KafkaJS: Hướng dẫn Producer/Consumer Node.js chuẩn

Với người dùng có nhu cầu build một data pipeline thời gian thực hay một hệ thống event-driven có thể mở rộng, thì việc thành thạo KafkaJS là rất quan trọng. Bởi bạn sẽ có thể tích hợp Kafka hiệu quả vào các dự án Node.js của mình.
Kiến trúc module cùng với cộng đồng hỗ trợ mạnh mẽ giúp công cụ trở thành một lựa chọn hấp dẫn, từ người mới bắt đầu, cho đến các developer giàu kinh nghiệm.
KafkaJS là gì?

KafkaJS là một thư viện Node.js được viết hoàn toàn bằng JavaScript
KafkaJS là 1 client Kafka được thiết kế đặc biệt cho môi trường Nodejs, do đó sử dụng hoàn toàn Javascript. Bạn sẽ có đầy đủ các tính năng cần thiết để kết nối, gửi và nhận dữ liệu từ Kafka vào môi trường Node.js một cách hiệu quả và dễ dàng. Sở hữu kiến trúc tối giản nhưng mạnh mẽ, KafkaJS giúp lập trình viên JavaScript tích hợp Kafka vào ứng dụng một cách nhanh chóng, trong khi đó không cần học thêm ngôn ngữ khác hay thao tác cấu hình phức tạp.
Điểm mạnh lớn nhất của KafkaJS nằm ở khả năng tối ưu hiệu năng và scale up, do đó phù hợp với các ứng dụng xử lý dữ liệu thời gian thực ở quy mô lớn. Ngoài ra, thư viện còn tích hợp sẵn các tính năng quản lý Kafka như: quản lý topic, consumer groups, xử lý lỗi (error handling). Nhờ vậy, developer không cần phụ thuộc quá nhiều vào công cụ bên ngoài để vận hành hệ thống.
Tóm lại, KafkaJS là một lựa chọn rất phù hợp cho các lập trình viên Node.js đang tìm kiếm một giải pháp Kafka dễ dùng, hiện đại và có khả năng scale tốt cho dự án của mình.
Kiến thức Kafka tối thiểu để dùng KafkaJS đúng cách
Để sử dụng KafkaJS sao cho đúng và hiệu quả, chúng ta sẽ cần hiểu một số khái niệm cốt lõi của Apache Kafka:
Các thành phần cơ bản của Kafka bao gồm:
- Producer với vai trò gửi message vào Kafka
- Consumer để đọc và xử lý message
- Topic là nơi message được lưu trữ
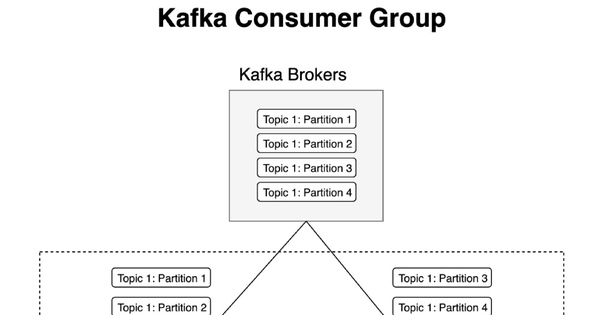
- Partition chia nhỏ topic để scale và phân phối tải
- Consumer Group - nhóm consumer cùng xử lý dữ liệu song song
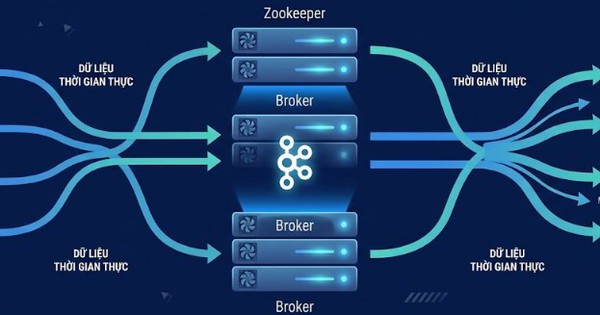
Kafka hoạt động theo mô hình phân tán (distributed), nên công cụ có thể xử lý dữ liệu real-time, phân tải qua nhiều partition, replication giúp đảm bảo độ tin cậy. Hiểu cách dữ liệu được phân phối và cách Kafka quản lý trạng thái consumer (offset) là nền tảng quan trọng khi làm việc với KafkaJS.
Bạn cũng cần hiểu rõ các cơ chế giao tiếp như:
- At-most-once: Có thể mất dữ liệu nhưng không bị xử lý trùng
- At-least-once: Không mất dữ liệu nhưng có thể xử lý trùng
- Exactly-once: Đảm bảo mỗi message chỉ được xử lý đúng một lần
Việc chọn đúng mô hình sẽ giúp bạn tối ưu workflow xử lý và đảm bảo tính toàn vẹn dữ liệu.
Thêm vào đó, trang bị các kiến thức nâng cao hơn như offset management (quản lý vị trí đọc message), cấu hình Kafka (replication, partitioning, batching…), Error handling (retry, DLQ, backoff…) sẽ giúp bạn tận dụng KafkaJS tốt hơn. Từ đó bạn có thể tùy biến hệ thống, scale ứng dụng hoặc xử lý các pipeline dữ liệu phức tạp tự tin hơn, chuẩn xác hơn.
Chuẩn bị môi trường trước khi code
Trước khi bắt đầu làm việc với KafkaJS bạn sẽ cần cài đặt Kafka và Zookeeper. Để setup nhanh và gọn, chúng ta có thể sử dụng Docker images hoặc cài trực tiếp trên server. Sau đó, chúng ta kiểm tra lại trạng thái của Kafka và Zookeeper để đảm bảo hệ thống đã sẵn sàng.
Tiếp theo, chúng ta thiết lập môi trường Node.js với các thư viện cần thiết, đặc biệt là KafkaJS. Đầu tiên, tạo thư mục project mới, khởi tạo project với lệnh: npm init. Cài đặt KafkaJS với npm install kafkajs.
Đừng quên việc cấu hình các cấu hình quan trọng như brokers, topics, và security parameters (nếu có). Bạn có thể lưu các cấu hình này trong environment variables để dễ quản lý và tái sử dụng.
Cài đặt KafkaJS và khởi tạo client đúng chuẩn
Cấu hình và cài đặt đúng sẽ giúp việc dev một ứng dụng Kafka hiệu quả. Sau khi đã cài đặt KafkaJS, chúng ta sẽ cùng cài đặt Kafka instance phù hợp với cấu hình môi trường (brokers, clientId, security…).
Cùng xem một ví dụ đơn giản để khởi tạo client như sau:
const = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092'],
});
Trong ví dụ trên, cấu hình sẽ đảm bảo client có thể kết nối chính xác đến kafka broker, và từ instance bạn sẽ tạo được producer hoặc consumer. Với cách tổ chức code rõ ràng và có khả năng tái sử dụng như thế này, bạn có thể đảm bảo khả năng bảo trì trong thời gian dài, ít gặp lỗi liên quan đến cấu hình sai hoặc kết nối không thành công.
Viết Producer với KafkaJS
Producer là thành phần chịu trách nhiệm gửi dữ liệu tới Kafka. Để tạo một producer theo chuẩn, chúng ta sẽ cần khởi tạo một producer từ Kafka client, thiết lập kết nối, và gửi các message tới topic mong muốn. Cùng xem một ví dụ:
const producer = kafka.producer();
await producer.connect();
await producer.send({
topic: 'example-topic',
messages: [
,
],
});
await producer.disconnect();
Trên thực tế, việc truyền dữ liệu sẽ yêu cầu phải sửa lỗi hoặc xác định các tham số truyền phù hợp như kích thước batch và thời gian chờ (linger time). Với cách xử lý này chúng ta có thể đảm bảo rằng dữ liệu có thể được truyền 1 cách hiệu quả, chính xác, góp phần tăng hiệu năng cho ứng dụng.
Viết Consumer với KafkaJS
Consumer sẽ lắng nghe và xử lý các message nhận được từ Kafka. Khi bạn triển khai với KafkaJS, công việc khá đơn giản, tuy nhiên sẽ cần đặc biệt chú ý đến việc quản lý offset, xử lý lỗi và khả năng mở rộng. Dưới đây là một ví dụ về cách thiết lập một consumer.
const consumer = kafka.consumer();
await consumer.connect();
await consumer.subscribe();
await consumer.run({
eachMessage: async () => {
console.log({
key: message.key.toString(),
value: message.value.toString(),
});
},
});
Để triển khai tối ưu, chúng ta sẽ cần quan tâm đến quản lý consumer groups, xử lý lỗi. Kết hợp với tận dụng các tùy chọn như commit offset (tự động hoặc thủ công) để tối ưu việc xử lý dữ liệu và đảm bảo tính toàn vẹn của hệ thống.
KafkaJS Admin – Quản trị topic, partition, consumer group cơ bản
Các chức năng quản lý trong KafkaJS cho phép bạn tạo, xóa và theo dõi các topic, partition và consumer group. Đây là một khía cạnh rất quan trọng giúp duy trì và tối ưu hệ thống của Khi bạn chạy Kafka trong môi trường production thì đây là một yếu tố rất quan trọng trong việc duy trì độ ổn định và hiệu quả hoạt động hệ thống. Một ví dụ như sau:
const admin = kafka.admin();
await admin.connect();
await admin.createTopics({
topics: [],
});
await admin.disconnect();
Khi bạn đã hiểu rõ các command để quản trị các thành phần này, bạn sẽ có thể quản lý hệ thống hiệu quả hơn, dễ dàng thích ứng với các yêu cầu mới, cũng như cải thiện và tối ưu việc truyền dữ liệu. Với việc tận dụng các tính năng này, bạn sẽ giảm thiểu downtime và tránh xung đột dữ liệu tốt hơn, đặc biệt trong môi trường doanh nghiệp.
Cấu hình nâng cao cho production
Trong môi trường production, việc đặt cấu hình mặc định có thể sẽ không đủ để đảm bảo quản lý khối lượng dữ liệu lớn hoặc đảm bảo độ tin cậy cao. Do đó, chúng ta sẽ cần tùy chỉnh bổ sung, ví dụ tăng cài đặt timeout, số lần thử lại, buffer size hoặc bật mode phân tán và đảm bảo phân phối cho từng segment. Ví dụ:
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['prod-broker-1:9092', 'prod-broker-2:9092'],
connectionTimeout: 3000,
requestTimeout: 25000,
retry: {
retries: 5,
},
});
Các cấu hình này đảm bảo tính ổn định của hệ thống và tạo điều kiện thuận lợi cho việc phục hồi trong trường hợp xảy ra lỗi mạng hoặc mất kết nối với broker. Quan trọng là chúng ta cần liên tục kiểm tra, test và đánh giá hiệu năng trong môi trường testing trước khi chuyển sang môi trường production.
Monitoring & Observability cho KafkaJS

Monitoring và Observability cho KafkaJS là yếu tố then chốt để đảm bảo độ tin cậy của Node.js
Mục tiêu của việc giám sát là đảm bảo hoạt động liên tục và phát hiện sớm các sự cố. Các công cụ như Prometheus, Grafana hoặc các plugin Kafka rất hữu ích trong việc thu thập các thông số như số liệu, trạng thái, latency và lỗi hệ thống. Khi sử dụng kafkajs, bạn có thể tích hợp middleware hoặc phát triển các command riêng để thu thập số liệu.
Thêm vào đó, việc ghi log và cảnh báo rõ ràng về lỗi hoặc trạng thái bất thường sẽ giúp chúng ta chủ động hơn trong việc giải quyết vấn đề. Phương pháp xử lý này sẽ rất hữu ích khi ứng dụng cần đảm bảo hoạt động 24/7 nhờ giảm thiểu downtime và nâng cao trải nghiệm khách hàng.
KafkaJS vs node-rdkafka vs kafka-node: nên chọn gì?
Khi nói đến các thư viện Kafka dành cho Node.js, kafkajs nổi bật nhờ tính dễ sử dụng, hiệu suất cao trên nhiều môi trường khác nhau và cộng đồng nhà phát triển mạnh mẽ.
Trong khi đó node-rdkafka sử dụng thư viện C/C++ gốc đem đến hiệu năng vượt trội, lý tưởng cho các hệ thống yêu cầu hiệu quả tối ưu.
Kafka-node là một lựa chọn cũ hơn, ưu điểm dễ cài đặt nhưng thiếu các bản cập nhật và các tính năng mới nhất của Kafka.
Dựa trên đánh giá dự án, performance dự kiến và khả năng mở rộng, kafkajs thường là lựa chọn ưu tiên cho JavaScript, đặc biệt khi tính đơn giản và khả năng mở rộng dễ dàng có vai trò quan trọng trong mô hình phát triển.
Kết luận
Sử dụng kafkajs cho phép bạn khai thác các tính năng mạnh mẽ của Kafka thông qua API trực quan, giúp đơn giản hóa việc quản lý cụm và xử lý message phức tạp. Thiết kế của nó tập trung vào các phương pháp JavaScript hiện đại, cung cấp các API dựa trên promise phù hợp với cú pháp async/await, giúp code sạch hơn và dễ bảo trì hơn. Hơn nữa, kafkajs được xây dựng với hiệu năng cao và khả năng chịu lỗi tốt, đảm bảo các ứng dụng của bạn có thể xử lý khối lượng công việc trơn tru. Khi Kafka tiếp tục phát triển như một cơ sở hạ tầng xương sống cho việc truyền tải dữ liệu, kafkajs cung cấp một con đường đơn giản để tích hợp Kafka một cách hiệu quả vào môi trường Node.js của bạn.
Bạn cũng có thể trải nghiệm Bizfly Cloud Kafka với khả năng đơn giản hóa đến 80% việc vận hành, quản lý và mở rộng cụm Kafka trên đám mây khi phát triển ứng dụng.