Webhook Kafka là gì? Cách tích hợp Webhook với Apache Kafka

Hiện nay việc xử lý dữ liệu theo thời gian thực và đảm bảo tính mở rộng, linh hoạt của hệ thống đang trở thành yếu tố quyết định thành công của các doanh nghiệp. Một trong những giải pháp nổi bật chính là tích hợp Webhook với Apache Kafka. Bài viết này của Bizfly Cloud sẽ giúp bạn hiểu rõ về khái niệm Webhook Kafka, cách kiến trúc hoạt động cũng như hướng dẫn chi tiết từng bước để triển khai hệ thống Webhook Kafka thực tế.
Webhook Kafka là gì?

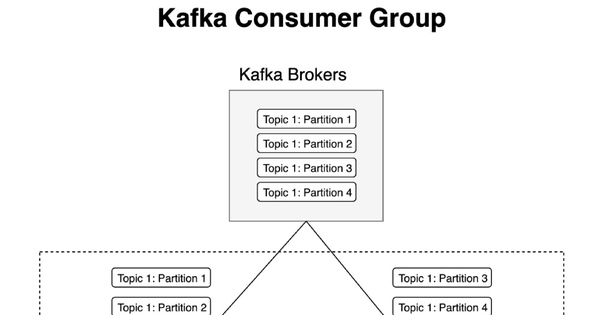
Webhook Kafka là cơ chế tự động gửi dữ liệu thời gian thực từ các chủ đề (topics)
Webhook Kafka là khái niệm kết hợp giữa cơ chế Webhook truyền thống và nền tảng xử lý dữ liệu Kafka nổi tiếng. Trong mô hình này, các sự kiện từ hệ thống bên ngoài hoặc bên trong được gửi về dưới dạng webhook, sau đó dữ liệu này sẽ được chuyển tiếp vào Kafka để xử lý theo kiểu stream data.
Cơ chế này tận dụng khả năng của Kafka trong việc xử lý lượng lớn dữ liệu một cách ổn định và có thể mở rộng linh hoạt. Thay vì xử lý trực tiếp tại điểm gửi webhook hoặc lưu trữ sơ bộ, dữ liệu từ webhook sẽ được đẩy vào Kafka topic, nơi có thể được tiêu thụ từ nhiều consumer khác nhau trong hệ thống. Giúp tăng tính modular, dễ mở rộng và giảm thiểu rủi ro mất dữ liệu khi hệ thống gặp sự cố.
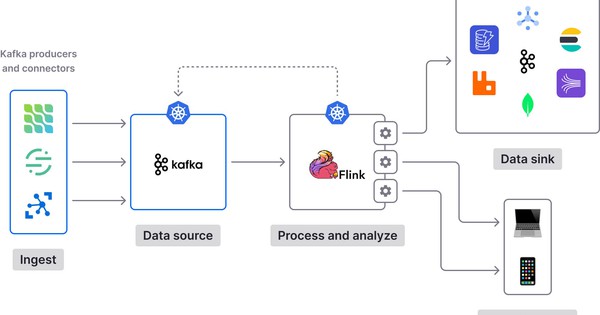
Kiến trúc tích hợp Webhook với Kafka

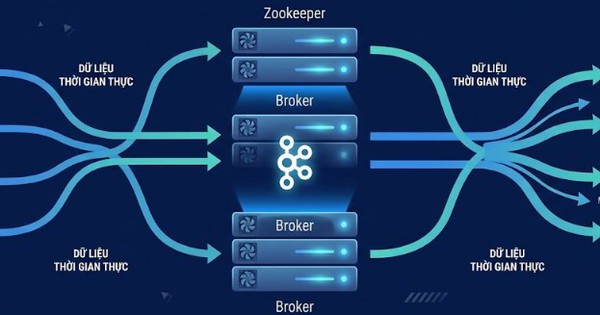
Kiến trúc tích hợp Webhook với Apache Kafka giúp xử lý sự kiện thời gian thực
Một kiến trúc tích hợp Webhook với Kafka không quá phức tạp về mặt tổng thể, nhưng đòi hỏi sự cẩn trọng trong thiết kế để đảm bảo hiệu quả, ổn định và khả năng mở rộng. Các thành phần chính gồm có hệ thống gửi webhook, dịch vụ trung gian xử lý webhook, Kafka broker và các consumer xử lý dữ liệu.
Trong kiến trúc này, hệ thống phía gửi webhook sẽ đẩy dữ liệu về một API gateway hoặc dịch vụ trung gian. Dịch vụ này sẽ xử lý xác thực, xác định loại dữ liệu và sau đó gửi dữ liệu đó tới Kafka producer để đẩy vào các topic phù hợp. Các consumer ở phía dưới sẽ đọc dữ liệu từ Kafka để xử lý theo mục đích kinh doanh hoặc phân tích dữ liệu.
Điểm đặc biệt của kiến trúc này chính là khả năng mở rộng không giới hạn của Kafka, nơi có thể thêm nhiều consumer để phân phối dữ liệu theo nhu cầu. Đồng thời, các dịch vụ trung gian có thể được tối ưu hóa để xử lý lượng webhook lớn, tự động phân luồng và cân bằng tải. Từ đó, hệ thống không chỉ đáp ứng tốt các yêu cầu hiện tại mà còn sẵn sàng mở rộng khi lượng webhook tăng cao.
>> Có thể bạn quan tâm: So sánh Kafka và Redis: Nên chọn công nghệ nào cho hệ thống?
Cách triển khai Webhook Kafka trong thực tế
Bước 1: Nhận webhook từ hệ thống bên ngoài
Hệ thống của bạn cần expose một HTTP endpoint (thường là REST API) để nhận request từ bên thứ ba. Các webhook này thường được gửi dưới dạng HTTP POST kèm payload JSON khi có sự kiện xảy ra.
Ở bước này, nên thực hiện thêm:
- Xác thực request (signature, API key…)
- Validate schema dữ liệu
- Log request để debug khi cần.
Bước 2: Xử lý dữ liệu webhook
Sau khi đã nhận được webhook, bước tiếp theo là xử lý dữ liệu để chuẩn bị gửi vào Kafka. Đây là giai đoạn chuyển đổi, làm sạch và phân loại dữ liệu trước khi đưa vào hệ thống xử lý chính.
Thông thường, dữ liệu từ webhook sẽ cần được xác thực, kiểm tra tính hợp lệ, rồi chuyển sang định dạng phù hợp như JSON hoặc Avro. Ngoài ra, bạn có thể bổ sung các metadata như timestamp, loại sự kiện, hoặc ID duy nhất để dễ dàng theo dõi và phân tích sau này.
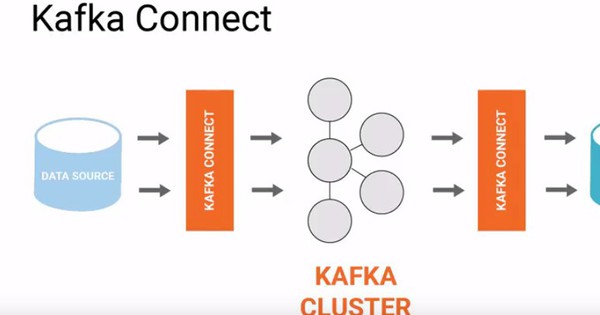
Bước 3: Publish dữ liệu vào Kafka topic
Sau khi xử lý xong, dữ liệu sẽ được gửi tới Kafka thông qua producer. Producer này sẽ đảm nhiệm việc gửi dữ liệu vào các topic phù hợp dựa trên loại webhook hoặc phân loại nội dung.
Trong quá trình này, cần chú ý đến các yếu tố như chọn partition phù hợp để cân bằng tải, đặt các thuộc tính về xác thực, và xử lý các lỗi khi gửi dữ liệu để đảm bảo không bị mất dữ liệu.
Bước 4: Consumer xử lý dữ liệu realtime
Cuối cùng, các consumer trong hệ thống sẽ đăng ký theo dõi các Kafka topic để xử lý dữ liệu theo mục đích riêng.
Các consumer (microservices) sẽ subscribe vào Kafka topic để xử lý dữ liệu theo thời gian thực:
- Ghi dữ liệu vào database
- Trigger workflow (email, notification…)
- Phân tích hoặc stream processing
Nhờ Kafka, nhiều consumer có thể xử lý cùng một luồng dữ liệu mà không ảnh hưởng lẫn nhau, giúp hệ thống mở rộng linh hoạt và chịu tải tốt hơn.
Ưu điểm khi sử dụng Kafka để xử lý Webhook
Xử lý dữ liệu realtime
Một trong những lợi ích lớn nhất của việc tích hợp Webhook với Kafka chính là khả năng xử lý dữ liệu theo thời gian thực. Kafka cung cấp khả năng đọc và ghi dữ liệu cực kỳ nhanh chóng, phù hợp với các yêu cầu xử lý sự kiện liên tục, như cập nhật trạng thái đơn hàng, giám sát hoạt động hệ thống, hay phân tích hành vi người dùng.
Hệ thống sử dụng Kafka không cần phải chờ đợi batch hoặc xử lý theo lịch trình, mà mọi dữ liệu đều có thể được tiêu thụ và phân tích ngay khi mới phát sinh. Giúp giảm thiểu độ trễ, nâng cao trải nghiệm khách hàng và tối ưu hóa hoạt động kinh doanh.
Khả năng mở rộng cao
Kafka nổi tiếng với khả năng mở rộng linh hoạt, phù hợp với các hệ thống có lượng dữ liệu ngày càng tăng. Khi số lượng webhook tăng đột biến, bạn có thể dễ dàng thêm broker mới, phân chia topic hoặc tối ưu cấu hình để duy trì hiệu suất cao.
Đảm bảo tính ổn định cho hệ thống
Khác với các giải pháp truyền thống dễ gặp rủi ro mất dữ liệu hoặc nghẽn cổ chai, Kafka cung cấp các tính năng như lưu trữ dài hạn, phân phối dữ liệu phân tán, cùng khả năng đảm bảo giao dịch đúng thứ tự và chính xác.
Chính vì vậy, việc tích hợp Webhook với Kafka giúp hệ thống duy trì tính ổn định, giảm thiểu nguy cơ mất dữ liệu do lỗi phần cứng hoặc phần mềm. Các nhà phát triển có thể yên tâm vì dữ liệu luôn được giữ an toàn và có khả năng phục hồi khi gặp sự cố.
Phù hợp với kiến trúc microservices
Trong kiến trúc microservices, mỗi dịch vụ độc lập có thể cần tiêu thụ dữ liệu từ các nguồn khác nhau. Kafka cung cấp một nền tảng trung tâm để các dịch vụ này giao tiếp và trao đổi dữ liệu một cách dễ dàng, không phụ thuộc vào nhau.
Webhooks gửi dữ liệu về Kafka giúp các microservices khởi tạo phản ứng nhanh chóng với các sự kiện mới, đồng thời dễ dàng mở rộng hoặc thay đổi từng dịch vụ mà không ảnh hưởng đến toàn hệ thống.
Bizfly Cloud Kafka – Nền tảng xử lý Webhook realtime ổn định và dễ mở rộng

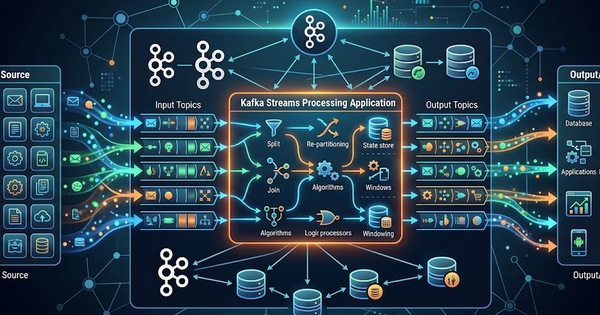
Bizfly Cloud Kafka là nền tảng quản lý Apache Kafka (Kafka-as-a-Service) giúp xử lý webhook
Trong các hệ thống tích hợp Webhook với Kafka, việc lựa chọn hạ tầng phù hợp đóng vai trò then chốt để đảm bảo hiệu suất, độ ổn định và khả năng mở rộng lâu dài. Thay vì tự triển khai và vận hành Kafka với nhiều lớp cấu hình phức tạp, doanh nghiệp có thể sử dụng dịch vụ Bizfly Cloud Kafka để rút ngắn thời gian triển khai và tối ưu chi phí vận hành.
Bizfly Cloud Kafka cung cấp nền tảng streaming dữ liệu theo thời gian thực được quản lý hoàn toàn, hỗ trợ xử lý lượng lớn webhook events một cách ổn định. Hệ thống được thiết kế sẵn với khả năng mở rộng linh hoạt, giúp dễ dàng tăng số lượng broker, partition hoặc consumer khi lưu lượng dữ liệu tăng cao mà không ảnh hưởng đến hoạt động chung.
Ngoài ra, dịch vụ còn tích hợp sẵn các tính năng quan trọng như monitoring, alert, backup dữ liệu và bảo mật, giúp đội ngũ kỹ thuật tập trung vào phát triển logic xử lý thay vì quản lý hạ tầng. Nhờ đó, việc triển khai kiến trúc Webhook Kafka trở nên nhanh chóng, an toàn và phù hợp với các hệ thống microservices hiện đại.
Đối với các doanh nghiệp đang xây dựng hệ thống realtime hoặc cần xử lý event quy mô lớn, việc kết hợp Webhook với Bizfly Cloud Kafka không chỉ giúp tối ưu hiệu năng mà còn đảm bảo hệ thống luôn sẵn sàng mở rộng theo nhu cầu phát triển.
Kết luận
Có thể thấy rằng việc tích hợp Webhook với Apache Kafka đã chứng minh là một giải pháp tối ưu cho các hệ thống cần xử lý dữ liệu theo thời gian thực, có khả năng mở rộng cao và đảm bảo tính ổn định. Hiểu rõ Webhook Kafka giúp các nhà phát triển, kiến trúc sư hệ thống dễ dàng xây dựng các giải pháp linh hoạt, phù hợp với xu hướng hiện đại.
Dữ liệu ngày càng phong phú và phức tạp, việc ứng dụng Kafka để xử lý webhook chính là bước đi chiến lược giúp doanh nghiệp nâng cao khả năng phản ứng nhanh, tối ưu vận hành và thúc đẩy đổi mới sáng tạo.