Hiệu năng Kafka: Cách đo và tối ưu Throughput, Latency, Lag

Hiệu năng Kafka là yếu tố quyết định khả năng xử lý dữ liệu thời gian thực của toàn bộ hệ thống. Tuy nhiên, khi quy mô tăng lên, việc cân bằng giữa throughput, latency và consumer lag không còn đơn giản, mà trở thành một bài toán tối ưu phức tạp. Bài viết này Bizfly Cloud sẽ giúp bạn hiểu cách đo lường chính xác hiệu năng Kafka và từng bước tối ưu từ producer, broker đến consumer, đồng thời chỉ ra khi nào nên chuyển sang giải pháp Managed Kafka để giảm gánh nặng vận hành.
Hiệu năng Kafka là gì?
Hiệu năng Kafka là khả năng hệ thống vận hành hiệu quả thông qua việc điều chỉnh cấu hình, giám sát chỉ số và phân bổ tài nguyên phần cứng nhằm tối ưu throughput (thông lượng), giảm latency (độ trễ) và sử dụng tài nguyên hợp lý.
Hiệu năng Kafka không phải là một con số đứng độc lập, mà là sự cân bằng nghệ thuật giữa ba trụ cột:

Hiệu năng Kafka là gì?
- Throughput (Thông lượng): Lượng dữ liệu (messages/giây hoặc MB/giây) mà hệ thống có thể xử lý. Đây là ưu tiên hàng đầu cho các hệ thống Log Aggregation hoặc ETL.
- Latency (Độ trễ): Thời gian từ lúc Producer gửi tin nhắn cho đến khi Consumer có thể đọc được nó. Đây là chỉ số sống còn cho các ứng dụng Real-time như phát hiện gian lận tài chính (Fraud Detection).
- Consumer Lag (Độ trễ tích tụ): Khoảng cách giữa vị trí dữ liệu mới nhất được ghi vào và vị trí mà Consumer đang xử lý. Lag tăng đồng nghĩa với việc hệ thống của bạn đang "nợ" dữ liệu.
Trong Kafka, Throughput và Latency tỉ lệ nghịch với nhau. Khi bạn gom tin nhắn thành lô lớn (Batching) để đẩy Throughput lên cao nhất, Latency sẽ tăng vì tin nhắn phải đợi để đủ lô. Vì vậy, không thể tối ưu cả 3 cùng lúc. Cách tối ưu Kafka không phải là tối đa một chỉ số, mà là tìm “điểm cân bằng” (sweet spot) phù hợp với từng trường hợp:
- Log system → ưu tiên throughput
- Payment → ưu tiên latency
[Xem thêm: Độ trễ mạng là gì? Nguyên nhân và cách khắc phục]
Cách đo trước khi tối ưu
Trước khi tuning, bạn cần trả lời 3 câu hỏi:
- Hệ thống đang chậm ở đâu?
- Bottleneck nằm ở CPU, disk hay network?
- Chỉ số nào bị ảnh hưởng: throughput, latency hay lag?
Một sai lầm phổ biến trong các dự án Kafka là bắt đầu tuning ngay khi thấy hệ thống “có vẻ chậm”. Nhưng nếu không đo đúng, mọi điều chỉnh đều chỉ là phỏng đoán.
Các hệ thống Kafka hiệu quả luôn bắt đầu bằng việc hiểu rõ workload. Workload ở đây không chỉ là số message mỗi giây, mà còn bao gồm kích thước message, pattern đọc/ghi, độ phân tán key, và cả đặc thù xử lý phía consumer. Kafka cung cấp sẵn các công cụ như:
Sử dụng công cụ Benchmark: Kafka đi kèm với kafka-producer-perf-test.sh và kafka-consumer-perf-test.sh. Hãy chạy các bài test này với cấu hình sát nhất với thực tế (kích thước message, số partition).
Bước tiếp theo là xác định Bottleneck:
- Nếu CPU cao: Thường do nén/giải nén hoặc SSL/TLS.
- Nếu Disk I/O cao: Do tốc độ ghi đĩa không đáp ứng hoặc Page Cache quá nhỏ.
- Nếu Network bão hòa: Do lưu lượng Replication giữa các Broker quá lớn.
Theo dõi Metric: Luôn giám sát records-lag-max và UnderReplicatedPartitions thông qua Prometheus/Grafana.
Một điểm quan trọng trong thực tế triển khai là: phần lớn vấn đề hiệu năng không nằm ở Kafka, mà nằm ở cách hệ thống xung quanh Kafka tương tác với nó.
Tối ưu Producer Kafka để tăng Throughput
Producer là nơi quyết định cách dữ liệu đi vào Kafka, và do đó ảnh hưởng trực tiếp đến throughput và latency ngay từ đầu.
Batching (gom nhóm)
Batching là cơ chế quan trọng nhất. Thay vì gửi từng message, producer gom nhiều message thành một batch trước khi gửi. Điều này giúp giảm số lượng request mạng và tận dụng tốt hơn khả năng ghi tuần tự của Kafka. Tuy nhiên, việc tăng batch.size và linger.ms không chỉ đơn giản là “tăng lên là tốt”. Nếu linger quá cao, message sẽ phải chờ lâu trước khi được gửi, làm tăng latency một cách không cần thiết.
Compression
Compression là một lớp tối ưu khác nhưng thường bị hiểu sai. Nén dữ liệu không chỉ giảm băng thông mạng mà còn giảm lượng dữ liệu ghi xuống disk. Trong nhiều trường hợp, CPU dùng để nén rẻ hơn rất nhiều so với chi phí I/O. Các thuật toán như LZ4 hoặc Snappy phù hợp với hệ thống cần throughput cao, trong khi Zstd mang lại hiệu quả tốt hơn trong các cluster hiện đại có CPU dư.
- Snappy/LZ4: Tốt cho throughput vì tốc độ nhanh và CPU thấp.
- Zstd: Cân bằng tốt giữa tỉ lệ nén và tốc độ, phù hợp cho các phiên bản Kafka mới.
Acknowledgement
Cấu hình acknowledgement (acks) lại là điểm giao giữa hiệu năng và độ an toàn dữ liệu. Khi chọn acks=all, producer phải chờ toàn bộ replica xác nhận, làm tăng latency nhưng đảm bảo dữ liệu không mất khi broker lỗi. Ngược lại, acks=0 gần như loại bỏ độ trễ nhưng đánh đổi bằng rủi ro mất dữ liệu. Đây không phải quyết định kỹ thuật thuần túy, mà là quyết định kinh doanh.
- acks=0: Không đợi xác nhận; throughput cao nhất nhưng rủi ro mất dữ liệu lớn.
- acks=1: Đợi leader xác nhận; cân bằng giữa tốc độ và an toàn.
- acks=all: Đợi tất cả các bản sao (ISR) xác nhận; an toàn nhất nhưng độ trễ cao nhất
Retries/timeout/in-flight requests
Tham số max.in.flight.requests.per.connection quyết định số lượng yêu cầu chưa được xác nhận mà Producer có thể gửi trên một kết nối.
Nếu bạn đặt chỉ số này > 1 để tăng Throughput nhưng lại để idempotence=false (mặc định ở các bản cũ), hệ thống rất dễ gặp tình trạng Duplicate message hoặc Mất thứ tự dữ liệu khi có lỗi mạng xảy ra.
Vì vậy, trong hầu hết các hệ thống production, nên bật enable.idempotence=true để vừa đảm bảo thứ tự, vừa tránh duplicate message khi retry.
Record size và keying strategy
Cuối cùng, chiến lược keying thường bị xem nhẹ nhưng lại là nguyên nhân phổ biến gây mất cân bằng tải. Nếu key không được phân phối đều, một số partition sẽ trở thành điểm nóng, làm giảm throughput toàn hệ thống dù các partition khác đang không hoạt động.
Tối ưu Topic/Partition
Chọn số partition theo mục tiêu
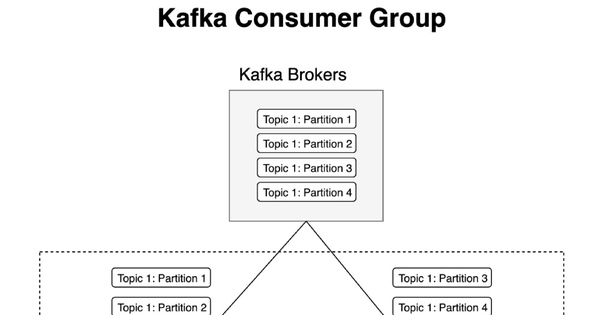
Số lượng partition quyết định trực tiếp mức độ song song hóa tối đa của consumer trong Kafka. Mỗi partition chỉ có thể được xử lý bởi một consumer trong cùng một group tại một thời điểm, vì vậy nếu số partition ít hơn số consumer, sẽ có consumer không được sử dụng hết.
Vì lý do đó, một nguyên tắc phổ biến là số partition nên lớn hơn hoặc bằng số lượng consumer tối đa dự kiến trong một consumer group. Điều này đảm bảo hệ thống có thể scale khi cần tăng throughput xử lý.
Tuy nhiên, partition không phải “càng nhiều càng tốt”. Mỗi partition đều tạo thêm chi phí quản lý cho broker, bao gồm metadata, file handle và hoạt động đồng bộ giữa các replica. Khi số lượng partition trên mỗi broker tăng quá cao (ví dụ hàng chục nghìn), hệ thống sẽ gặp vấn đề về hiệu năng như tăng độ trễ khi xử lý metadata, chậm trong quá trình bầu chọn leader và thời gian phục hồi cluster kéo dài khi có sự cố.
Vì vậy, việc chọn số partition cần cân bằng giữa hai yếu tố: khả năng scale của consumer và khả năng chịu tải của broker.
Tránh hotspot
Hotspot là vấn đề nghiêm trọng hơn. Khi một partition nhận phần lớn traffic, broker chứa partition đó sẽ trở thành bottleneck (thắt nghẽn cổ chai). Điều này không thể giải quyết bằng cách “tăng server”, mà phải quay lại thiết kế key và cách phân phối dữ liệu.
Cần phân bổ partition đồng đều trên các broker để tránh tình trạng một broker bị quá tải trong khi những cái khác đang rảnh rỗi.
Replication factor và ISR
Replication factor và ISR (in-sync replicas) ảnh hưởng trực tiếp đến độ an toàn và hiệu năng của Kafka. Replication càng cao thì hệ thống càng chịu lỗi tốt, nhưng mỗi lần ghi sẽ phải đồng bộ sang nhiều broker hơn, làm tăng độ trễ và tiêu tốn tài nguyên.
Vì vậy, cần cân bằng giữa durability và tốc độ, thay vì luôn chọn replication cao nhất.
Retention/segment
log.segment.bytes quyết định kích thước mỗi phân đoạn log. Segment lớn giúp giảm số lượng file và overhead hệ thống, nhưng có thể làm chậm quá trình dọn dẹp dữ liệu cũ.
Cleanup policy xác định cách Kafka giữ dữ liệu: delete sẽ xóa theo thời gian hoặc dung lượng, còn compact chỉ giữ lại giá trị mới nhất của mỗi key, phù hợp với các bài toán lưu trạng thái.
Tối ưu Broker (Cluster) để chịu tải tốt và ổn định
Disk và page cache
Kafka tận dụng cơ chế zero-copy và Linux page cache để tối ưu I/O, giúp giảm việc sao chép dữ liệu và tăng tốc độ đọc/ghi.
Vì ghi dữ liệu theo kiểu tuần tự, hiệu năng Kafka phụ thuộc lớn vào disk. Trong production, SSD (đặc biệt NVMe) gần như là bắt buộc nhờ throughput cao và độ trễ thấp hơn nhiều so với HDD.
Network và request handling
Hiệu năng Kafka cũng bị giới hạn bởi khả năng xử lý request và băng thông mạng. Các tham số như num.network.threads và num.io.threads nên được điều chỉnh theo số core CPU để xử lý song song tốt hơn. Ngoài ra, cần tuning socket.send.buffer.bytes và socket.receive.buffer.bytes để phù hợp với băng thông, tránh nghẽn mạng khi tải tăng cao.
Controller/metadata và cân bằng partition
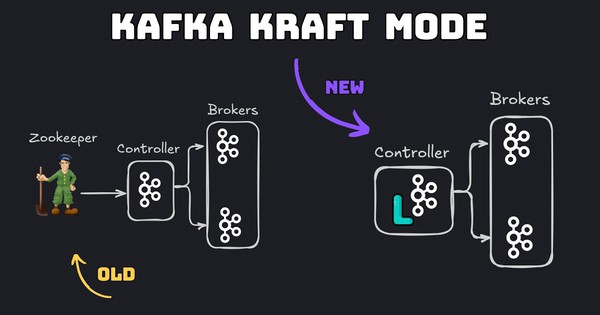
Các phiên bản Kafka mới sử dụng KRaft giúp loại bỏ ZooKeeper, từ đó cải thiện khả năng mở rộng metadata và tốc độ phục hồi cluster. Bên cạnh đó, cần thường xuyên kiểm tra và rebalance partition để đảm bảo tải được phân bổ đều, tránh tình trạng một broker trở thành điểm nghẽn.
Xem thêm: Message Broker là gì? Các ứng dụng thực tế của Message Broker
Tối ưu Consumer để giảm Lag và tránh Rebalance liên tục
Tối ưu logic xử lý
Phần lớn consumer lag không đến từ Kafka mà từ tầng xử lý phía sau. Khi mỗi message phải trải qua các thao tác chậm như ghi database, gọi API hoặc xử lý đồng bộ, tốc độ tiêu thụ sẽ nhanh chóng bị “tụt lại” so với tốc độ producer gửi vào.
Giải pháp không chỉ là tăng tài nguyên mà cần thay đổi cách xử lý. Batch processing giúp giảm số lần I/O, đặc biệt hiệu quả với database. Trong khi đó, xử lý bất đồng bộ (async) giúp tận dụng thời gian chờ I/O để xử lý các message khác. Với workload lớn, việc tách pipeline (queue trung gian, worker riêng) cũng giúp giảm áp lực trực tiếp lên consumer.
Fetch tuning
Cách consumer lấy dữ liệu từ broker ảnh hưởng trực tiếp đến hiệu năng tổng thể. Nếu fetch.min.bytes quá thấp, consumer sẽ liên tục gửi request nhỏ, gây overhead mạng và giảm throughput. Ngược lại, nếu đặt quá cao, consumer phải chờ đủ dữ liệu mới nhận được phản hồi, làm tăng độ trễ.
fetch.max.wait.ms đóng vai trò cân bằng: broker sẽ chờ tối đa một khoảng thời gian để gom đủ dữ liệu trước khi trả về. Khi phối hợp hai tham số này hợp lý, hệ thống sẽ giảm số request nhưng vẫn kiểm soát được latency, đặc biệt quan trọng với hệ thống streaming gần real-time.
Poll & timeouts
Cơ chế consumer group yêu cầu mỗi consumer phải gửi heartbeat đều đặn thông qua poll(). Nếu thời gian xử lý mỗi batch quá lâu, consumer không gọi poll kịp, Kafka sẽ coi nó là failed và kích hoạt rebalance.
Rebalance không chỉ gây gián đoạn mà còn làm tăng lag do phải phân phối lại partition và load lại state. Vì vậy, max.poll.records cần được điều chỉnh sao cho mỗi batch vừa đủ để xử lý trong thời gian cho phép. Đồng thời, session.timeout.ms và heartbeat.interval.ms cần được thiết lập cân bằng: đủ nhanh để phát hiện lỗi thật, nhưng không quá nhạy khiến mạng chập chờn cũng gây rebalance.
Scale consumer group đúng cách
Kafka chỉ cho phép một partition được đọc bởi một consumer trong cùng group tại một thời điểm, nên số partition chính là giới hạn trên của khả năng song song.
Nếu số consumer ít hơn partition, hệ thống chưa tận dụng hết khả năng song song. Ngược lại, nếu nhiều hơn, các consumer dư sẽ không nhận được dữ liệu nhưng vẫn tiêu tốn tài nguyên. Vì vậy, việc thiết kế số partition ngay từ đầu phải dựa trên throughput kỳ vọng và kế hoạch scale consumer trong tương lai, tránh phải re-partition tốn kém sau này.
Khi nào nên dùng Bizfly Cloud Kafka để đảm bảo hiệu năng
Thực tế, khi hệ thống bắt đầu lớn mạnh, việc tự vận hành một cụm Kafka có thể nhanh chóng trở thành một "gánh nặng" kỹ thuật. Những luồng dữ liệu đan xen phức tạp khiến việc duy trì sự ổn định trở thành một cuộc chiến tiêu tốn quá nhiều thời gian và nguồn lực.
Thay vì phải tiêu tốn tâm sức vào việc cài đặt server, tinh chỉnh từng thông số phần cứng hay lo lắng mỗi khi lượng tin nhắn tăng đột biến, bạn có thể cân nhắc chuyển sang Bizfly Cloud Kafka. Đây không chỉ là việc thuê hạ tầng, mà là cách giúp đơn giản hóa toàn bộ quá trình vận hành:
- Tự động hóa sự tăng trưởng: Hệ thống tự động mở rộng số lượng broker và dung lượng lưu trữ theo nhu cầu thực tế. Throughput của bạn luôn ổn định mà không cần bất kỳ thao tác thủ công nào.
- Tối ưu hóa dòng tiền: Với mô hình pay-as-you-go, doanh nghiệp gạt bỏ được áp lực chi phí đầu tư ban đầu cho các thiết bị đắt đỏ. Bạn chỉ chi trả cho những gì thực sự mang lại giá trị.
- An tâm tuyệt đối: Nỗi lo về rò rỉ dữ liệu hay sập hệ thống được giải quyết bằng cơ chế mã hóa mặc định, kiểm soát ACL nghiêm ngặt và kiến trúc Multi DC sẵn sàng cao nhất.
Kết luận
Tối ưu hiệu năng Kafka không phải là đích đến, mà là nghệ thuật của sự cân bằng. Thay vì dành quá nhiều thời gian cho việc quản trị hạ tầng phức tạp, hãy để Bizfly Cloud Kafka lo phần "nền móng", giúp đội ngũ của bạn tập trung 100% vào việc phát triển sản phẩm cốt lõi.