Deep data observability là gì?
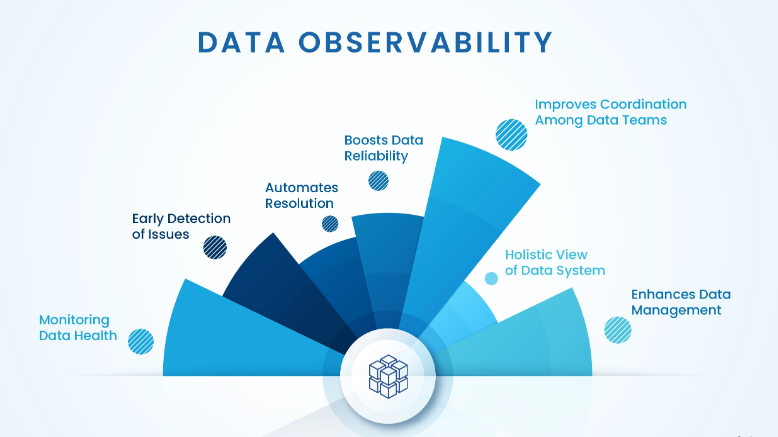
Bài viết phân tích lý do tại sao Deep data observability khác biệt so với Shallow data observability: Deep data observability thực sự toàn diện về nguồn dữ liệu, định dạng dữ liệu, mức độ chi tiết dữ liệu, cấu hình trình xác thực,... Hãy cùng Bizfly Cloud tìm hiểu 6 trụ cột tạo nên Deep data observability - giải pháp cho dữ liệu chất lượng cao.
Nhu Cầu Về "Deep" Data Observability
Năm 2022 là năm data observability thực sự cất cánh như một danh mục (trái ngược với “công cụ chất lượng dữ liệu” kiểu cũ), với thuật ngữ chính thức của Gartner cho không gian này. Tương tự, Matt Turck đã hợp nhất các danh mục chất lượng dữ liệu và data observability trong phân tích MAD Landscape 2023. Tuy nhiên, ngành vẫn chưa hoàn thiện. Trong báo cáo năm 2023 có tiêu đề “Data Observability—the Rise of the Data Guardians”, Oyvind Bjerke tại MMC Ventures thảo luận về không gian này là có tiềm năng chưa được khai thác lớn cho sự đổi mới hơn nữa.

Nhu Cầu Về "Deep" Data Observability
Trong bối cảnh của không gian năng động này, chúng ta hãy định nghĩa data observability là:
Mức độ mà một tổ chức có thể hiển thị trực quan các pipelines dữ liệu của mình. Mức độ hiển thị dữ liệu cao cho phép các nhóm dữ liệu cải thiện chất lượng dữ liệu.
Tuy nhiên, không phải tất cả các nền tảng data observability, tức là các công cụ được thiết kế đặc biệt để giúp các tổ chức đạt được data observability, đều được tạo ra như nhau. Các công cụ khác nhau về mức độ hiển thị dữ liệu mà chúng có thể giúp các nhóm dựa trên dữ liệu đạt được. Do đó, chúng tôi phân biệt giữa deep data observability và shallow data observability. Chúng khác nhau ở các khía cạnh sau: Nguồn dữ liệu, định dạng dữ liệu, mức độ chi tiết dữ liệu, cấu hình trình xác thực, nhịp độ của trình xác thực và trọng tâm người dùng.
Trong phần còn lại của bài viết này, chúng tôi sẽ đi sâu vào deep data observability và giải thích sáu khía cạnh giúp phân biệt “Deep” data observability với “Shallow” data observability.
6 Trụ Cột Của Deep Data Observability
1. Nguồn Dữ Liệu: Thực Sự Toàn Diện
Các giải pháp shallow data observability có xu hướng chỉ tập trung vào kho dữ liệu thông qua các truy vấn SQL. Mặt khác, các giải pháp deep data observability cung cấp cho các nhóm dữ liệu mức độ hiển thị như nhau trên các luồng dữ liệu, hồ dữ liệu và kho dữ liệu. Có hai lý do tại sao điều này lại quan trọng:
Đầu tiên, dữ liệu không tự nhiên xuất hiện trong kho dữ liệu. Nó thường đi qua một nguồn streaming và nằm trong một hồ dữ liệu trước khi được đẩy đến kho dữ liệu. Dữ liệu xấu có thể xuất hiện ở bất kỳ đâu trên đường đi và bạn muốn xác định các vấn đề càng sớm càng tốt và xác định nguồn gốc của chúng.
Thứ hai, trong một lượng ngày càng nhiều trường hợp sử dụng dữ liệu như học máy và ra quyết định tự động, dữ liệu không bao giờ chạm vào kho dữ liệu. Để một công cụ data observability có tính chủ động và phù hợp với tương lai, nó cần phải thực sự toàn diện, cũng như trong hồ và luồng.

6 Trụ Cột Của Deep Data Observability
2. Định Dạng Dữ Liệu: Có Cấu Trúc Và Bán Cấu Trúc
Các luồng dữ liệu và hồ dữ liệu chuyển tiếp độc đáo sang phần tiếp theo: định dạng dữ liệu. Shallow data observability tập trung vào kho dữ liệu, nghĩa là nó thu được khả năng hiển thị cho dữ liệu có cấu trúc. Tuy nhiên, để đạt được mức độ hiển thị dữ liệu cao toàn diện trong ngăn xếp dữ liệu của bạn, giải pháp data observability phải hỗ trợ các định dạng dữ liệu phổ biến trong các luồng dữ liệu và hồ dữ liệu (và ngày càng nhiều kho dữ liệu). Với deep data observability, các nhóm dữ liệu có thể thu được dữ liệu chất lượng cao bằng cách theo dõi chất lượng dữ liệu không chỉ trong các tập dữ liệu có cấu trúc mà còn cho dữ liệu bán cấu trúc ở các định dạng lồng nhau, ví dụ: các khối JSON.
3. Mức Độ Chi Tiết Dữ Liệu: Xác Thực Đơn Biến Và Đa Biến Của Các Điểm Dữ Liệu Riêng Lẻ Và Dữ Liệu Tổng Hợp
Shallow data observability ban đầu nổi tiếng dựa trên việc phân tích thống kê một chiều (đơn biến) về dữ liệu tổng hợp (ví dụ: siêu dữ liệu). Ví dụ: xem xét số lượng giá trị null trung bình trong một cột.
Tuy nhiên, vô số trường hợp dữ liệu xấu đã cho chúng ta biết rằng các nhóm dữ liệu cần xác thực không chỉ thống kê tóm tắt và phân phối mà còn cả các điểm dữ liệu riêng lẻ. Ngoài ra, họ cần xem xét mối quan hệ phụ thuộc (đa biến) giữa các trường (hoặc cột) chứ không chỉ các trường riêng lẻ—dữ liệu trong thế giới thực có mối quan hệ phụ thuộc, vì vậy hầu hết các vấn đề về chất lượng dữ liệu đều có bản chất là đa biến. Deep data observability giúp các nhóm hướng dữ liệu thực hiện chính xác điều này: xác thực đơn biến và đa biến các điểm dữ liệu riêng lẻ và dữ liệu tổng hợp. Hãy xem xét một ví dụ về thời điểm cần xác thực đa biến.
Tập dữ liệu bên dưới được phân đoạn theo quốc gia và theo product_type (nhiều biến, không chỉ một), điều này là cần thiết để xác thực từng phân đoạn con riêng lẻ (tập hợp các bản ghi). Mỗi phân đoạn con có khả năng sẽ có khối lượng, độ tươi mới, bất thường và phân phối riêng biệt, có nghĩa là nó phải được xác thực riêng lẻ. Giả sử tập dữ liệu này theo dõi tất cả dữ liệu giao dịch từ một doanh nghiệp thương mại điện tử. Sau đó, mỗi quốc gia có khả năng sẽ hiển thị các hành vi mua hàng riêng lẻ, có nghĩa là chúng cần được xác thực riêng lẻ. Nhấp đúp chuột thêm một lần nữa, chúng ta cũng có thể thấy rằng trong mỗi quốc gia, mỗi product_type cũng phải tuân theo các hành vi mua hàng khác nhau. Do đó, chúng ta cần phân đoạn cả hai cột để xác thực dữ liệu một cách thực sự.
4. Cấu Hình Trình Xác Thực: Được Đề Xuất Tự Động Cũng Như Được Định Cấu Hình Thủ Công
Tùy thuộc vào tổ chức của bạn, bạn có thể đang tìm kiếm các mức độ khả năng mở rộng khác nhau trong hệ thống dữ liệu của mình. Ví dụ: giả sử bạn đang tìm kiếm một loại giải pháp “thiết lập và quên nó đi” sẽ cảnh báo bạn bất cứ khi nào có điều gì đó bất ngờ xảy ra; sau đó, shallow data observability là những gì bạn đang theo đuổi. Trong trường hợp đó, bạn sẽ có cái nhìn tổng quan về, ví dụ: tất cả các bảng trong kho dữ liệu của bạn và liệu chúng có hoạt động như mong đợi hay không.
Ngược lại, doanh nghiệp của bạn có thể có logic kinh doanh riêng hoặc các quy tắc xác thực tùy chỉnh mà bạn muốn thiết lập. Mức độ bạn có thể thực hiện thiết lập tùy chỉnh này theo cách có thể mở rộng sẽ quyết định mức độ bạn có deep data observability. Nếu mỗi quy tắc tùy chỉnh yêu cầu kỹ sư dữ liệu viết SQL, thì bạn đang xem xét một thiết lập không thể mở rộng và sẽ rất khó khăn để đạt được trạng thái deep data observability. Thay vào đó, nếu bạn có một menu trình xác thực nhanh chóng được triển khai có thể được kết hợp một cách phù hợp để phù hợp với doanh nghiệp của bạn, thì deep data observability sẽ nằm trong tầm tay. Việc thiết lập các trình xác thực tùy chỉnh không nên chỉ dành riêng cho các thành viên trong nhóm dữ liệu am hiểu về mã.
5. Xác Thực Đa Nhịp: Thường Xuyên Theo Nhu Cầu, Bao Gồm Cả Thời Gian Thực
Một lần nữa, tùy thuộc vào nhu cầu kinh doanh của bạn, bạn có thể có các yêu cầu khác nhau về data observability trên các chân trời thời gian khác nhau. Ví dụ: giả sử bạn sử dụng loại thiết lập tiêu chuẩn trong đó dữ liệu được tải vào kho của bạn hàng ngày. Trong trường hợp đó, shallow data observability, chỉ hỗ trợ nhịp độ hàng ngày tiêu chuẩn, đáp ứng nhu cầu của bạn.
Thay vào đó, nếu cơ sở hạ tầng dữ liệu của bạn phức tạp hơn, với một số nguồn được cập nhật trong thời gian thực, một số hàng ngày và một số khác ít thường xuyên hơn, bạn sẽ cần hỗ trợ để xác thực dữ liệu với tất cả các nhịp độ này. Nhu cầu đa nhịp độ này đặc biệt đúng đối với các công ty dựa vào bất kỳ loại dữ liệu nào để ra quyết định nhanh chóng hoặc các tính năng sản phẩm trong thời gian thực, ví dụ: định giá động, ứng dụng IoT, doanh nghiệp bán lẻ phụ thuộc nhiều vào tiếp thị kỹ thuật số, v.v. Nền tảng deep data observability có hỗ trợ đầy đủ để xác thực dữ liệu cho tất cả các trường hợp sử dụng này. Nó đảm bảo rằng bạn có được thông tin chi tiết về dữ liệu của mình vào đúng thời điểm theo bối cảnh kinh doanh của bạn. Điều đó cũng có nghĩa là bạn có thể hành động dựa trên dữ liệu xấu ngay khi nó xảy ra và trước khi nó ảnh hưởng đến các trường hợp sử dụng tiếp theo của bạn.
6. Trọng Tâm Người Dùng: Cả Kỹ Thuật Và Phi Kỹ Thuật
Chất lượng dữ liệu vốn dĩ là một vấn đề liên chức năng, đó là một phần lý do tại sao nó có thể khó giải quyết đến vậy. Ví dụ: người biết dữ liệu “tốt” trông như thế nào trong tập dữ liệu CRM có thể là một nhân viên bán hàng trực tiếp thực hiện các cuộc gọi bán hàng. Do đó, người di chuyển (hoặc nhập) dữ liệu từ hệ thống CRM vào kho dữ liệu có thể hoàn toàn không hiểu rõ về điều này và đương nhiên có thể quan tâm nhiều hơn đến việc liệu các đường ống dữ liệu có chạy theo lịch trình hay không.
Các giải pháp shallow data observability chủ yếu phục vụ cho một nhóm người dùng duy nhất. Chúng tập trung vào kỹ sư dữ liệu, người quan tâm nhất đến các yếu tố cơ bản của đường ống và liệu hệ thống có mở rộng quy mô hay không. Hoặc, chúng tập trung vào người dùng doanh nghiệp, những người có thể quan tâm nhất đến bảng điều khiển và thống kê tóm tắt.
Deep data observability đạt được khi cả hai loại người dùng đều được ghi nhớ. Trong thực tế, điều này có nghĩa là cung cấp nhiều chế độ kiểm soát nền tảng data observability: thông qua giao diện dòng lệnh và thông qua giao diện người dùng đồ họa. Nó cũng có thể bao gồm nhiều cấp độ truy cập và đặc quyền. Bằng cách này, tất cả người dùng có thể cộng tác để định cấu hình xác thực dữ liệu và có được mức độ hiển thị cao vào các đường ống dữ liệu. Điều này, đến lượt nó, sẽ dân chủ hóa hiệu quả chất lượng dữ liệu trong toàn bộ doanh nghiệp.