạm thời
- Cập nhật liên tục khi có dữ liệu mới
Đây là điểm khiến cho nó mạnh hơn so với xử lý stateless đơn thuần.
Bước 4: Lưu state và đảm bảo khôi phục khi lỗi
Trong môi trường phân tán, chắc chắn không thể tránh khỏi các sự cố như mất kết nối, lỗi phần cứng hoặc lỗi phần mềm.
Kafka Streams sử dụng Kafka làm kho lưu trữ, khi gặp lỗi các ứng dụng có thể khởi động lại và tự động khôi phục state từ Kafka, giúp duy trì tính liên tục và chính xác của luồng dữ liệu. Nó còn có khả năng xử lý tình huống phức tạp, phân tán và cân bằng tải giúp cho việc duy trì trạng thái dễ dàng và hiệu quả hơn.
Bước 5: Ghi kết quả ra output topic và cấp cho hệ thống khác
Khi đã xử lý xong, bước cuối cùng trong pipeline của Kafka Streams là ghi dữ liệu ra các output topic để các hệ thống khác có thể tiếp tục tiêu thụ, phân tích hoặc lưu trữ dữ liệu này.
Các kết quả xử lý này có thể là dữ liệu đã được biến đổi, tổng hợp, hoặc phân loại, phù hợp cho các nhu cầu báo cáo thời gian thực, cảnh báo tự động hoặc phân tích xu hướng. Thực tế, các doanh nghiệp có thể tận dụng các output này để xây dựng hệ thống BI, AI, hoặc các dịch vụ thời gian thực một cách hiệu quả.
Khái niệm cốt lõi để hiểu Kafka Streams
Để có thể xây dựng và vận hành các ứng dụng dựa trên Kafka Streams một cách chuyên nghiệp, cần nắm rõ các khái niệm nền tảng. Dưới đây là ba khái niệm quan trọng nhất: KStream, KTable và Window, mỗi cái mang ý nghĩa riêng biệt và hỗ trợ lẫn nhau trong việc xử lý dữ liệu.
KStream
KStream là thành phần cốt lõi của Kafka Streams, đại diện cho luồng dữ liệu liên tục. Nó xử lý từng bản ghi một cách tuần tự, phù hợp với: Event streaming, log processing, tracking hành vi người dùng.
KStream là mô hình ideal cho các ứng dụng cần phản hồi trực tiếp với các sự kiện mới xuất hiện, chẳng hạn như theo dõi hoạt động của người dùng, phân tích luồng dữ liệu từ cảm biến, hay xử lý các sự kiện trong hệ thống giao dịch tài chính. Đặc điểm nổi bật của KStream khiến cho nó phù hợp với các nhiệm vụ không đòi hỏi phải giữ trạng thái lâu dài.
KTable
Khác với KStream, KTable giống như một bảng dữ liệu, nơi mỗi khóa chỉ có duy nhất một giá trị tại một thời điểm nhất định. KTable thường được dùng để lưu trữ các dữ liệu dạng cập nhật liên tục như: danh sách người dùng, cấu hình hệ thống hoặc trạng thái hiện tại của các đối tượng.
KTable cung cấp khả năng cập nhật liên tục và tự động phản ánh các thay đổi, giúp các ứng dụng có thể duy trì dữ liệu hiện tại một cách chính xác và hiệu quả.
Window
Window trong Kafka Streams dùng để chia nhỏ luồng dữ liệu thành các khoảng thời gian. Công cụ này cực kỳ hữu ích trong các phân tích thời gian như: phát hiện xu hướng, cảnh báo dựa trên các sự kiện xảy ra trong một khoảng thời gian cụ thể.
Cơ chế window giúp xử lý dữ liệu theo các khung thời gian cố định hoặc không cố định, tạo điều kiện để phân tích dữ liệu theo chu kỳ hoặc theo bối cảnh thời gian thực.
Khi nào nên dùng Kafka Streams và khi nào không?
Việc lựa chọn Kafka Streams phù hợp hay không phụ thuộc vào mục tiêu, quy mô và đặc thù của hệ thống xử lý dữ liệu của bạn. Kafka Streams rất mạnh mẽ trong các trường hợp đòi hỏi xử lý thời gian thực, tích hợp dễ dàng, và khả năng mở rộng linh hoạt, nhưng cũng có giới hạn nhất định.
Nên dùng Kafka Streams khi:
- Hệ thống đã dùng Kafka
- Cần xử lý real-time mức vừa phải
- Không muốn vận hành thêm cluster riêng
- Logic xử lý không quá phức tạp
Không nên dùng Kafka Streams khi:
- Pipeline cực kỳ phức tạp
- Cần xử lý data cực lớn, phân tán sâu
- Yêu cầu latency cực thấp ở quy mô lớn
Trong những trường hợp như vậy thì việc sử dụng các nền tảng như Apache Flink hoặc Spark Streaming có thể phù hợp hơn.
Kết luận
Kafka Streams là một cách tiếp cận khá nhanh gọn để xử lý dữ liệu thời gian thực, đặc biệt nếu bạn đã sử dụng Kafka trong hệ thống.
Mặc dù nó không phải công cụ mạnh nhất trong mọi trường hợp, nhưng có thể thấy rằng đây là công cụ dễ triển khai, tích hợp nhanh và đủ mạnh cho nhiều use case phổ biến.
Nếu bạn hiểu rõ cách nó hoạt động thì chắc chắn có thể xây dựng được các pipeline xử lý dữ liệu tương đối linh hoạt mà không cần thêm quá nhiều thành phần phức tạp.