High Cardinality là gì? Đặc điểm của High Cardinality
Khái niệm High Cardinality thường xuất hiện trong các cột dữ liệu có giá trị độc nhất vô nhị, đặc biệt trong lĩnh vực dữ liệu chuỗi thời gian. Bài viết này Bizfly Cloud sẽ giải thích rõ hơn về High Cardinality và cách mà các cơ sở dữ liệu quan hệ xử lý vấn đề này.
Định Nghĩa High Cardinality là gì
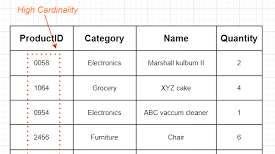
High Cardinality ám chỉ các cột có giá trị rất hiếm gặp hoặc duy nhất. Các giá trị cột High Cardinality thường là số định danh, địa chỉ email, hoặc tên người dùng. Ví dụ, một cột trong bảng dữ liệu có High Cardinality có thể là bảng NGƯỜI DÙNG với cột có tên USER_ID. Cột này sẽ chứa các giá trị duy nhất từ 1 đến n. Mỗi khi một người dùng mới được tạo trong bảng NGƯỜI DÙNG, một số mới sẽ được tạo trong cột USER_ID để xác định họ một cách duy nhất. Bởi vì các giá trị trong cột USER_ID là duy nhất, loại Cardinality của cột này sẽ được gọi là High Cardinality.

Định Nghĩa High Cardinality là gì
Nếu bạn đang làm việc với cơ sở dữ liệu, đặc biệt là dữ liệu chuỗi thời gian, thì bạn có thể đã gặp phải thách thức khi xử lý dữ liệu có High Cardinality.
Cụ thể, High Cardinality trong dữ liệu chuỗi thời gian là một vấn đề phổ biến trong IoT công nghiệp (ví dụ: sản xuất, dầu và khí, tiện ích, v.v.), cũng như một số công việc giám sát và sự kiện dữ liệu.
High Cardinality cũng là chủ đề mà các nhà phát triển thường xuyên thảo luận, và thường có nhiều câu hỏi xoay quanh nó.
Để làm sáng tỏ một điểm nhầm lẫn thường gặp: High Cardinality chỉ trở thành vấn đề lớn trong thế giới dữ liệu chuỗi thời gian do hạn chế của một số cơ sở dữ liệu chuỗi thời gian phổ biến. Trên thực tế, dữ liệu có High Cardinality thực sự là một vấn đề đã được giải quyết, nếu chọn đúng cơ sở dữ liệu.
Hãy quay lại một chút và định nghĩa trước về High Cardinality.
Đặc Điểm Của High Cardinality
Nói chung, Cardinality chỉ số lượng giá trị trong một tập hợp. Đôi khi Cardinality của tập hợp của bạn là nhỏ (High Cardinality thấp), và đôi khi nó có thể lớn (High Cardinality). Ví dụ, có khá nhiều (ngon lành) M&Ms trong hình ảnh phía trên, nhưng High Cardinality của tập dữ liệu đó là khá nhỏ (6):
Trong thế giới cơ sở dữ liệu, Cardinality chỉ số lượng giá trị duy nhất chứa trong một cột cụ thể, hoặc trường, của một cơ sở dữ liệu.
Tuy nhiên, với dữ liệu chuỗi thời gian, mọi thứ trở nên phức tạp hơn.
Dữ liệu chuỗi thời gian thường được kết hợp với metadata (đôi khi được gọi là “tags”) mô tả dữ liệu đó. Thường thì dữ liệu chuỗi thời gian chính hoặc metadata được lập chỉ mục để cải thiện hiệu suất truy vấn nhanh hơn, để bạn có thể nhanh chóng tìm thấy các giá trị phù hợp với tất cả tags đã chỉ định.
Cardinality của một tập dữ liệu chuỗi thời gian thường được xác định bởi tích chéo của Cardinality của mỗi cột được lập chỉ mục riêng lẻ. Vậy nếu có 6 màu của M&Ms, nhưng cũng có 5 loại M&Ms (plain, peanut, almond, pretzel, và crispy), sau High Cardinality của chúng ta bây giờ là 6x5 = 30 tổng số tùy chọn cho M&Ms. Việc có chỉ mục phù hợp sẽ sau đó cho phép chúng ta hiệu quả tìm kiếm tất cả M&Ms màu xanh, giòn (đó là những cái tốt nhất một cách chủ quan).
Nếu bạn có nhiều cột được lập chỉ mục, mỗi cột có một số lượng lớn giá trị duy nhất, thì Cardinality của tích chéo đó có thể trở nên rất lớn. Đó là điều mà các nhà phát triển phần mềm thường ý nghĩa khi họ nói về một tập dữ liệu chuỗi thời gian có “High Cardinality”.
Hãy xem xét một ví dụ.
Ví Dụ Về High Cardinality: IoT Công Nghiệp
Tưởng tượng một kịch bản IoT nơi có những máy móc lớn, nặng đang khai thác đá, nghiền đá, và phân loại đá trong một mỏ đá cụ thể.
Giả sử có 10,000 máy móc, mỗi máy có 100 cảm biến, chạy 10 phiên bản firmware khác nhau, được phân bổ trên 100 địa điểm:
timestamp | temperature | mem_free | equipment_id | sensor_id | firmware_version | site_id | (lat,long) |
2019-04-04 09:00:00 | 85.2 | 10.2 | 1 | 98 | 1.0 | 4 | (x,y) |
2019-04-04 09:00:00 | 68.8 | 16.0 | 72 | 12 | 1.1 | 20 | (x1,y1) |
2019-04-04 09:00:00 | 100.0 | 0.0 | 34 | 58 | 2.1 | 55 | (x2,y2) |
2019-04-04 09:00:00 | 84.8 | 9.8 | 12 | 75 | 1.4 | 81 | (x3,y3) |
2019-04-04 09:00:00 | 68.7 | 16.0 | 89 | 4 | 2.1 | 13 | (x4,y4) |
... |
|
|
|
|
|
|
|
Cardinality tối đa của tập dữ liệu này sau đó trở thành 1 tỷ [10,000 x 100 x 10 x 100].
Bây giờ hãy tưởng tượng rằng các thiết bị có thể di chuyển cũng như vậy, và chúng tôi muốn lưu trữ vị trí GPS chính xác (lat, long) và sử dụng nó như metadata được lập chỉ mục để truy vấn theo. Bởi vì (lat, long) là một trường liên tục (trái ngược với trường rời rạc như equipment_id), bằng cách lập chỉ mục dựa trên vị trí, Cardinality tối đa của tập dữ liệu này bây giờ là vô hạn (không giới hạn).
Cơ Sở Dữ Liệu Quan Hệ Xử Lý High Cardinality Như Thế Nào
Các cơ sở dữ liệu khác nhau có cách tiếp cận khác nhau để xử lý High Cardinality. Cuối cùng, hiệu suất của cơ sở dữ liệu khi làm việc với tập dữ liệu có High Cardinality có thể được truy xuất lại cách nó được thiết kế từ đầu.
Nếu bạn đang làm việc với nhiều dữ liệu chuỗi thời gian và sử dụng cơ sở dữ liệu quan hệ, một cấu trúc dữ liệu đã được chứng minh cho việc lập chỉ mục dữ liệu là cấu trúc dữ liệu B-tree.
Dựa vào cấu trúc dữ liệu B-tree cho việc lập chỉ mục dữ liệu có một số lợi ích đối với tập dữ liệu có High Cardinality:
Bạn có thể đạt được sự hiểu rõ về hiệu suất của cơ sở dữ liệu. Miễn là chỉ mục và dữ liệu của tập dữ liệu bạn muốn truy vấn vừa với bộ nhớ, điều này là một thứ có thể được điều chỉnh, High Cardinality trở thành một vấn đề không đáng kể.
Bạn có quyền kiểm soát việc lập chỉ mục cho các cột, bao gồm khả năng tạo chỉ mục ghép trên nhiều cột. Bạn cũng có thể thêm hoặc xóa chỉ mục bất cứ lúc nào bạn muốn, ví dụ, nếu công việc truy vấn của bạn thay đổi.
Bạn có thể tạo chỉ mục trên các trường rời rạc và liên tục, đặc biệt vì B-trees làm việc tốt đối với việc so sánh sử dụng bất kỳ toán tử sau: <, <=, =, >=, >, BETWEEN, IN, IS NULL, IS NOT NULL. Các truy vấn ví dụ từ trên (“SELECT * FROM sensor_data WHERE mem_free = 0” và “SELECT * FROM sensor_data WHERE temperature > 90”) sẽ chạy trong thời gian logarit, hoặc O(log n).
Mặc dù có những cách tiếp cận khác mà các cơ sở dữ liệu chuỗi thời gian sử dụng cho High Cardinality, sử dụng cấu trúc B-tree đã chứng minh là đáng tin cậy. (Để biết thêm về cách so sánh hai cơ sở dữ liệu chuỗi thời gian phổ biến, nhấn vào đây.)