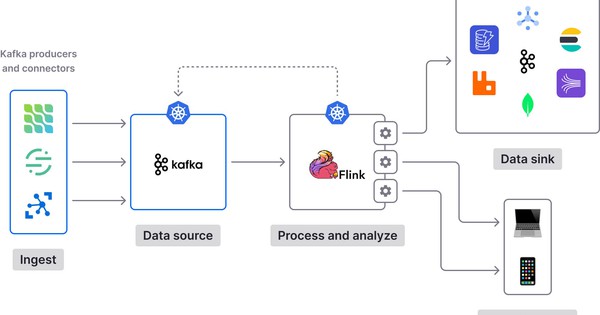
Kafka là gì? Tìm hiểu tổng quan về Apache Kafka từ A - Z

Trong bối cảnh dữ liệu lớn và phân tích thời gian thực ngày càng trở nên phổ biến, các tổ chức phải đối mặt với thách thức trong việc quản lý hiệu quả khối lượng thông tin khổng lồ đến từ nhiều nguồn khác nhau. Apache Kafka, một nền tảng streaming phân tán, đã trở thành một giải pháp mang tính đột phá cho việc truyền tải dữ liệu và xử lý thời gian thực.
Bài viết này Bizfly Cloud sẽ trình bày các đặc điểm và lợi ích cốt lõi của Apache Kafka, phân tích kiến trúc hệ thống, đồng thời minh họa các ứng dụng đa dạng của Kafka trong nhiều lĩnh vực và ngành nghề khác nhau.
Kafka là gì?
Kafka là một messaging system mã nguồn mở, được LinkedIn phát triển đầu tiên và sau đó Apache Software Foundation tiếp tục phát triển. Kafka được thiết kế để xử lý khối lượng dữ liệu lớn theo thời gian thực, rất phù hợp cho việc xây dựng các hệ thống cần phản ứng với event/sự kiện ngay tại thời điểm chúng xảy ra.
Kafka tổ chức dữ liệu thành các danh mục gọi là topic. Các producer (những ứng dụng gửi dữ liệu) ghi message vào các topic này, trong khi các consumer (những ứng dụng đọc dữ liệu) sẽ nhận và xử lý chúng. Kafka đảm bảo tính tin cậy & tính khả dụng (khả năng tiếp tục hoạt động ngay cả khi một số thành phần gặp sự cố) của hệ thống.

Kafka được xây dựng nhằm mục đích xử lý dữ liệu streaming theo thời gian thực
Ngày nay, Kafka đã phát triển thành nền tảng stream dữ liệu phân tán được sử dụng rộng rãi nhất, có khả năng nhập và xử lý hàng nghìn tỷ bản ghi mỗi ngày mà không có bất kỳ độ trễ hiệu suất có thể nhận thấy nào theo quy mô khối lượng. Các tổ chức trong danh sách Fortune 500 như Target, Microsoft, AirBnB và Netflix dựa vào Kafka để cung cấp trải nghiệm theo thời gian thực, theo hướng dữ liệu cho khách hàng của họ.
Kafka được sử dụng để làm gì?
Kafka làm kho dữ liệu phân tán được sử dụng để xử lý dữ liệu theo thời gian thực. Nếu là nền tảng streaming trực tuyến thì sẽ cần xử lý dữ liệu một cách liên tục theo thứ tự tăng dần. Dưới đây là 3 chức năng chính của Kafka:
- Publish và subscribe các stream of record
- Lưu trữ các stream of record theo thứ tự
- Hỗ trợ xử lý stream of record theo thời gian thực
Ưu, nhược điểm nổi bật của Kafka
Một số ưu và nhược điểm nổi bật của Kafka cụ thể như sau:
Ưu điểm của Kafka
- Open-source
- High-throughput: Có khả năng xử lý một lượng lớn thông tin một cách liên tục, gần như không có thời gian chờ
- High-frequency: Có thể xử lý cùng lúc nhiều message và nhiều thể loại topic
- Scalability: Dễ dàng mở rộng khi có nhu cầu
- Tự động lưu trữ message, dễ dàng kiểm tra lại
- Cộng đồng người dùng đông đảo, được hỗ trợ nhanh chóng khi cần
Nhược điểm của Kafka
- Chưa có bộ công cụ giám sát hoàn chỉnh: Có nhiều tool khác nhau nhưng mỗi tool chỉ đáp ứng một tính năng quản lý nhất định, chẳng hạn như: Kafka tool (offset manager) GUI tool - quản lý topic và consumer, Lense - hỗ trợ query message, Akhq - toolbox quản lý Kafka và view data bên trong Kafka
- Không chọn được topic theo wildcard: Người dùng sẽ cần phải sử dụng chính xác tên topic để xử lý message
- Giảm hiệu suất: Kích thước message tăng khiến cho consumer và producer phải compress và decompress message, từ đó làm bộ nhớ bị chậm đi, ảnh hưởng đến throughput và hiệu suất.
- Xử lý chậm: Đôi khi số lượng queues trong Kafka cluster tăng đột biến khiến Kafka xử lý chậm hơn.

Kafka có nhược điểm lớn về độ phức tạp cao trong cấu hình và vận hành
Lý do nên sử dụng Kafka
Kafka được đóng gói hoàn chỉnh, hiệu năng cao, dễ dàng mở rộng mà không làm gián đoạn hệ thống. Nếu bạn đang xây dựng phần mềm hoặc website hiển thị thông tin theo thời gian thực, thì đây chính là một lựa chọn lý tưởng. Bên cạnh đó, Kafka cũng có khả năng nhập và lưu trữ dữ liệu trong quá trình phát trực tiếp; hoặc sử dụng như một phần mềm message broker để các ứng dụng/nền tảng giao tiếp với nhau.
Một số lợi ích nổi bật của Kafka bao gồm:
- Khả năng mở rộng cao: Mô hình phân vùng nhật ký của Kafka cho phép dữ liệu có thể được phân phối trên nhiều máy chủ và mở rộng máy chủ khi có nhu cầu.
- Tốc độ nhanh chóng: Việc xử lý thông qua tách các luồng dữ liệu giúp cho tốc độ trở nên nhanh hơn.
- Khả năng chịu lỗi và độ bền: Do các gói dữ liệu được sao chép và phân phối trên nhiều máy chủ khác nhau, nên khi có sự cố thì dữ liệu sẽ ít gặp lỗi và an toàn hơn.
>> Có thể bạn quan tâm: Lợi ích của việc sử dụng Apache Kafka thay vì AMQP hoặc JMS
Cơ chế hoạt động của Kafka
Apache Kafka hoạt động giống như một message queue (hàng đợi message) pub-sub truyền thống (chẳng hạn như RabbitMQ) ở chỗ nó cho phép bạn publish và subscribe các luồng message. Tuy nhiên Apache Kafka khác với message queue truyền thống ở 3 điểm chính:
- Kafka hoạt động như một hệ thống phân tán hiện đại chạy dưới dạng một cụm và có thể mở rộng quy mô để xử lý bất kỳ số lượng ứng dụng nào.
- Kafka được thiết kế để phục vụ như một hệ thống lưu trữ và có thể lưu trữ dữ liệu trong thời gian cần thiết; hầu hết các message queue sẽ xóa message ngay sau khi consumer xác nhận đã nhận.
- Kafka xử lý stream processing, tính toán các luồng dẫn xuất và các dataset một cách linh hoạt, thay vì chỉ chuyển các dãy thông báo.

Cơ chế hoạt động của Apache Kafka dựa trên mô hình dòng dữ liệu (streaming)
Các Thành phần cốt lõi của Apache Kafka
Để hiểu cách Kafka hoạt động, chúng ta cần biết về các thành phần cốt lõi trong quy trình xử lý của Kafka:
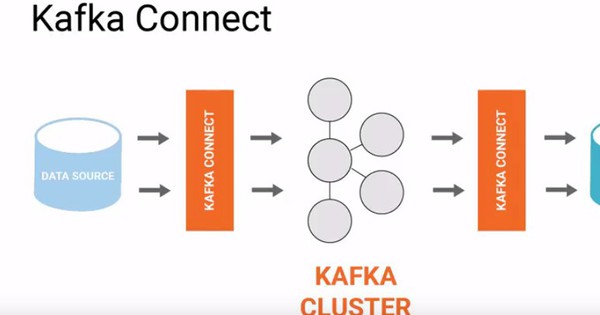
1. Kafka Broker
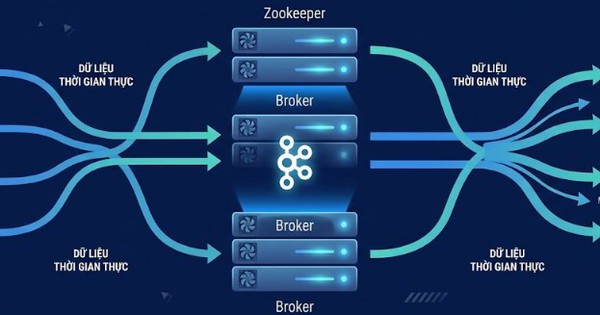
Một Kafka broker chính là một server mà trên đó chạy Kafka và lưu trữ dữ liệu. Thông thường, một cụm Kafka bao gồm nhiều broker hoạt động cùng nhau để cung cấp khả năng mở rộng, khả năng chịu lỗi/fault tolerance và tính sẵn sàng cao. Mỗi broker chịu trách nhiệm store và server dữ liệu liên quan đến các topics.
2. Producers
Một producer là một application hoặc service gửi message đến một topic Kafka. Các quy trình gửi này sẽ đẩy dữ liệu vào hệ thống Kafka. Producers sẽ quyết định topic nào mà message nên được gửi đến, còn Kafka sẽ xử lý việc lưu trữ message một cách hiệu quả dựa trên chiến lược phân vùng (partitioning strategy).
3. Kafka topic
Trong Kafka, topic là một danh mục hoặc tên luồng (feed) mà các message được gửi vào. Các message trong Kafka luôn gắn liền với một topic, và khi muốn gửi một message, producer sẽ gửi message đó tới một topic cụ thể.
Các topic được chia thành nhiều partition, cho phép Kafka mở rộng theo chiều ngang và xử lý hiệu quả khối lượng dữ liệu lớn.
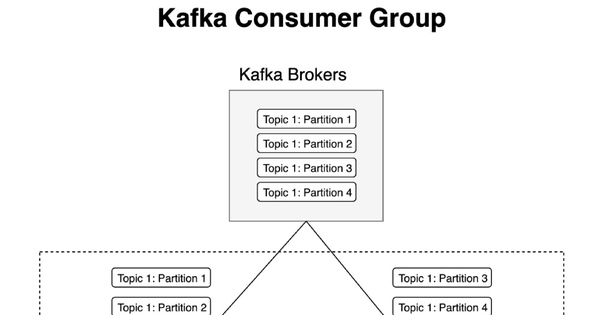
4. Consumer và Consumer Group
Consumer là ứng dụng dùng để đọc dữ liệu từ Kafka. Khi producer gửi message vào topic, consumer sẽ lấy những message đó ra để xử lý. Kafka cho phép nhiều consumer cùng đọc dữ liệu thông qua consumer group. Trong đó, một consumer group gồm một hoặc nhiều consumer. Trong cùng một consumer group, mỗi message chỉ được một consumer xử lý. Điều này giúp cân bằng tải giữa các consumer, tránh xử lý trùng lặp
Ví dụ:
Nếu một topic có 3 partition và consumer group có 3 consumer, thì mỗi consumer sẽ đọc dữ liệu từ 1 partition, từ đó giúp xử lý song song, nhanh hơn.
Partition giúp xử lý song song bằng cách phân chia topic thành nhiều partition. Mỗi partition có thể được xử lý độc lập, vì vậy Kafka có thể chạy nhiều consumer cùng lúc, phân tán dữ liệu trên nhiều broker, xử lý lượng dữ liệu lớn hiệu quả hơn.
5. ZooKeeper
Kafka sử dụng Apache ZooKeeper để quản lý metadata, kiểm soát quyền truy cập vào tài nguyên Kafka và xử lý việc chọn leader, cũng như điều phối các broker. ZooKeeper cung cấp tính khả dụng cao nhờ đảm bảo Kafka cluster vẫn hoạt động ngay cả khi một broker gặp sự cố.

Apache ZooKeeper là một dịch vụ điều phối tập trung (centralized service) mạnh mẽ
Các khái niệm quan trọng trong Apache Kafka
Topic partition: Các Kafka topic được chia thành nhiều partition, cho phép bạn phân chia dữ liệu trên nhiều broker.
Consumer Group: Consumer Group là tập hợp các tiến trình consumer cùng subscribe một topic cụ thể.
Node: Node là một máy tính hoặc máy chủ đơn lẻ trong cụm Apache Kafka.
Replicas: Replica của một partition là "bản backup" của partition đó. Bản backup không được sử dụng để đọc hoặc ghi dữ liệu mà giúp ngăn ngừa mất dữ liệu.
Producer: Ứng dụng gửi messages.
Consumer: Ứng dụng nhận messages.
Cách thức hoạt động của Apache Kafka
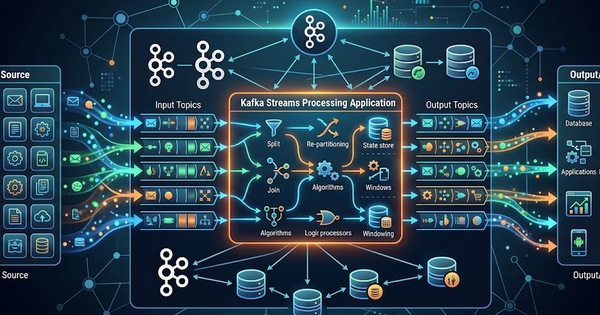
Apache Kafka di chuyển dữ liệu từ nơi này sang nơi khác một cách mượt mà và đáng tin cậy. Dưới đây là cách thức hoạt động một cách đơn giản:
Bước 1: Các Producer gửi data
Các Producer là các ứng dụng tạo ra data và gửi chúng đến Kafka.
Data có thể là bất cứ dữ liệu gì từ log, giao dịch, hoạt động của user cho đến event.
Kafka chia dữ liệu thành các phần nhỏ hơn gọi là partition, giúp dễ dàng xử lý lượng thông tin lớn.
Bước 2: Kafka lưu trữ data
Kafka tổ chức data thành các topic, ở đây data sẽ được lưu trữ trong một khoảng thời gian nhất định.
Ngay cả khi consumer đã đọc data, Kafka cũng không xóa dữ liệu ngay lập tức.
Để ngăn ngừa mất dữ liệu, Kafka tạo bản sao của dữ liệu và lưu trữ chúng trên các máy chủ khác nhau.
Bước 3: Consumer đọc dữ liệu
Consumer là các ứng dụng subcribe các topic và đọc các message.
Để quản lý tải, consumer được chia thành các consumer group, và từ đó đảm bảo không có message nào được xử lý hai lần.
Consumer có thể chọn bắt đầu đọc từ đâu, có thể là message mới nhất hoặc dữ liệu từ trước đó.
Bước 4: Kafka cân bằng tải
ZooKeeper giúp Kafka quản lý các server chịu trách nhiệm lưu trữ và phân phối dữ liệu.
Nếu một server gặp sự cố, Kafka sẽ tự động chuyển hướng dữ liệu đến server khác.
Bước 5: Data được xử lý và sử dụng
Sau khi consumer nhận data, các ứng dụng có thể lưu trữ data trong database, phân tích dữ liệu hoặc kích hoạt các event khác.
Kafka có thể hoạt động tốt với các công cụ như Apache Spark, Apache Flink và Hadoop để thực hiện phân tích sâu hơn.
Tìm hiểu về ứng dụng của Kafka
Nhờ khả năng xử lý hiệu quả và lưu trữ dữ liệu lớn theo thời gian thực, Kafka được các doanh nghiệp thuộc nhiều lĩnh vực khác nhau tin tưởng để sử dụng cho hệ thống của họ. Cùng tìm hiểu về ứng dụng của Kafka đối với người dùng nhé!
Đóng vai trò như message broker
Người dùng có thể sử dụng Kafka để thay thế cho các Message broker, ví dụ như ActiveMQ hoặc RabbitMQ.
Quản lý hoạt động website
Đây là cách thức truyền thống để sử dụng Kafka, được dùng để xây dựng website và đăng tải nội dung theo thời gian thực. Các dữ liệu như lượt xem trang, hoạt động tìm kiếm… đều được tạo thành các topic. Việc quản lý hoạt động này giúp bạn phân tích hành vi của người dùng trên trang tốt hơn, từ đó thu hút được nhiều người đọc hơn.
Đo lường
Kafka cũng có thể được dùng để xây dựng dữ liệu giám sát các hoạt động. Điều này đồng nghĩa với việc tập hợp số liệu thống kê từ nhiều nguồn phân tán trên trang để tạo ra một nguồn dữ liệu tổng hợp.
Tạo log
Kafka hỗ trợ tổng hợp log hoặc nhật ký hoạt động, tóm tắt các chi tiết và cung cấp bản ghi cụ thể về dữ liệu sự kiện nhằm phục vụ cho việc xử lý trong tương lai.
Stream processing
Steam processing là cách sử dụng phổ biến hiện nay của Kafka, hệ thống được phát triển để xử lý dữ liệu theo thời gian thực. Mỗi khi dữ liệu mới được thêm vào topic, thì sẽ được ghi vào hệ thống ngay lập tức và truyền đến bên nhận dữ liệu. Hơn nữa, thư viện Kafka Streams được tích hợp từ phiên bản 0.10.0.0 có tính năng xử lý stream nhẹ nhưng rất mạnh mẽ.
Kết luận
Trong quá trình phát triển website, ứng dụng rất dễ xảy ra trường hợp lượng message cần xử lý tăng lên quá nhiều dẫn đến các data pipeline trở nên vô cùng phức tạp, khiến việc quản lý và vận hành rất khó khăn. Kafka với năng lực phân phối tuyệt vời là giải pháp hoàn hảo để xử lý cho bài toán này. Tuy nhiên, để triển khai 1 hệ thống như vậy sẽ cần rất nhiều thời gian, nguồn lực, tài nguyên và chi phí.
Bizfly Cloud Kafka là dịch vụ được cung cấp tiên phong tại Việt Nam, giúp các Developer có thể tự động hóa hoàn toàn việc quản lý, duy trì và mở rộng các cụm Apache Kafka mà không tốn công sức triển khai, dễ dàng quản lý giúp tối ưu chi phí tài nguyên, nguồn lực.
Bizfly Cloud Kafka giúp bạn mở rộng quy mô ứng dụng khi khối lượng streaming data thay đổi mà bạn không phải liên tục định cỡ đúng hoặc lo lắng về việc hệ thống cung cấp dữ liệu quá mức.
Bizfly Cloud Kafka có máy chủ đặt tại các DC trong nước, luôn đảm bảo tốc độ cao, độ trễ thấp. Bạn sẽ không phải lo lắng về việc kết nối chậm hay chập chờn do đứt cáp quang biển.
Bizfly Cloud Kafka cũng cung cấp metrics và logging miễn phí, giúp tiết kiệm chi phí tối đa cho doanh nghiệp.
Đăng ký dùng thử miễn phí ngay: https://bizflycloud.vn/kafka
>> Tìm hiểu thêm: Kiến trúc Kafka hiện đại: các thành phần, mô hình thực tế, các API & framework
Bizfly Cloud là nhà cung cấp dịch vụ điện toán đám mây với chi phí thấp, được vận hành bởi VCCorp.
Bizfly Cloud là một trong 4 doanh nghiệp nòng cốt trong "Chiến dịch thúc đẩy chuyển đổi số bằng công nghệ điện toán đám mây Việt Nam" của Bộ TT&TT; đáp ứng đầy đủ toàn bộ tiêu chí, chỉ tiêu kỹ thuật của nền tảng điện toán đám mây phục vụ Chính phủ điện tử/chính quyền điện tử.
Độc giả quan tâm đến các giải pháp của Bizfly Cloud có thể truy cập tại đây.
DÙNG THỬ MIỄN PHÍ và NHẬN ƯU ĐÃI 3 THÁNG tại: Manage.bizflycloud