Kafka Python: Chọn thư viện đúng và triển khai đúng cách
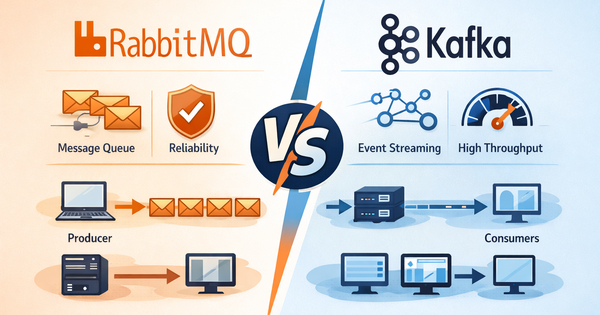
Kết hợp Kafka với Python giúp các nhà phát triển dễ dàng xây dựng các hệ thống stream dữ liệu mạnh mẽ, linh hoạt. Tuy nhiên, để đạt hiệu quả tối ưu, việc chọn đúng thư viện Kafka Python phù hợp và biết cách triển khai đúng cách là cực kỳ quan trọng. Bài viết dưới đây Bizfly Cloud sẽ giúp bạn nắm rõ hơn về vấn đề này.
Bạn đang cần Kafka trong Python để làm gì?
Khi nghĩ đến Kafka trong Python, mục tiêu lớn nhất là làm thế nào để có thể dễ dàng và hiệu quả trong việc gửi, nhận và xử lý dòng dữ liệu lớn theo thời gian thực. Các ứng dụng phổ biến bao gồm phân tích dữ liệu, hệ thống giám sát, tự động cập nhật dữ liệu cho các dịch vụ backend, hoặc xây dựng pipeline dữ liệu phức tạp. Người phát triển cần một thư viện phù hợp để không chỉ kết nối dễ dàng mà còn mở rộng và tối ưu hiệu suất.
Trong thực tế, nhu cầu sử dụng Kafka với Python có thể đa dạng từ các dự án nhỏ, prototype nhanh, cho đến các hệ thống đòi hỏi xử lý dữ liệu lớn và phức tạp. Việc chọn đúng thư viện sẽ ảnh hưởng lớn đến trải nghiệm nhà phát triển, độ ổn định của hệ thống và khả năng mở rộng về sau. Đặc biệt, các thư viện như Confluent Kafka Python, kafka-python, hay Quix Streams đều có những đặc điểm riêng phù hợp với từng trường hợp cụ thể.

Việc lựa chọn thư viện Kafka cho Python phụ thuộc vào nhu cầu về hiệu năng và sự đơn giản
3 thư viện Kafka Python phổ biến và nên chọn trường hợp nào
Confluent-kafka
Confluent Kafka Python là wrapper nhẹ xung quanh librdkafka - thư viện C/C++ nổi tiếng, đã có một cộng đồng lớn và ổn định. Thư viện này cung cấp các lớp Producer, Consumer, AdminClient và tích hợp sâu các tính năng của Confluent Platform như Schema Registry, giúp nâng cao khả năng kiểm soát, an toàn dữ liệu, tối ưu hiệu suất.
Điểm mạnh của Confluent Kafka Python nằm ở khả năng xử lý hiệu quả, phù hợp với các hệ thống yêu cầu độ trễ thấp, dung lượng lớn và có tính mở rộng cao. Tuy nhiên, code của thư viện này thường nhiều hơn, cần cấu hình phức tạp và xử lý lỗi kỹ lưỡng hơn so với các thư viện thuần Python. Phù hợp cho các dự án doanh nghiệp hoặc các hệ thống sản xuất đòi hỏi độ ổn định cao.

Confluent Kafka là phiên bản thương mại, nâng cao của Apache Kafka
Kafka-python
Dù ra đời đã lâu và ít cập nhật hơn so với các thư viện mới, kafka-python vẫn giữ vững vị trí là thư viện Kafka Python phổ biến vì tính đơn giản, dễ hiểu, sở hữu tính tương thích cao. Thư viện này được viết hoàn toàn bằng Python, không cần cài đặt thêm thư viện phụ trợ, phù hợp với các dự án nhỏ, dự án cá nhân hay các quick-start nhanh.
Với kafka-python, bạn có thể dễ dàng thiết lập producer, consumer để gửi nhận message, quản lý topic, làm việc đồng bộ hoặc bất đồng bộ mà không quá rườm rà. Tuy nhiên, do viết bằng Python thuần, hiệu suất có thể thấp hơn một chút so với Confluent Kafka Python hoặc Quix Streams.
Quix Streams
Quix Streams là một thư viện mã nguồn mở chạy trên nền tảng đám mây, mang sức mạnh của hệ thống phân tán nhưng gói gọn lại trong một thư viện nhẹ, dễ dùng. Nhờ đó, bạn có thể xây dựng và xử lý pipeline dữ liệu real-time mà không cần quá nhiều thiết lập phức tạp nhưng vẫn giữ được hiệu năng và độ ổn định cần thiết.
Điểm nổi bật của Quix Streams là khả năng chuyển đổi dữ liệu sang dạng Streaming DataFrame. Nhà phát triển có thể dễ dàng thực hiện các phân tích, trực quan dữ liệu do đó phù hợp với các dự án công nghiệp, hệ thống xử lý stream phức tạp.
Chuẩn bị môi trường test nhanh để triển khai đúng
Như mọi dự án phần mềm, bắt đầu từ môi trường thử nghiệm nhanh để kiểm tra các tính năng của thư viện Kafka Python là bước không thể bỏ qua. Đặc biệt, trong quá trình lựa chọn thư viện phù hợp, việc có thể dễ dàng thiết lập, chạy thử và kiểm soát tính năng là yếu tố quyết định.
Trước tiên, bạn cần đảm bảo môi trường phát triển đã cài đặt Python, các thư viện liên quan và Kafka broker phù hợp. Các bước đơn giản như cài đặt Docker để chạy Kafka container hoặc dùng Kafka đang chạy sẵn trên hệ thống giúp tối ưu hóa thời gian. Tiếp theo, cài đặt thư viện mong muốn qua pip.
Bên cạnh đó, khởi tạo các topic thử nghiệm, tạo dữ liệu mẫu để gửi và nhận. Từ đó bạn sẽ có cái nhìn rõ hơn về cách thư viện hoạt động, hiệu suất và khả năng mở rộng để ra quyết định chính xác cho dự án của mình.
Triển khai đúng cách với Producer trong Python
Trong bất kỳ hệ thống stream nào, producer đóng vai trò gửi dữ liệu tới Kafka để các hệ thống khác tiếp nhận và xử lý. Việc triển khai đúng cách sẽ giúp đảm bảo dữ liệu được gửi chính xác, độ trễ thấp và dự phòng phù hợp.
Một trong những yếu tố quan trọng là cấu hình producer, bao gồm các tham số như broker list, serializer, retry policy, và timeout. Với Confluent Kafka Python, bạn cần chú ý phần cấu hình librdkafka, còn kafka-python thì dễ hơn với các tham số đơn giản hơn. Quix Streams cung cấp cú pháp khai báo rõ ràng, giúp code trở nên ngắn gọn, dễ hiểu hơn.
Ngoài ra, xử lý lỗi khi gửi message là phần không thể thiếu để đảm bảo hệ thống bền vững. Các app nên có cơ chế retries, logging rõ ràng, và xử lý tình huống ngoại lệ phù hợp. Hiểu rõ các yếu tố này sẽ giúp bạn không chỉ gửi thành công message mà còn xây dựng hệ thống sẵn sàng cho các tình huống bất ngờ.
Chuẩn hóa dữ liệu message để tránh lỗi về sau
Dữ liệu gửi qua Kafka thường rất đa dạng từ: JSON, Protobuf, Avro cho đến các định dạng tự thiết kế. Tuy nhiên, nếu được chuẩn hóa ngay từ đầu khả năng lỗi sẽ giảm đáng kể, lúc này bạn có thể vận hành hệ thống ổn định, dễ mở rộng hơn.
Một cách làm hiệu quả là sử dụng schema (ví dụ như Schema Registry) để đảm bảo dữ liệu luôn nhất quán. Với thư viện Confluent Kafka Python, việc tích hợp và quản lý schema khá thuận tiện. Còn nếu dùng kafka-python, bạn vẫn có thể tự quản lý schema hoặc kết hợp thêm các thư viện hỗ trợ.
Bên cạnh đó bạn cũng nên thực hiện các bước kiểm tra và xác thực dữ liệu ngay từ phía producer để tránh gửi đi những message sai hoặc thiếu thông tin quan trọng. Việc tách rõ các bước như chuyển đổi dữ liệu, encode/decode và validate cũng là một cách đơn giản nhưng rất hiệu quả để hạn chế lỗi, đặc biệt khi hệ thống ngày càng mở rộng.
7 lỗi thường gặp khi triển khai Kafka Python
Dưới đây là 7 lỗi phổ biến khi các nhà phát triển bắt đầu làm việc với Kafka Python:
- Lỗi cấu hình broker sai: Không đúng địa chỉ hoặc port dẫn đến kết nối thất bại hoặc không thể gửi nhận message.
- Thiếu hoặc sai schema: Gửi dữ liệu không tuân theo schema thống nhất gây lỗi hoặc mất dữ liệu.
- Xử lý ngoại lệ không phù hợp: Quên xử lý retries hoặc log lỗi dẫn đến mất message hoặc hệ thống dừng đột ngột.
- Chạy nhiều producer/consumer không đúng cách: Không quản lý concurrency hoặc không tắt đúng khi hệ thống dừng lại gây rò rỉ resource.
- Hiệu suất thấp: Sử dụng cấu hình chưa tối ưu, nhất là buffer, batch, hoặc không dùng librdkafka (đối với các thư viện dựa trên C).
- Không kiểm soát offset đúng cách: Offset không được commit đúng cách, gây duplicate hoặc mất dữ liệu.
- Không xử lý dữ liệu sai định dạng: Nhập dữ liệu không đúng cấu trúc hoặc encoding sai dẫn đến lỗi runtime.
Chìa khóa để tránh những lỗi này nằm ở việc hiểu rõ API, cấu hình đúng, và xây dựng quy trình xử lý lỗi rõ ràng, kiểm thử kỹ lưỡng.
Kết luận
Chọn đúng thư viện Kafka Python không chỉ giúp tối ưu hiệu suất, giảm thiểu lỗi mà còn phát huy tối đa khả năng của hệ thống stream dữ liệu. Dù bạn chọn Confluent Kafka Python, kafka-python hay Quix Streams thì điều quan trọng nhất vẫn là hiểu rõ tính năng, ưu nhược điểm và áp dụng đúng cách trong từng tình huống cụ thể.
Hy vọng bài viết này của Bizfly Cloud đã mang lại góc nhìn toàn diện và giúp bạn tự tin hơn khi làm việc với Kafka Python trong các ứng dụng của mình.