Tìm hiểu về kiến trúc Kafka hiện đại: Các thành phần, mô hình thực tế, các API & framework

Apache Kafka là một nền tảng truyền dữ liệu phân tán, Kafka được sử dụng để build các đường dẫn dữ liệu thời gian thực và các ứng dụng truyền dữ liệu. Kafka được đánh giá cao với các ưu điểm gồm thông lượng cao, độ trễ thấp, khả năng chịu lỗi và khả năng mở rộng cao. Bài viết này Bizfly Cloud sẽ đi sâu vào kiến trúc của Kafka, khám phá các thành phần cốt lõi, chức năng và sự tương tác giữa các thành phần này.

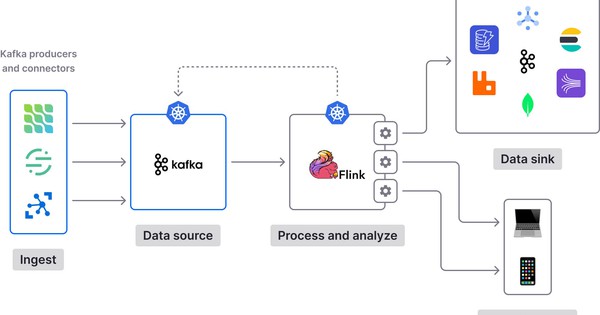
Kiến trúc Kafka là một hệ thống truyền phát sự kiện phân tán
Các mô hình sử dụng Kafka trong thực tế
Apache Kafka là một nền tảng đáp ứng được đa dạng nhu cầu triển khai. Cùng Bizfly Cloud khám phá ba kiến trúc Kafka phổ biến: Hệ thống Pub-Sub/Pub-Sub Systems, Stream Processing Pipelines và Log Aggregation Architectures.
1. Pub-Sub system
Trong hệ thống pub-sub, các publisher sẽ đẩy các message vào các topic và consumer sẽ subscribe các topic đó để nhận message. Kiến trúc của Kafka rất phù hợp với pub-sub system nhờ khả năng xử lý khối lượng dữ liệu lớn và truyền tải tin nhắn ổn định cao.
Các thành phần chính:
- Publishers: Các ứng dụng gửi dữ liệu đến các Kafka topic.
- Topics: Các kênh logic mà publisher gửi dữ liệu đến và consumer đọc dữ liệu từ đó.
- Consumers: Các ứng dụng subscribe các topic và xử lý dữ liệu.
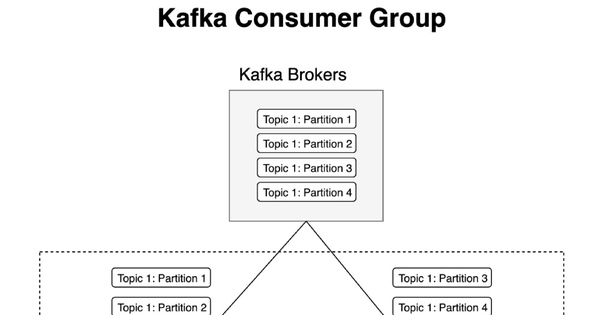
- Consumer Groups: Các nhóm consumer cân tải khi đọc dữ liệu từ các topic.
Một ví dụ thực tế về hệ thống pub-sub sử dụng Kafka có thể kể đến new feed, trong đó nhiều source new (producer) đăng bài viết lên một topic và nhiều user application khác nhau (consumer) subscribe để nhận cập nhật theo thời gian thực.
2. Stream Processing Pipelines
Stream Processing Pipelines sẽ tham gia vào các công việc bao gồm: liên tục thu nhận, xử lý và chuyển đổi dữ liệu trong thời gian thực. Khả năng xử lý luồng high throughput của Kafka, kết hợp với tích hợp với các framework xử lý luồng dữ liệu như Apache Flink và Apache Spark giúp Kafka trở nên lý tưởng để xây dựng các pipeline như vậy.
Các thành phần chính:
- Producers: Các ứng dụng gửi luồng dữ liệu thô đến các topic Kafka.
- Topic: Các channel lưu trữ dữ liệu thô trước khi xử lý.
- Stream Processors: Các ứng dụng hoặc framework tiêu thụ dữ liệu thô, sau đó xử lý và tạo ra dữ liệu đã được chuyển đổi.
- Sink Topics: Các topic để lưu trữ dữ liệu đã xử lý để phục vụ cho các lần sử dụng sau.
3. Kiến trúc tổng hợp log/Log Aggregation
Log Aggregation sẽ xử lý các công việc: thu thập dữ liệu nhật ký từ nhiều nguồn khác nhau, tập trung các dữ liệu về một mối, và sau đo cấp dữ liệu cho phân tích. Độ bền và khả năng mở rộng của Kafka khiến nó trở thành lựa chọn tuyệt vời cho các hệ thống tổng hợp nhật ký.
Các thành phần chính:
- Log Producers: Các ứng dụng hoặc dịch vụ tạo ra dữ liệu log.
- Log Topics: Các topic Kafka nơi lưu trữ dữ liệu log.
- Log Consumers: Các ứng dụng đọc dữ liệu log để phân tích hoặc lưu trữ trong một hệ thống tập trung.
Một ví dụ thực tế về kiến trúc Log Aggregation sử dụng Kafka có thể kể đến ứng dụng microservices, trong đó mỗi microservice tạo ra logs. Các log này được gửi đến các topic Kafka và một hệ thống ghi log tập trung để phân tích và giám sát.
Kiến trúc của Kafka hỗ trợ nhiều ứng dụng thực tế, trong đó có các hệ thống pub-sub, các pipeline xử lý stream và kiến trúc log aggregation. Khả năng xử lý các luồng dữ liệu thông lượng cao, cùng với khả năng chịu lỗi và horizontal scale giúp Kafka trở thành một công cụ mạnh mẽ khi xây dựng các ứng dụng data-driven ổn định và sẵn sàng mở rộng.
Các thành phần cốt lõi trong kiến trúc Kafka
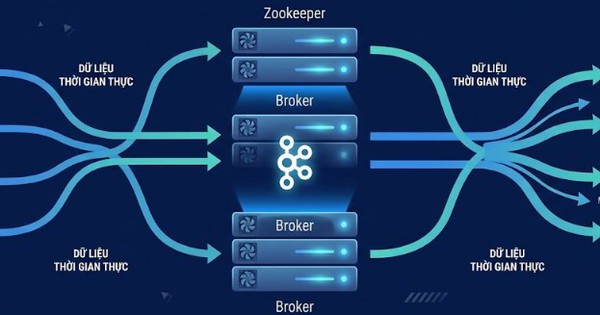
- Kafka cluster: Một hệ thống phân tán gồm nhiều broker Kafka đảm bảo khả năng chịu lỗi, khả năng mở rộng và tính sẵn sàng cao cho việc truyền dữ liệu theo thời gian thực.
- Broker: Các máy chủ Kafka xử lý việc lưu trữ dữ liệu và các hoạt động đọc/ghi, đồng thời quản lý việc sao chép dữ liệu để đảm bảo độ tin cậy.
- Topics & Partitions: Dữ liệu được tổ chức thành các topic (logic channel), được chia thành các phân vùng (partition) để xử lý song song và mở rộng theo chiều ngang.
- Producers: Các ứng dụng khách ghi dữ liệu vào các chủ đề Kafka, phân phối các bản ghi trên các phân vùng.
- Consumers: Các ứng dụng đọc dữ liệu từ các topic; các nhóm consumers cung cấp load balancing và khả năng chịu lỗi.
- ZooKeeper: Quản lý và điều phối các broker Kafka, xử lý cấu hình, đồng bộ hóa và lựa chọn leader.
- Offset: ID duy nhất cho mỗi message trong một partition, được consumer sử dụng để theo dõi tiến trình đọc.

Kiến trúc Apache Kafka gồm 4 thành phần cốt lõi
Các API của Kafka
Kafka cung cấp một số API để tương tác với hệ thống:
- API Producer: Cho phép các ứng dụng gửi các luồng dữ liệu đến các topic trong cụm Kafka. API này xử lý việc tuần tự hóa dữ liệu và logic phân vùng.
- API Consumer: Cho phép các ứng dụng đọc các luồng dữ liệu từ các topic. API quản lý độ lệch của dữ liệu được đọc, đảm bảo rằng mỗi bản ghi chỉ được xử lý đúng một lần.
- API Streams: Một thư viện Java phục vụ xây dựng các ứng dụng xử lý dữ liệu theo thời gian thực, cung cấp khả năng chuyển đổi và tổng hợp data event mạnh mẽ.
- API Connector: Cung cấp một framework để kết nối Kafka với các hệ thống bên ngoài. Các source connector sẽ import dữ liệu từ các hệ thống bên ngoài vào các topic Kafka, trong khi các sink connector sẽ export dữ liệu từ các topic Kafka sang các hệ thống bên ngoài.
Tương tác trong kiến trúc Kafka
- Từ Producers đến Kafka Cluster: Các Producer gửi dữ liệu đến Kafka Cluster. Dữ liệu được publish đến các topic cụ thể, sau đó được chia thành các partition và phân phối trên các broker.
- Từ Kafka Cluster đến Consumers: Consumers đọc dữ liệu từ Kafka Cluster. Chúng subscribe các topic và tiêu thụ dữ liệu từ các partition được chỉ định cho mình. Consumer groups đảm bảo tải được cân bằng và mỗi partition chỉ do một consumer trong nhóm xử lý.
- Từ ZooKeeper đến Kafka Cluster: ZooKeeper điều phối và quản lý Kafka Cluster. Nó theo dõi metadata của cluster, quản lý cấu hình broker và xử lý việc chọn leader cho các partition.
Mối quan hệ giữa các partitions, offsets và consumer groups trong một hệ thống sử dụng Kafka:

Hình ảnh miêu tả mối quan hệ giữa các partitions, offsets và consumer
Partitions: Có 3 partition (Partition 0, 1 và 2), mỗi partition lưu trữ các record với các offset duy nhất (0–6), cho biết vị trí của record.
Consumer groups: Ba consumer, mỗi consumer được gán cho một partition:
- Consumer 1 → Partition 0, bắt đầu từ offset 4
- Consumer 2 → Partition 1, bắt đầu từ offset 2
- Consumer 3 → Partition 2, bắt đầu từ offset 3
Data Flow: Mỗi consumer đọc từ partition được gán cho mình bắt đầu từ offset đã cho, đảm bảo tất cả các record được group xử lý chính xác một lần.
Các Framework của Apache Kafka
Kafka là một nền tảng truyền dữ liệu phân tán có thể được mở rộng và tích hợp với nhiều framework khác nhau để mở rộng khả năng và tích hợp với các hệ thống khác. Một số framework quan trọng trong hệ sinh thái Kafka bao gồm:
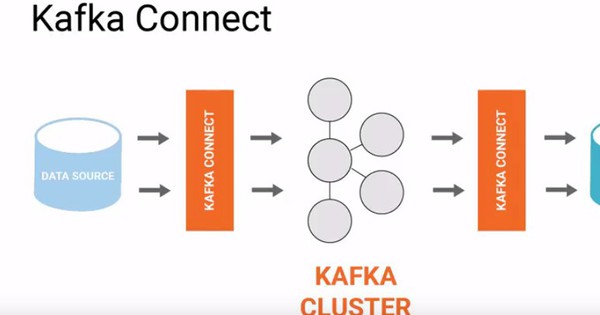
- Kafka Connect: Một công cụ trong hệ sinh thái Kafka cho phép tích hợp dữ liệu giữa Kafka và các hệ thống bên ngoài như database hoặc file system với độ ổn định cao và khả năng mở rộng tốt. Công cụ cung cấp các connector tích hợp sẵn để đơn giản hóa quá trình di chuyển dữ liệu vào và ra khỏi Kafka.
- Kafka Streams: Một client-side library để xây dựng các ứng dụng xử lý và phân tíchdữ liệu trong các topic Kafka. Công cụ cung cấp các API dễ sử dụng cho các tác vụ như lọc, kết hợp và tổng hợp streaming data.

Kafka Streams làMột thư viện máy khách Java nhẹ để xây dựng các ứng dụng xử lý luồng thời gian thực
- Schema Registry (một phần của Confluent Platform) là một dịch vụ tập trung quản lý các lược đồ Avro cho các Kafka message, đảm bảo các producer và consumer sử dụng các định dạng dữ liệu tương thích trong quá trình tuần tự hóa và giải tuần tự hóa.

Một Schema Registry làmột kho lưu trữ tập trung quản lý và lưu trữ lược đồ
Quản lý Topic trong Kafka
Một trong những yếu tố cơ bản khi làm việc với Kafka là quản lý topic. Topic là các danh mục mà các producer gửi record đến và sau đó được các consumer nhận.
1. Tạo Topic
Để tạo một topic trong Kafka, bạn có thể sử dụng tập lệnh kafka-topics.sh, nằm trong Kafka distribution. Sau đây là một ví dụ để tạo một topic Kafka:
./bin/kafka-topics.sh --create --topic topic_name --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 Giải thích câu lệnh:
--create: Được sử dụng để tạo một topic mới.
--topic topic_name: Chỉ định tên của topic cần được tạo.
--bootstrap-server localhost:9092: Chỉ định máy chủ Kafka cần kết nối. Bạn có thể thay thế localhost:9092 bằng địa chỉ máy chủ thực tế của mình.
--replication-factor 1: Chỉ định hệ số replica cho chủ đề, cho biết số lượng bản sao của mỗi phân vùng cần được duy trì. Trong ví dụ này, nó được đặt là 1.
--partitions 1: Chỉ định số lượng partition cho topic. Trong ví dụ này, nó được đặt là 1.
2. Cấu hình Topic
Các topic Kafka có một số cấu hình để xác định hành vi. Nếu không cung cấp cấu hình topic cụ thể, các thuộc tính mặc định của máy chủ sẽ được sử dụng. Bạn có thể tạo một topic bằng công cụ "kafka-topic" và tùy chọn "--config". Chúng ta có thể sửa đổi cấu hình bằng công cụ "kafka-configs" và tùy chọn "--alter".
Ví dụ: Tạo cấu hình Topic
./bin/kafka-topics.sh --create --topic topic_name --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --config retention.ms=604800000 Ví dụ: Chỉnh sửa cấu hình
./bin/kafka-configs.sh --alter --entity-type topics --entity-name topic_name --add-config retention.ms=259200000 3. Partitions và Replication
Partition: Topic partitions là một khái niệm cơ bản trong Kafka, tại đây, dữ liệu được xử lý song song và phân phối giữa nhiều broker. Mỗi partition là một tập hợp các message được sắp xếp theo thứ tự và không thể thay đổi. Khi tạo một topic, bạn chỉ định số lượng phân vùng bằng cách sử dụng cờ --partitions flag
Replication: Kafka cho phép sao chép dữ liệu trên nhiều broker để đảm bảo tính sẵn sàng của dữ liệu và khả năng chịu lỗi. Mỗi partition có thể có một hoặc nhiều replica. Trong số các replica này, một bản đóng vai trò là leader và các replica khác đóng vai trò là follower. Leader xử lý tất cả các yêu cầu đọc và ghi cho partition, trong khi các follower sao chép dữ liệu. Nếu bản leader bị lỗi, một trong các bản follower sẽ được chọn làm leader mới. Sử dụng --replication-factor để chỉ định hệ số sao chép khi tạo topic.
Ví dụ: Tạo một Topic với Partition và Replication
./bin/kafka-topics.sh --create --topic topic_name --bootstrap-server localhost:9092 --replication-factor 3 --partitions 4 Ưu điểm của kiến trúc Kafka
Tách biệt producer và consumer: Kafka tách biệt producer và consumer, cho phép chúng hoạt động độc lập, nhờ vậy mà dễ dàng mở rộng và quản lý hệ thống.
Log được sắp xếp và có tính bất biến: Kafka duy trì thứ tự các record trong một partition và đảm bảo rằng các record là bất biến. Từ đó đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
Tính khả dụng cao: Cơ chế replication và fault tolerance của Kafka đảm bảo tính khả dụng và độ tin cậy cao cho dữ liệu.
Để trải nghiệm những ưu điểm mạnh mẽ của kiến trúc Kafka, bạn có thể truy cập tại: https://bizflycloud.vn/kafka
Bizfly Cloud Kafka được thiết lập sẵn sàng để triển khai ngay lập tức giúp developer dễ dàng sử dụng Apache Kafka để giao tiếp xử lý dữ liệu theo thời gian thực trong các hệ thống mà không cần phải quản lý hay cài đặt server. Các tài nguyên sẽ được tự động cung cấp và quản lý, mở rộng quy mô ứng dụng khi khối lượng streaming data thay đổi hoàn toàn tự động, không cần thao tác thủ công, giúp bạn tập trung tối đa thời gian, công sức cho phát triển sản phẩm, tính năng cốt lõi.