Xử lý luồng dữ liệu trong Apache Kafka và Apache Flink

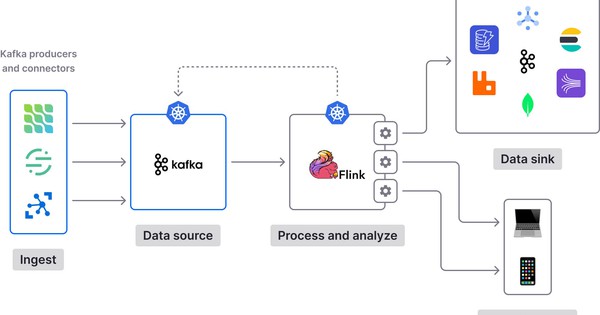
Một use case rất phổ biến cho Apache Flink là luồng dữ liệu di chuyển (movement) và phân tích (analytics). Thông thường, các luồng dữ liệu được nhập từ Apache Kafka - một hệ thống cung cấp tính bền bỉ và chức năng pub/sub cho các luồng dữ liệu.
Các cài đặt điển hình của Flink và Kafka bắt đầu với các luồng sự kiện được đẩy tới Kafka, sau đó được tiêu thụ bởi các Flink job. Các job này bao gồm từ các phép biến đổi đơn giản để nhập/xuất dữ liệu, đến các ứng dụng phức tạp hơn tổng hợp dữ liệu trong cửa sổ hoặc triển khai chức năng CEP. Kết quả của những job này có thể thực sự được phản hồi lại cho Kafka để sử dụng bởi các service khác, được viết ra cho HDFS, các hệ thống khác như Elasticsearch hoặc các giao diện web hướng tới người dùng.
Trong các pipeline như vậy, Kafka mang đến độ bền dữ liệu (data durability) và Flink mang đến khả năng tính toán (computation) và di chuyển dữ liệu (data movement) nhất quán. data Artisans và cộng đồng Flink đã nỗ lực rất nhiều để tích hợp Flink với Kafka theo cách:
(1) Đảm bảo phân phối event chính xác một lần.
(2) Không tạo ra sự cố do kỹ thuật backpressure.
(3) Có thông lượng (throughput) cao.
(4) Dễ sử dụng cho các nhà phát triển ứng dụng.
Trong bài viết này, Bizfly Cloud sẽ hướng dẫn thực hành để phát triển ứng dụng Flink đầu tiên của bạn bằng cách xử lý luồng dữ liệu trong Apache Kafka và Apache Flink. Cùng tìm hiểu nhé!
Apache Flink là gì?
Apache Flink là một khung xử lý dữ liệu xử lý hàng loạt (batch processing) và xử lý dữ liệu theo dòng (stream processing). Apache Flink được thiết kế để xử lý và phân tích dữ liệu lớn theo thời gian thực với các tác vụ như công cụ luồng dữ liệu phát trực tuyếtn phân tán, xử lý sự kiện theo thời gian thực, phát hiện gian lận và các ứng dụng cần xử lý dữ liệu nhanh và hiệu quả
Tổng quan về Kafka
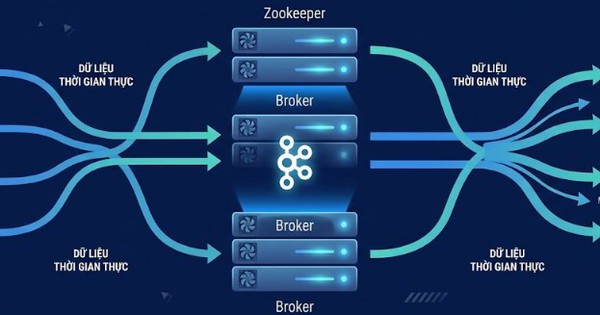
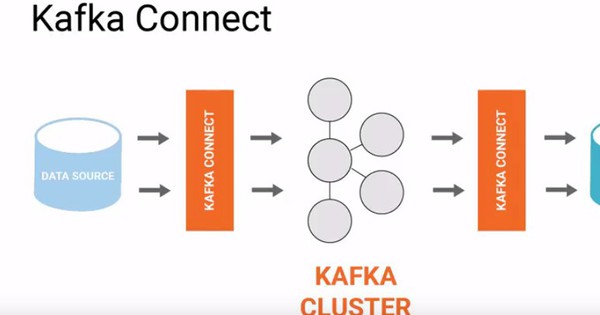
Để hiểu cách Flink tương tác với Kafka như thế nào, trước tiên chúng ta phải hiểu các khái niệm chính đằng sau Kafka. Apache Kafka (hệ thống message queuing phân tán) được thiết kế để cung cấp dữ liệu streaming cho nhiều consumer.
Kafka duy trì các message đến trên ổ đĩa bằng cấu trúc log data. Điều này cho phép nhiều downstream consumer khác nhau đọc luồng ở các vị trí khác nhau với tốc độ khác nhau, đồng thời đọc các message từ quá khứ, tức là "replaying history".
Khái niệm quan trọng nhất trong Kafka là topic. Một topic là một xử lý cho một luồng dữ liệu hợp lý, bao gồm nhiều partition. Các partition là tập hợp con của dữ liệu được cung cấp bởi topic nằm trong các nút vật lý khác nhau. Các service đưa dữ liệu vào một topic được gọi là producer. Ví dụ: Kafka đi kèm với một "console producer" đặt các chuỗi từ input tiêu chuẩn vào một topic. Ngược lại với producer, tức là service đọc dữ liệu từ một topic được gọi là consumer.
Các partition riêng lẻ của một topic được quản lý bởi một Kafka broker, một service được cài đặt trên nút chứa partition và cho phép consumer cũng như producer truy cập dữ liệu của một topic. Khi một partition được replicate (để đảm bảo độ bền), nhiều broker có thể đang quản lý cùng một partition. Sau đó, một trong những broker này được chỉ định là "leader" và những người còn lại là "follower". Kafka đang gán cho mỗi message trong một partition một id duy nhất, cái gọi là "message offset", đại diện cho một timestamp hợp lý tăng dần, duy nhất trong một partition. Offset này cho phép consumer yêu cầu những message từ một offset nhất định trở đi, về cơ bản là tiêu thụ dữ liệu từ một thời gian hợp lý nhất định trong quá khứ.
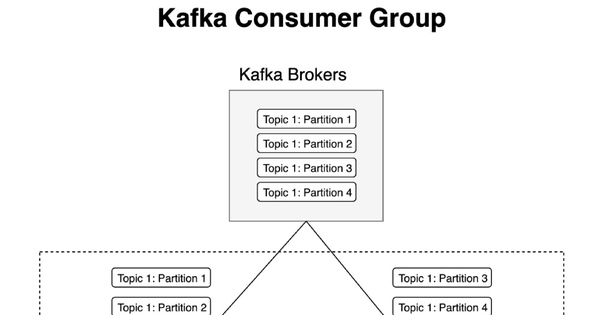
Để kích hoạt mô hình này cho nhiều consumer, có một khái niệm về "consumer groups". Đối với mỗi consumer group, các message được đảm bảo sẽ được sử dụng ít nhất một lần. Trong hình dưới đây, một producer (một cụm máy chủ web) đang đẩy các message vào một topic có bốn partition. Hai broker đang quản lý hai partition riêng biệt. Ví dụ này cũng chứa ba consumer được chia thành hai consumer group. Cả hai consumer group sẽ thấy tất cả các message được viết trong topic mặc dù cả hai đều sử dụng các tập hợp con (partition) chồng chéo của topic.
>> Có thể bạn quan tâm: Các thuật ngữ trong Kafka được sử dụng phổ biến
Thực hành: Sử dụng các Kafka topic với Flink
Bây giờ chúng ta hãy xem làm thế nào để có thể sử dụng Kafka và Flink cùng nhau trong thực tế.
1. Bắt đầu với Kafka
Cách dễ nhất để bắt đầu với Flink và Kafka là cài đặt cục bộ, độc lập. Đầu tiên, tải xuống, cài đặt và bắt đầu một Kafka broker cục bộ.
#get kafka wget http://mirror.softaculous.com/apache/kafka/0.8.2.1/kafka_2.10-0.8.2.1.tgz # unpack tar xf kafka_2.10-0.8.2.1.tgz cd kafka_2.10-0.8.2.1 # start zookeeper server ./bin/zookeeper-server-start.sh ./config/zookeeper.properties # start broker ./bin/kafka-server-start.sh ./config/server.properties # create topic "test" ./bin/kafka-topics.sh --create --topic test --zookeeper localhost:2181 --partitions 1 --replication-factor 1 # consume from the topic using the console producer ./bin/kafka-console-consumer.sh --topic test --zookeeper localhost:2181 # produce something into the topic (write something and hit enter) ./bin/kafka-console-producer.sh --topic test --broker-list localhost:909 Bây giờ, chúng ta có một broker và một máy chủ Zookeeper đang chạy cục bộ và hãy xác minh rằng quá trình đọc-viết đang hoạt động bình thường.
Consume data bằng Flink
Bước tiếp theo là subscribe một topic bằng cách sử dụng consumer của Flink. Điều này sẽ cho phép bạn chuyển đổi và phân tích bất kỳ dữ liệu nào từ luồng Kafka bằng Flink. Flink vận chuyển một module maven có tên là "flink-connector-kafka", bạn có thể thêm module này dưới dạng dependency vào dự án của mình để sử dụng Kafka connector của Flink:
dependency groupId org.apache.flink /groupId artifactId flink-connector-kafka /artifactId version 0.9.1 /version /dependency Đầu tiên, chúng ta xem xét cách sử dụng dữ liệu từ Kafka bằng Flink. Chúng ta sẽ đọc các chuỗi từ một topic, thực hiện một sửa đổi đơn giản và in chúng ra output tiêu chuẩn. Chúng ta sẽ sử dụng console producer đi kèm với Kafka. Kết quả cuối cùng là một chương trình ghi vào output tiêu chuẩn nội dung của input tiêu chuẩn. Đây là cách bạn có thể tạo Flink DataStream từ Kafka topic. Lưu ý rằng cả DataStream và topic đều là phân tác (distributed) và Flink ánh xạ (maps) các topic partition thành các DataStream partition (ở đây, chúng ta đang đọc các tham số Kafka bắt buộc từ command line):
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); ParameterTool parameterTool = ParameterTool.fromArgs(args); DataStream < String > messageStream = env.addSource(new FlinkKafkaConsumer082 [ ] (parameterTool.getRequired("topic"), new SimpleStringSchema(), parameterTool.getProperties())); Khi một DataStream được tạo, bạn có thể transform nó theo ý muốn. Ví dụ: chúng ta hãy pad từng từ bằng một tiền tố cố định và in ra stdout:
messageStream .rebalance() .map ( s -> "Kafka and Flink says: " + s) .print(); Lệnh rebalance() khiến dữ liệu được re-partitioned để tất cả các máy nhận được message (ví dụ: khi số lượng Kafka partition ít hơn số lượng parallel instances của Flink). Các đối số dòng lệnh để chuyển đến chương trình Flink này để đọc từ Kafka topic "test" mà chúng ta đã tạo trước đây như sau:
--topic test --bootstrap.servers localhost:9092 --zookeeper.connect localhost:2181 --group.id myGroup Vì chúng ta đang đọc từ console producer và in ra stdout, nên chương trình sẽ chỉ in các chuỗi bạn viết trong console. Những chuỗi này sẽ xuất hiện gần như ngay lập tức.
Produce data bằng Flink
Bây giờ hãy xem cách bạn có thể viết vào một Kafka topic bằng Flink. Như trước đây, chúng ta sẽ tạo StreamExecutionEnvironment và Flink DataStream bằng String generator đơn giản.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream < String > ; messageStream = env.addSource(new SimpleStringGenerator()); Sau đó, chúng ta sẽ đưa DataStream này vào một Kafka topic. Như trước đây, chúng ta đọc các tham số Kafka có liên quan dưới dạng đối số dòng lệnh:
ParameterTool parameterTool = ParameterTool.fromArgs(args); messageStream.addSink(new KafkaSink < > (parameterTool.getRequired("bootstrap.servers"), parameterTool.getRequired("topic"), new SimpleStringSchema())); Các đối số dòng lệnh để chuyển đến chương trình để ghi các chuỗi vào Kafka console topic mà chúng ta đã tạo ở trên sẽ như sau:
--topic test --bootstrap.servers localhost:9092 Vì chúng ta đang viết cho console topic của Kafka, nên kết quả của chương trình là các chuỗi sẽ xuất hiện trong stdout.
Chạy ví dụ trong một cluster
Tất nhiên, Flink code mà chúng ta đã thấy cũng hoạt động trong một cluster. Để chạy code này trong một cluster, trước tiên hãy cài đặt Kafka để thiết lập nhiều broker. Đảm bảo rằng bạn sử dụng Flink consumer tương ứng với phiên bản Kafka của bạn (hiện có sẵn 0.8.1 và 0.8.2). Khi tạo một topic mới trong một cluster, bạn nên đặt số lượng partition thích hợp để tất cả các parallel instances của Flink đều nhận được dữ liệu. Để đạt được điều đó, số lượng partition ít nhất phải bằng số lượng Flink instances.
Dịch vụ Kafka của Bizfly Cloud – Tối ưu hạ tầng streaming cho hệ thống dữ liệu hiện đại
Trong các pipeline kết hợp giữa Kafka và Flink, việc đảm bảo hạ tầng Kafka vận hành ổn định, độ trễ thấp và khả năng mở rộng linh hoạt là yếu tố then chốt. Dịch vụ Kafka của Bizfly Cloud được thiết kế dưới dạng managed service, giúp doanh nghiệp triển khai nhanh hệ thống streaming mà không cần tự xây dựng và vận hành phức tạp.
Giải pháp hỗ trợ tự động scale cluster, cân bằng tải, replication dữ liệu và giám sát real-time, đảm bảo luồng dữ liệu luôn ổn định và sẵn sàng cho các job xử lý như Flink, Spark hoặc hệ thống analytics phía sau.
Một số điểm nổi bật:
- Triển khai nhanh, sẵn sàng sử dụng chỉ trong vài phút
- Độ bền dữ liệu cao, phù hợp pipeline streaming quy mô lớn
- Tối ưu cho real-time processing, giảm độ trễ end-to-end
- Dễ dàng tích hợp với hệ sinh thái Big Data, AI, CDP
Với Bizfly Cloud Kafka, doanh nghiệp có thể xây dựng kiến trúc event-driven, data streaming hoặc real-time analytics một cách bài bản, ổn định và dễ mở rộng theo nhu cầu tăng trưởng.
Trên đây là toàn bộ quá trình xử lý luồng dữ liệu trong Apache Kafka và Apache Flink, hy vọng sẽ hữu ích cho bạn. Đừng quên theo dõi các bài chia sẻ tiếp theo của Bizfly Cloud để cập nhật thêm nhiều kiến thức bổ ích nhé!
Bizfly Cloud là nhà cung cấp dịch vụ điện toán đám mây với chi phí thấp, được vận hành bởi VCCorp.
Bizfly Cloud là một trong 4 doanh nghiệp nòng cốt trong "Chiến dịch thúc đẩy chuyển đổi số bằng công nghệ điện toán đám mây Việt Nam" của Bộ TT&TT; đáp ứng đầy đủ toàn bộ tiêu chí, chỉ tiêu kỹ thuật của nền tảng điện toán đám mây phục vụ Chính phủ điện tử/chính quyền điện tử.
Độc giả quan tâm đến các giải pháp của Bizfly Cloud có thể truy cập tại đây.
DÙNG THỬ MIỄN PHÍ và NHẬN ƯU ĐÃI 3 THÁNG tại: Manage.bizflycloud