So sánh Kafka và Spark: 6 điểm khác nhau giữa Kafka và Spark

Kafka và Spark đều là hai công nghệ phổ biến được sử dụng trong việc xử lý và phân tích dữ liệu lớn. Chúng đều có vai trò quan trọng trong việc xây dựng hệ thống dữ liệu phân tán nhưng chúng chúng cũng có những đặc điểm riêng biệt. Cùng tìm hiểu sự khác biệt với Bizfly Cloud ngay sau đây!
Kafka là gì?
Kafka là một công cụ mạnh mẽ được nhiều doanh nghiệp lớn sử dụng để quản lý và xử lý dữ liệu theo thời gian thực. Với khả năng xử lý nhanh chóng và hiệu quả lượng lớn thông tin từ nhiều nguồn khác nhau, Kafka cung cấp giải pháp cho các khách hàng đa dạng. Tính năng chính của Kafka là khả năng xử lý dữ liệu theo thời gian thực từ khi được tạo ra, nhờ vào hệ thống nhật ký cam kết phân tán.
Ban đầu được phát triển bởi LinkedIn để xử lý 1,4 tỷ tin nhắn mỗi ngày, sau đó Kafka đã trở thành một công nghệ truyền dữ liệu nguồn mở mang lại nhiều ưu điểm so với các hệ thống nhắn tin thông thường.
Spark là gì?
Spark là một thành phần quan trọng của Apache Spark được sử dụng để xử lý dữ liệu theo thời gian thực. Với khả năng xử lý lượng lớn dữ liệu trong thời gian thực và phản hồi nhanh chóng, Spark giúp tăng cường hiệu suất cho các ứng dụng yêu cầu tính thời gian thực. Điểm mạnh của Spark là khả năng xử lý dữ liệu từ nhiều nguồn khác nhau và ánh xạ, lọc dữ liệu một cách linh hoạt.

Apache Spark là một framework tính toán phân tán mã nguồn mở
Điểm giống nhau giữa Kafka và Spark
Một số điểm tương đồng giữa Kafka và Spark bao gồm:
Xử lý dữ liệu lớn: Cả hai công cụ đều hỗ trợ xử lý khối lượng lớn dữ liệu trong thời gian thực. Kafka cung cấp đường ống dữ liệu phân tán trên nhiều máy chủ để nhập và xử lý dữ liệu liên tục, trong khi Spark cho phép xử lý dữ liệu trên quy mô lớn với các công cụ phân tích và xử lý thời gian thực.
Sự đa dạng dữ liệu: Cả Kafka và Spark đều hỗ trợ nhập dữ liệu phi cấu trúc, bán cấu trúc và có cấu trúc từ các nguồn khác nhau. Cả hai công cụ cũng hỗ trợ nhiều định dạng dữ liệu khác nhau như văn bản, JSON, XML và SQL.
Khả năng điều chỉnh quy mô: Cả Kafka và Spark đều cho phép điều chỉnh quy mô theo cả chiều dọc và chiều ngang. Kafka có thể thay đổi quy mô cao bằng cách thêm tài nguyên điện toán vào máy chủ lưu trữ, trong khi Spark sử dụng RDD để lưu trữ dữ liệu trên nhiều nút để xử lý song song.
So sánh Kafka và Spark: Điểm khác nhau
Kafka và Spark đều là những công nghệ cốt lõi trong hệ sinh thái xử lý dữ liệu lớn, nhưng được thiết kế cho các mục tiêu khác nhau. Nếu Kafka tập trung vào truyền tải và xử lý dữ liệu theo thời gian thực với độ trễ thấp, thì Spark lại mạnh về phân tích và xử lý dữ liệu phức tạp. Việc hiểu rõ sự khác biệt sẽ giúp lựa chọn đúng công nghệ cho từng bài toán cụ thể.
Chuyển đổi ETL
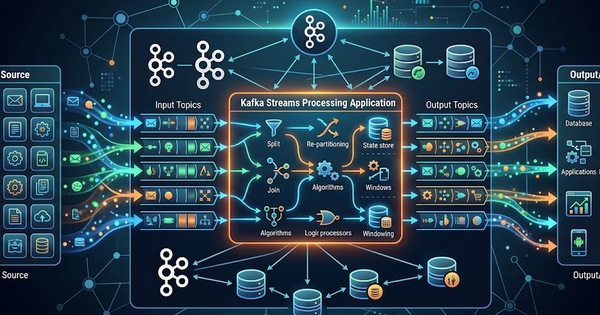
Spark là một phần của Apache Spark và cung cấp một bộ API phong phú cho các phép biến đổi ETL. Điều này giúp cho việc viết các phép biến đổi ETL phức tạp trên các luồng dữ liệu thời gian thực trở nên dễ dàng hơn bao giờ hết. Spark cho phép các nhà phát triển viết các phép biến đổi ETL bằng cách sử dụng các API quen thuộc của Apache Spark như lọc, ánh xạ, tổng hợp và nối các luồng dữ liệu theo thời gian thực.
Mặt khác, Kafka cung cấp một mô hình lập trình đơn giản để chuyển đổi luồng dữ liệu. Nó cung cấp DSL (Ngôn ngữ dành riêng cho miền) để xác định cấu trúc liên kết xử lý, giúp dễ dàng xác định các phép biến đổi ETL. Tuy nhiên, DSL không mạnh bằng API Spark và nó có thể không phù hợp với các phép biến đổi ETL phức tạp.
Độ trễ
Độ trễ là yếu tố quan trọng cần cân nhắc khi xử lý dữ liệu theo thời gian thực. Dữ liệu được xử lý trong Spark theo từng đợt nhỏ đều đặn bằng phương pháp xử lý theo từng đợt nhỏ. Độ trễ của Spark phụ thuộc vào khoảng thời gian của đợt, có thể được đặt ở mức thấp nhất là 100 mili giây. Do đó, Spark hoàn hảo cho các ứng dụng cần độ trễ thấp, tuy nhiên độ trễ có thể không thấp bằng các giải pháp xử lý thời gian thực khác.
Mặt khác, Kafka cung cấp độ trễ rất thấp vì nó xử lý dữ liệu ngay khi nó đến. Dữ liệu được phân chia cho một số nút trong cụm Kafka trong kiến trúc xử lý phân tán được Kafka sử dụng. Do độ trễ cực thấp được tạo ra bởi điều này, Luồng Kafka có thể xử lý dữ liệu song song.
Loại xử lý
Một điểm khác biệt quan trọng giữa Spark và Kafka là kiểu xử lý dữ liệu. Spark sử dụng phương pháp xử lý theo lô nhỏ, tức là dữ liệu được xử lý theo từng đợt nhỏ đều đặn. Điều này giúp Spark có khả năng chịu lỗi tốt và dễ dàng phục hồi sau khi xảy ra lỗi. Tuy nhiên, cách tiếp cận này có thể không phù hợp với các ứng dụng yêu cầu độ trễ thấp.
Trái lại, Kafka là công cụ xử lý liên tục bắt đầu xử lý dữ liệu ngay khi nhận được. Mặc dù có độ trễ cực thấp, phương pháp này có thể không có khả năng chịu lỗi như Spark. Do đó, việc lựa chọn giữa Spark và Kafka cũng phụ thuộc vào yêu cầu cụ thể của dự án.
Ngôn ngữ được hỗ trợ
Spark cung cấp API cho các ngôn ngữ lập trình phổ biến như Java, Scala và Python, giúp các nhà phát triển dễ dàng viết mã bằng ngôn ngữ ưa thích của họ. Điều này giúp tận dụng các kỹ năng và chuyên môn hiện có của nhà phát triển.
Kafka cung cấp DSL dựa trên Java để xác định cấu trúc liên kết xử lý. Mặc dù có thể sử dụng các ngôn ngữ lập trình khác với Kafka, nhưng việc này có thể đòi hỏi thêm nỗ lực và thời gian để thích nghi với DSL của Kafka.
Quản lý bộ nhớ
Trong việc quản lý bộ nhớ, Spark sử dụng mô hình xử lý theo đợt, giúp quản lý bộ nhớ hiệu quả bằng cách xử lý song song nhiều lô dữ liệu. Spark cũng cung cấp hỗ trợ tích hợp để quản lý bộ nhớ, giúp nhà phát triển điều chỉnh cài đặt bộ nhớ để có hiệu suất tối ưu.
Ngược lại, dữ liệu được xử lý ngay lập tức khi đến với mô hình xử lý liên tục của Kafka. Điều này yêu cầu một chiến lược quản lý bộ nhớ riêng biệt, và các nhà phát triển cần điều chỉnh cài đặt bộ nhớ để đạt hiệu suất tối ưu với tính năng hỗ trợ quản lý bộ nhớ tích hợp của Kafka.
Quy trình làm việc
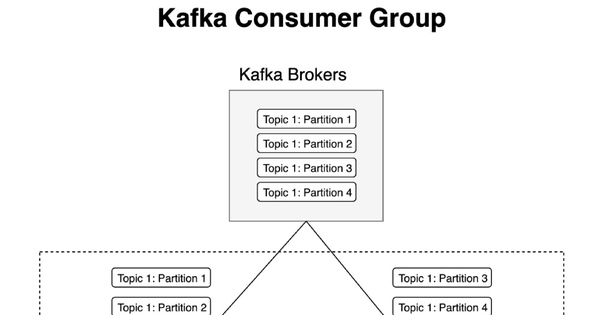
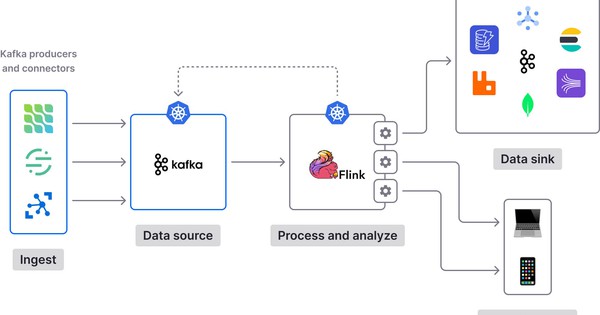
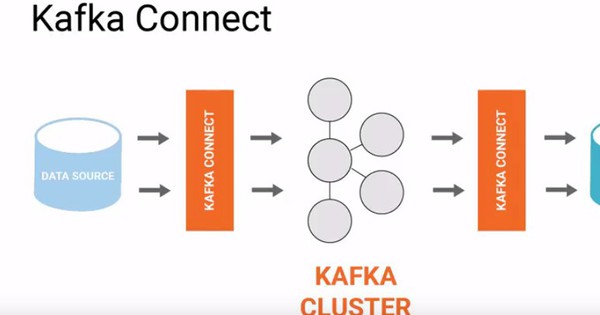
Kafka là một hệ thống xử lý dữ liệu dạng message queue, được sử dụng để lưu trữ và truyền tải dữ liệu giữa các ứng dụng. Quy trình làm việc của Kafka bao gồm các bước như producer gửi message vào Kafka, Kafka lưu trữ message vào các topic, và consumer đọc message từ Kafka để xử lý. Kafka được sử dụng phổ biến trong việc xây dựng hệ thống real-time và xử lý dữ liệu lớn.
Spark là một framework xử lý dữ liệu lớn, được sử dụng để xử lý và phân tích dữ liệu trên một cụm máy tính. Quy trình làm việc của Spark bao gồm các bước như load dữ liệu từ nguồn, xử lý dữ liệu bằng các transformation và action, và lưu trữ kết quả vào các hệ thống lưu trữ dữ liệu như HDFS hoặc database. Spark cung cấp các API linh hoạt cho việc xử lý dữ liệu batch và streaming.
>> Có thể bạn quan tâm: So sánh Kafka và Redis
Dịch vụ Kafka của Bizfly Cloud – Giải pháp streaming dữ liệu real-time toàn diện
Đối với doanh nghiệp đang triển khai hệ thống xử lý dữ liệu thời gian thực, việc tự vận hành Kafka thường đi kèm với nhiều thách thức về hạ tầng, scaling và monitoring. Kafka của Bizfly Cloud được xây dựng nhằm giải quyết trực tiếp các bài toán này, giúp doanh nghiệp triển khai nhanh chóng mà không cần đầu tư sâu vào vận hành.
Nền tảng cung cấp Kafka dạng managed service, cho phép tự động hóa các tác vụ như khởi tạo cluster, mở rộng tài nguyên, cân bằng tải và giám sát hệ thống theo thời gian thực. Nhờ đó, đội ngũ kỹ thuật có thể tập trung vào phát triển ứng dụng thay vì quản lý hạ tầng phức tạp.
Một số lợi thế nổi bật:
- Triển khai nhanh: Tạo cluster Kafka chỉ trong vài phút
- Tự động scale: Linh hoạt mở rộng theo lưu lượng dữ liệu thực tế
- Độ ổn định cao: Hạ tầng tối ưu cho workload streaming liên tục
- Tích hợp hệ sinh thái Cloud: Kết nối dễ dàng với hệ thống dữ liệu, AI và analytics
Với Bizfly Cloud Kafka, doanh nghiệp có thể xây dựng pipeline dữ liệu real-time, hệ thống event-driven hoặc nền tảng streaming analytics một cách hiệu quả, ổn định và sẵn sàng mở rộng trong tương lai.
Kết luận
Qua bài viết trên, chúng ta đã điểm qua 6 điểm khác nhau quan trọng giữa Apache Kafka và Apache Spark. Mặc dù cả hai công nghệ này đều đóng vai trò quan trọng trong việc xử lý dữ liệu lớn, nhưng sự khác biệt về cấu trúc và mục đích sử dụng của họ đã giúp họ phục vụ cho các mục tiêu và nhu cầu công việc khác nhau. Việc lựa chọn sử dụng Kafka hay Spark phụ thuộc vào nhu cầu và yêu cầu cụ thể của từng dự án.