Kafka truyền dữ liệu realtime: Cách hoạt động và ứng dụng

Trên nền tảng công nghệ hiện đại, Kafka truyền dữ liệu realtime là lựa chọn phổ biến cho doanh nghiệp xử lý dữ liệu tốc độ cao. Bài viết này của Bizfly Cloud sẽ giới thiệu Kafka hoạt động ra sao và các ứng dụng thực tế để bạn hiểu rõ cơ chế vận hành cũng như giá trị mà công nghệ mang lại.
Vì sao Kafka phù hợp cho hệ thống realtime?
Kafka được thiết kế để xử lý dữ liệu theo thời gian thực, nhờ đó phù hợp với những hệ thống cần hiệu quả cao và độ tin cậy mạnh. Một số lý do khiến Kafka thường được xem là lựa chọn hàng đầu cho realtime gồm:

Kafka là nền tảng truyền tải và xử lý sự kiện phân tán hàng đầu
Độ trễ thấp (low latency)
Kafka có khả năng duy trì độ trễ rất thấp giữa khâu truyền và nhận dữ liệu. Nhờ vậy, ứng dụng có thể phản hồi gần như ngay lập tức với các thay đổi mới, điều đặc biệt quan trọng trong tài chính, bán lẻ và giám sát an ninh. Ngoài ra, Kafka có thể xử lý hàng triệu sự kiện mỗi giây mà không làm giảm hiệu suất, giúp đáp ứng tốt các bài toán yêu cầu tốc độ cao.
Khả năng scale theo chiều ngang
Khi khối lượng dữ liệu tăng, hệ thống cần khả năng mở rộng linh hoạt. Kafka cho phép bổ sung thêm broker vào cluster để mở rộng năng lực xử lý mà không kéo theo các vấn đề lớn về hiệu suất.
Cách mở rộng theo chiều ngang này cũng giúp doanh nghiệp tiết kiệm chi phí và giảm rủi ro vì việc thêm broker thường không đòi hỏi thay đổi cấu trúc bên trong của ứng dụng, tạo điều kiện cho hệ thống phát triển ổn định theo thời gian.
Xử lý dữ liệu liên tục (streaming)
Kafka hỗ trợ xử lý dữ liệu theo dòng chảy, tức là có thể gửi/nhận dữ liệu đồng thời thực hiện phân tích và xử lý ngay khi dữ liệu được tạo ra. Nhờ khả năng kết hợp với nhiều công cụ khác nhau, Kafka giúp tạo ra các góc nhìn từ dữ liệu theo thời gian thực, hỗ trợ ra quyết định nhanh trong bối cảnh cạnh tranh.
Độ bền dữ liệu (durability & replication)
Kafka chú trọng lưu trữ và sao lưu để dữ liệu luôn sẵn sàng khi có sự cố. Dữ liệu được lưu một cách an toàn và có thể được khôi phục thuận lợi. Cơ chế sao chép giúp dữ liệu được bảo vệ tốt hơn và tồn tại ở nhiều vị trí, từ đó tăng độ tin cậy cho các hệ thống quan trọng triển khai trên Kafka.
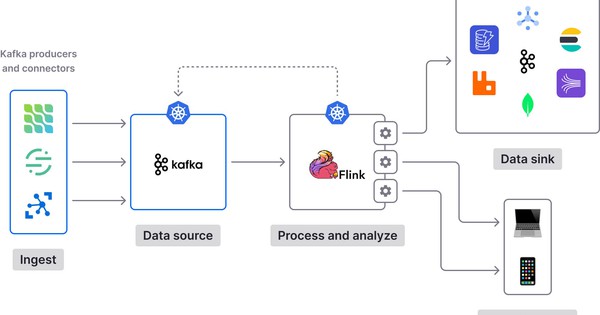
Kiến trúc Kafka trong hệ thống realtime
Kiến trúc của Kafka được ghép từ nhiều thành phần cốt lõi. Mỗi phần đảm nhiệm một nhiệm vụ riêng, cùng phối hợp để dữ liệu được đưa vào, lưu trữ, truyền tải và xử lý theo thời gian gần như thực.

Nó hoạt động như một hệ thống giúp các dịch vụ trong hệ thống thu thập, truyền tải và xử lý
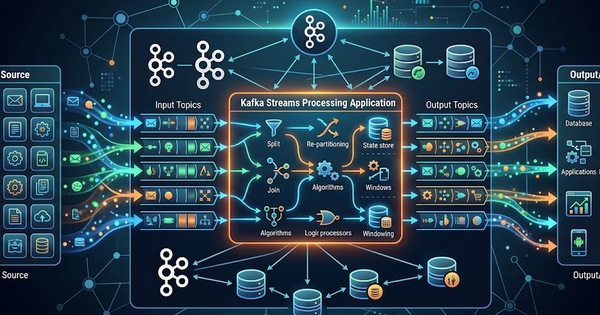
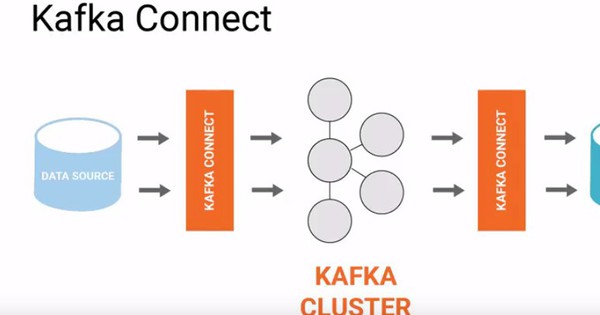
Producer (nguồn dữ liệu)
Producer là nơi phát sinh và gửi dữ liệu vào Kafka. Chúng được thiết kế theo hướng linh hoạt, dễ cấu hình và mở rộng khi nhu cầu tăng lên. Producer có thể ghi một khối lượng dữ liệu lớn vào một hoặc nhiều topic cùng lúc, nhờ đó dữ liệu được cập nhật nhanh, giảm nguy cơ phát sinh độ trễ.
Tùy theo cách thiết kế, producer có thể gửi dữ liệu vào nhiều topic khác nhau và sử dụng key để định tuyến luồng dữ liệu vào các partition phù hợp. Cách làm này giúp tối ưu cho cả việc lưu trữ lẫn khả năng xử lý tiếp theo.
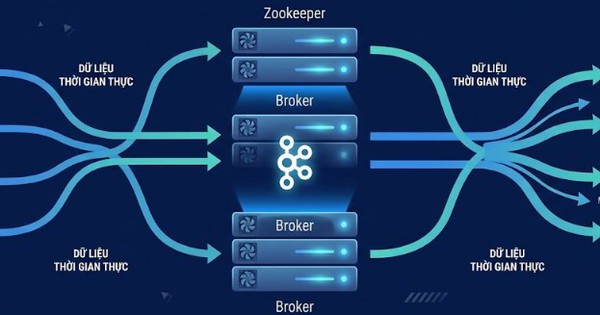
Broker (trung tâm xử lý)
Broker là các máy chủ Kafka chịu trách nhiệm lưu trữ dữ liệu và xử lý các yêu cầu từ producer và consumer. Mỗi broker lưu một phần dữ liệu; khi consumer cần đọc, broker sẽ cung cấp dữ liệu một cách nhanh chóng.
Điểm mạnh của Kafka nằm ở việc nhiều broker có thể hoạt động song song, tạo điều kiện cho hệ thống mở rộng theo chiều ngang và tăng tốc độ xử lý tổng thể.
Topic và Partition (chia nhỏ dữ liệu)
Topic là nơi dữ liệu được trao đổi giữa producer và consumer. Trong một topic, dữ liệu có thể được chia thành nhiều partition - các khối dữ liệu nhỏ, độc lập.
Việc tách topic thành các partition giúp phân bổ tải hiệu quả và tạo nền tảng cho xử lý song song: nhiều consumer có thể làm việc đồng thời trên các partition khác nhau. Nhờ đó, tốc độ xử lý tăng lên và hệ thống vận hành ổn định hơn khi có nhiều sự kiện diễn ra liên tục.
Ngoài ra, topic và partition còn giúp bạn kiểm soát luồng dữ liệu tốt hơn, phản hồi nhanh trước các thay đổi trong thực tế.
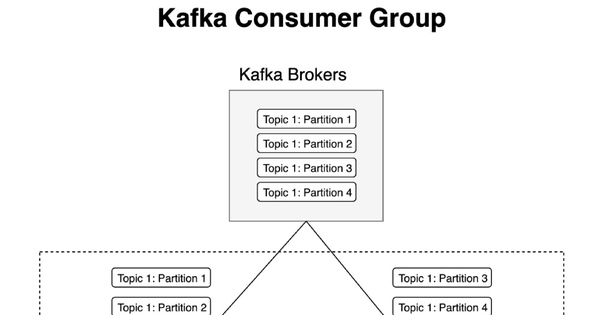
Consumer Group (xử lý song song)
Trong Kafka, consumer group là tập hợp nhiều consumer cùng chia sẻ công việc. Một consumer group có thể đọc và xử lý các partition của cùng một topic theo hướng song song, linh hoạt và hiệu quả.
Khi một consumer trong nhóm đang đọc một partition cụ thể, các consumer khác trong nhóm sẽ không đọc trùng partition đó. Nhờ cơ chế phân công này, dữ liệu được xử lý có trật tự, hạn chế rủi ro trùng lặp hoặc thất thoát trong quá trình vận hành.
Cách tổ chức theo consumer group cũng hỗ trợ mở rộng: khi số lượng truy cập/nhu cầu tăng, bạn có thể tăng số consumer để xử lý nhanh hơn.
Offset và đảm bảo dữ liệu
Offset là chỉ số duy nhất đánh dấu vị trí của từng bản ghi trong topic, theo từng partition. Offset giúp consumer xác định chính xác “điểm đang đứng” và tiếp tục đọc đúng từ vị trí cần thiết.
Đây là yếu tố quan trọng trong hệ thống realtime vì nó đảm bảo consumer theo dõi được những bản ghi đã xử lý và những bản ghi còn lại. Khi consumer xử lý thành công một bản ghi, hệ thống sẽ ghi nhận (commit) offset tương ứng để đánh dấu rằng dữ liệu đó đã được xử lý.
Nhờ cơ chế offset, Kafka giúp hạn chế tình trạng mất dữ liệu hoặc làm rối trình tự xử lý, từ đó duy trì độ chính xác, đặc biệt trong môi trường có hàng triệu sự kiện phát sinh mỗi giây.
Kafka hoạt động như thế nào trong realtime?
Trong môi trường realtime, khi dữ liệu được sinh ra từ một nguồn (ứng dụng, cảm biến, hệ thống tác nghiệp…), producer sẽ đẩy dữ liệu vào một topic trong Kafka.
Các bản ghi trong topic sau đó được chia thành nhiều partition và lưu trên các broker khác nhau. Việc phân tách này giúp Kafka vừa tăng khả năng xử lý song song, vừa phân phối tải tốt hơn khi lượng sự kiện lớn.
Khi consumer cần đọc dữ liệu, nó sẽ kết nối tới broker và lấy dữ liệu từ topic tương ứng. Để biết đã xử lý tới đâu và xử lý đúng luồng dữ liệu, consumer sẽ theo dõi vị trí bằng offset.
Có thể hình dung Kafka giống như một hệ thống đường ray: dữ liệu như các chuyến tàu có thể chạy “trơn tru” từ điểm phát (producer) đến điểm nhận (consumer), nhờ vậy giảm độ trễ trong quá trình truyền tải và truy xuất.
Kafka giải quyết bài toán gì trong thực tế?
Trong thực tế, Kafka giải quyết hàng loạt bài toán khác nhau cho các lĩnh vực từ tài chính cho đến thương mại điện tử.
Một trong những ứng dụng nổi bật là xử lý giao dịch tài chính trong thời gian thực, nơi mỗi giao dịch có thể có giá trị không tưởng và yêu cầu xử lý nhanh chóng để đảm bảo an toàn và hiệu quả.
Ngoài ra, Kafka còn thích hợp cho các ứng dụng giám sát hạ tầng, phân tích dữ liệu lớn, hay thậm chí truyền tải hệ thống cảnh báo trong các tổ chức.
Với khả năng xử lý khối lượng lớn dữ liệu một cách nhanh chóng, Kafka là một công cụ mạnh mẽ giúp các doanh nghiệp nhận diện cơ hội, giảm thiểu rủi ro và tối ưu hóa quy trình kinh doanh.
Hiện nay Kafka trở thành một lựa chọn đáng chú ý khi cần truyền và xử lý dữ liệu realtime. Nhờ các lợi thế như độ trễ thấp, khả năng mở rộng linh hoạt và cơ chế lưu trữ bền vững, Kafka giúp hệ thống vận hành nhanh hơn và xử lý dữ liệu hiệu quả hơn trong nhiều tình huống thực tế.
Vì vậy, nắm được Kafka hoạt động ra sao cũng như cách ứng dụng vào dự án sẽ có ích không chỉ cho lập trình viên và kỹ sư, mà cả nhà quản lý lẫn người ra quyết định khi xây dựng hướng đi công nghệ.