Kafka Consumer Group là gì? Cách hoạt động & tối ưu rebalance

Consumer group là một trong những tính năng mạnh mẽ nhất của Apache Kafka trong việc xây dựng các ứng dụng streaming có thể mở rộng. Hiểu rõ về consumer group sẽ giúp chúng ta có thể thiết kế các kiến trúc truyền dữ liệu hiệu quả và có khả năng chịu lỗi.
Bài viết này Bizfly Cloud sẽ giải thích chi tiết về consumer group là gì, cách chúng hoạt động và cách sử dụng chúng hiệu quả trong môi trường production.
Kafka Consumer Group là gì?
Consumer group là một tập hợp các consumer hoạt động cùng nhau để xử lý message từ một hoặc nhiều Kafka topic. Mỗi người consumer trong group sẽ được chỉ định một tập con các partition của topic, đảm bảo rằng sẽ không có hai consumer bất kỳ trong cùng một group đọc từ cùng một partition cùng một lúc.
Consumer Group hoạt động như thế nào trong Kafka?
Lợi ích chính ở đây là khả năng xử lý song song. Thay vì một consumer duy nhất đọc tất cả các message theo trình tự, nhiều consumer có thể đồng thời xử lý các partition khác nhau. Cách này giúp thực hiện việc mở rộng theo chiều ngang, thêm nhiều consumer hơn để xử lý throughput tăng lên.
Kafka theo dõi các message mà mỗi consumer group đã xử lý bằng cách lưu trữ các offset trong một topic nội bộ đặc biệt có tên là __consumer_offsets. Chúng ta có thể liên tưởng việc này với một sổ ghi chép: "Consume group A đã xử lý các message đến offset 1000 trên partition 0." Vì vậy, trong trường hợp restart hoặc gặp sự cố consumer sẽ tiếp tục đọc từ đúng vị trí trước đó.
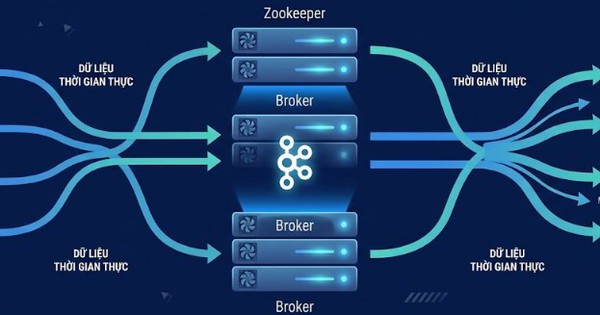
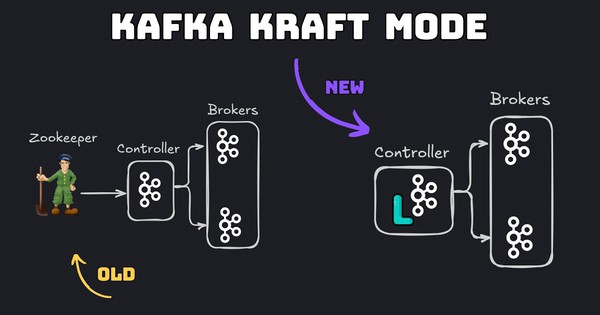
Khi sử dụng Kafka từ 4.0 trở lên với chế độ KRaft (phiên bản kế nhiệm của ZooKeeper), chức năng điều phối group sẽ do các dedicated controller node xử lý. Từ đó giúp cải thiện khả năng mở rộng và giảm độ phức tạp vận hành so với phương thức điều phối sử dụng ZooKeeper truyền thống.
Cơ chế gán partition trong Consumer Group
Việc gán sẽ chỉ định các partition tương ứng với consumer. Mỗi partition được gán cho chính xác một consumer trong một group, nhưng một consumer có thể xử lý nhiều consumer.

Cơ chế gán partition trong Consumer Group là quy trình phân bổ các partition của topic
Bốn chiến lược gán (assignment) có sẵn
Chiến lược | Cách cân bằng | Sticky | Cooperative | Phù hợp với |
RangeAssignor | Theo từng topic | Không | Không | Một topic, hệ thống đơn giản |
RoundRobinAssignor | Global | Không | Không | Nhiều topic, khởi động mới |
StickyAssignor | Global | Có | Không | Giảm thiểu ảnh hưởng khi rebalance |
Cooperative StickyAssignor | Global | Có | Có | Production, downtime = 0 |
Consumer Group hay gặp lỗi do đâu?
Bão cân bằng lại
Việc cấu hình sai session timeout có thể gây ra lỗi dây chuyền. Nếu việc xử lý một message mất nhiều thời gian hơn session timeout, consumer sẽ bị ngắt kết nối, kích hoạt quá trình cân bằng lại - rebalancing. Khi kết nối lại, chu kỳ sẽ lại lặp lại, và tạo ra một "rebalancing storm".
Hãy đặt `session.timeout.ms` cao hơn thời gian xử lý tối đa mà bạn dự kiến, hoặc xử lý message bất đồng bộ. Sử dụng `max.poll.interval.ms` để kiểm soát việc consumer có thể dành bao nhiên thời gian trong các processing loop. Cân nhắc sử dụng tư cách static membership (`group.instance.id`) để giảm độ nhạy cảm với việc cân bằng lại trong quá trình restart.
Độ lệch phân vùng
Việc phân bổ dữ liệu không đồng đều giữa các partition có thể khiến một số consumer không hoạt động trong khi những consumer khác bị quá tải. Hãy sử dụng các partition key để phân tải đồng đều. Theo dõi các chỉ số trên mỗi partition để xác định sự mất cân bằng.
Quản lý bù trừ
Kafka cung cấp tính năng tự động commit offset, nhưng điều này có thể dẫn đến mất mát hoặc trùng lặp message trong các tình huống lỗi. Để đảm bảo xử lý một lần chính xác (EOS), hãy cấu hình consumer với isolation.level=read_committed để chỉ đọc các message đã được commit trong transaction. Kết hợp với idempotent producern (enable.idempotence=true) và transactional producer để đạt được quá trình xử lý dữ liệu end-to-end đúng một lần duy nhất.
Giới hạn mở rộng
Bạn không thể có số lượng consumer đang hoạt động nhiều hơn số partition trong một consumer group. Hãy lập kế hoạch số lượng partition dựa trên nhu cầu dự kiến về xử lý song song. Việc tạo các topic với quá ít partition sẽ hạn chế khả năng mở rộng trong tương lai.
Kết luận
Kafka Consumer Group là nền tảng quan trọng giúp hệ thống xử lý dữ liệu theo thời gian thực có thể mở rộng, phân tải hiệu quả và đảm bảo khả năng chịu lỗi. Khi hiểu rõ cách hoạt động, cơ chế gán partition và đặc biệt là quá trình rebalance, bạn có thể tối ưu hiệu năng xử lý cũng như hạn chế các rủi ro trong môi trường production.
Trong thực tế, việc triển khai đúng Consumer Group không chỉ dừng ở cấu hình mà còn nằm ở cách thiết kế kiến trúc tổng thể, từ số lượng partition, chiến lược assignment cho đến cách quản lý offset. Nếu được tối ưu đúng cách, Kafka Consumer Group sẽ giúp hệ thống streaming vận hành ổn định, linh hoạt và sẵn sàng mở rộng theo nhu cầu dữ liệu ngày càng tăng.