Kiến trúc các Kubernetes cluster - chọn chiến lược tự động mở rộng tốt nhất

Mở rộng quy mô các pod và node trong một Kubernetes cluster có thể mất vài phút với cài đặt mặc định. Hãy cùng Bizfly Cloud tìm hiểu cách định kích thước các cluster node, định cấu hình Horizontal và Cluster Autoscaler, cũng như giám sát quá mức cluster của bạn để mở rộng quy mô nhanh hơn.
Trong Kubernetes, một số thứ được gọi là "auto scaling", bao gồm:
- Horizontal Pod Autoscaler
- Vertical Pod Autoscaler
- Cluster Autoscaler
Các autoscaler đó thuộc các danh mục khác nhau vì chúng giải quyết các vấn đề khác.
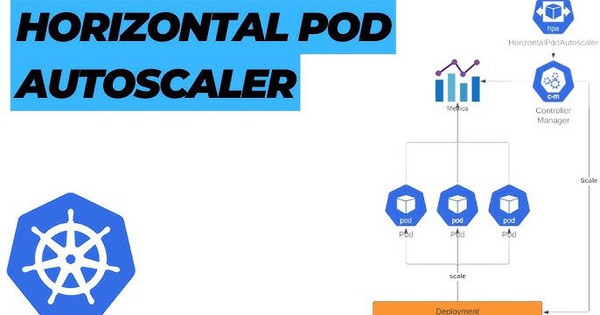
Tính năng Horizontal Pod Autoscaler - Điều chỉnh quy mô theo chiều ngang (HPA) được thiết kế để tăng các replica trong quá trình triển khai của bạn. Khi ứng dụng của bạn nhận được nhiều lưu lượng truy cập hơn, bạn có thể yêu cầu autoscaler điều chỉnh số lượng các replica để xử lý nhiều yêu cầu hơn.
Tính năng Vertical Pod Autoscaler - Điều chỉnh quy mô theo chiều dọc (VPA) hữu ích khi bạn không thể tạo thêm bản sao các Pod của mình, nhưng bạn vẫn cần xử lý thêm lưu lượng truy cập. Ví dụ: bạn không thể mở rộng cơ sở dữ liệu (dễ dàng) chỉ bằng cách thêm nhiều Pod hơn. Cơ sở dữ liệu có thể yêu cầu phân biệt hoặc định cấu hình các replica chỉ đọc (read-only). Nhưng bạn có thể làm cho một cơ sở dữ liệu xử lý nhiều kết nối hơn bằng cách tăng bộ nhớ và CPU có sẵn cho nó. Đó chính xác là mục đích của Vertical Pod Autoscaler - tăng kích thước của Pod.
Cuối cùng là Cluster Autoscaler (CA). Khi cluster của bạn sắp hết tài nguyên, Cluster Autoscaler cung cấp một đơn vị tính toán mới và thêm nó vào cluster. Nếu có quá nhiều node trống, Cluster Autoscaler sẽ loại bỏ chúng để giảm chi phí.
Các thành phần này đều "autoscale" một cái gì đó nhưng chúng hoàn toàn không liên quan đến nhau. Tất cả đều giải quyết các trường hợp sử dụng rất khác nhau và sử dụng các concept và cơ chế khác. Chúng được phát triển trong các dự án riêng biệt và có thể được sử dụng độc lập với nhau.
Tuy nhiên, việc mở rộng cluster của bạn yêu cầu tinh chỉnh cài đặt của các autoscaler để chúng hoạt động đồng bộ.
Khi autoscaling pod gặp sự cố
Hãy tưởng tượng có một ứng dụng yêu cầu sử dụng 1,5GB bộ nhớ và 0,25 vCPU mọi lúc.
Bạn đã cung cấp một cluster với một node duy nhất 8GB và 2 vCPU - nó sẽ có thể phù hợp với bốn nhóm một cách hoàn hảo (và còn lại một chút không gian).

Bạn triển khai một Pod duy nhất và thiết lập:
- Một Horizontal Pod Autoscaler thêm một replica sau mỗi 10 request đến (tức là nếu bạn có 40 request đồng thời, nó sẽ mở rộng thành 4 replica).
- Một Cluster Autoscaler để tạo thêm các node khi tài nguyên gần hết.
Horizontal Pod Autoscaler có thể mở rộng quy mô các replica trong quá trình triển khai bằng cách sử dụng các Chỉ số tùy chỉnh (Custom Metrics), chẳng hạn như truy vấn mỗi giây (QPS) từ Ingress controller.
Bạn bắt đầu điều khiển lưu lượng truy cập 30 request đồng thời đến cluster của bạn và quan sát những điều sau:
- Horizontal Pod Autoscaler bắt đầu mở rộng các Pod.
- Hai Pod khác được tạo ra.
- Các Cluster Autoscaler không kích hoạt - không có nút mới được tạo ra trong cluster.
Nó có ý nghĩa vì có đủ không gian cho một Pod nữa trong node đó.
Bạn tiếp tục tăng lưu lượng truy cập lên 40 request đồng thời và quan sát lại:
- Tính năng Horizontal Pod Autoscaler tạo thêm một Pod nữa.
- Pod đang chờ xử lý và không thể được triển khai.
- Các Cluster Autoscaler trigger tạo ra một node mới.
- Node được cung cấp sau 4 phút. Sau đó, Pod đang chờ xử lý sẽ được triển khai.
Tại sao Pod thứ tư không được triển khai trong node đầu tiên?
Các node được triển khai trong Kubernetes cluster của bạn tiêu thụ các tài nguyên như bộ nhớ, CPU và bộ nhớ. Tuy nhiên, trên cùng một node, hệ điều hành và kubelet cũng yêu cầu bộ nhớ và CPU. Trong bộ nhớ và CPU của Kubernetes worker node được chia thành:
- Các tài nguyên cần thiết để chạy hệ điều hành và các daemon hệ thống như SSH, systemd, v.v.
- Các tài nguyên cần thiết để chạy các Kubernetes agent như Kubelet, container runtime, trình phát hiện sự cố node, v.v.
- Tài nguyên có sẵn cho Pods.
- Các tài nguyên dành riêng cho ngưỡng loại bỏ.

Như bạn có thể đoán, tất cả các hạn ngạch đó đều có thể tùy chỉnh, nhưng bạn cần tính toán cho chúng. Trong một máy ảo 8GB và 2 vCPU, bạn có thể mong đợi:
- 100MB bộ nhớ và 0.1 vCPU sẽ được dành riêng cho hệ điều hành.
- Bộ nhớ 1.8GB và 0.07 vCPU sẽ được dành riêng cho Kubelet.
- 100 MB bộ nhớ cho ngưỡng loại bỏ.
Bộ nhớ còn lại ~ 6GB và 1,83 vCPU có thể sử dụng được bởi Pod.
Nếu cluster chạy DaemonSet chẳng hạn như kube-proxy, bạn nên giảm thêm bộ nhớ và CPU khả dụng. Xem xét kube-proxy có yêu cầu 128MB và 0.1 vCPU, chỉ ~ 5.9GB bộ nhớ và 1.73 vCPU khả dụng để chạy các Pod. Chạy CNI như Flannel và log collector như Fluentd sẽ làm giảm thêm lượng tài nguyên của bạn.
Sau khi tính toán tất cả các tài nguyên bổ sung, bạn chỉ còn lại khoảng trống cho ba pod.
OS 100MB, 0.1 vCPU +
Kubelet 1.8GB, 0.07 vCPU +
Eviction threshold 100MB, 0 vCPU +
Daemonsets 128MB, 0.1 vCPU +
======================================
Used 2.1GB, 0.27 vCPU
======================================
Available to Pods 5.9GB, 1.73 vCPU
Pod requests 1.5GB, 0.25 vCPU
======================================
Total (4 Pods) 6GB, 1vCPU
Node thứ tư vẫn "Pending" trừ khi nó có thể được triển khai trên một node khác.
Vì Cluster Autoscaler biết rằng không có không gian cho Pod thứ tư, tại sao nó không cung cấp một node mới? Tại sao nó đợi Pod đang chờ xử lý trước khi nó kích hoạt tạo node?
Cách hoạt động của Cluster Autoscaler trong Kubernetes
Cluster Autoscaler không xem xét bộ nhớ hoặc CPU khả dụng khi nó kích hoạt tính năng tự động. Thay vào đó, Cluster Autoscaler phản ứng với các event và kiểm tra mọi Pod không thể lập lịch sau mỗi 10 giây. Một pod không thể lên lịch khi scheduler không thể tìm thấy một node có thể chứa nó.
Ví dụ: khi một Pod yêu cầu 1 vCPU nhưng cluster chỉ có sẵn 0.5 vCPU, scheduler đánh dấu Pod là không thể lên lịch.
Đó là khi Cluster Autoscaler bắt đầu tạo một node mới.
Cluster Autoscaler quét cluster hiện tại và kiểm tra xem có bất kỳ pod nào trong số các node không thể lập lịch trình phù hợp với một node mới hay không. Nếu bạn có một cluster với một số loại node (thường còn được gọi là các node group hoặc các node pool), Cluster Autoscaler sẽ chọn một trong số chúng bằng cách sử dụng các chiến lược sau:
- Ngẫu nhiên - chọn ngẫu nhiên một loại node. Đây là chiến lược mặc định.
- Hầu hết các pod - chọn node group sẽ lên lịch cho nhiều pod nhất.
- Ít lãng phí nhất - chọn node group có CPU nhàn rỗi nhất sau khi mở rộng quy mô.
- Giá - chọn node group nào có chi phí thấp nhất (chỉ hoạt động cho GCP tại thời điểm này).
- Mức độ ưu tiên - chọn node group có mức độ ưu tiên cao nhất (và bạn chỉ định mức độ ưu tiên theo cách thủ công).
Khi loại node được xác định, Cluster Autoscaler sẽ gọi API có liên quan để cung cấp tài nguyên tính toán mới. Có thể mất một khoảng thời gian trước khi các node đã tạo xuất hiện trong Kubernetes. Khi tài nguyên máy tính đã sẵn sàng, node được khởi tạo và thêm vào cluster nơi có thể triển khai các Pod chưa được lập lịch.
Thật không may, việc cung cấp các node mới thường chậm. Có thể mất vài phút để cung cấp một đơn vị tính toán mới. Nhưng chúng ta hãy đi sâu vào các con số.
Khám phá thời gian sản xuất tự động mở rộng pod
Thời gian cần thiết để tạo một Pod mới trên một Node mới được xác định bởi bốn yếu tố chính:
- Thời gian phản ứng của Horizontal Pod Autoscaler.
- Thời gian phản ứng của Cluster Autoscaler.
- Thời gian cung cấp node.
- Thời gian tạo pod.
Theo mặc định, việc sử dụng CPU và bộ nhớ của pod sẽ được kubelet loại bỏ sau mỗi 10 giây. Mỗi phút, Metrics Server sẽ tổng hợp các số liệu đó và hiển thị chúng với phần còn lại của Kubernetes API. Bộ điều khiển Horizontal Pod Autoscaler chịu trách nhiệm kiểm tra các chỉ số và quyết định tăng hoặc giảm quy mô replica của bạn.
Theo mặc định, Horizontal Pod Autoscaler sẽ kiểm tra các chỉ số của Pod sau mỗi 15 giây. Trong trường hợp xấu nhất, Horizontal Pod Autoscaler có thể mất tới 1 phút rưỡi để kích hoạt tính năng tự động chỉnh tỷ lệ (tức là 10 giây + 60 giây + 15 giây).

Cluster Autoscaler kiểm tra các Pod không thể lên lịch trong cụm 10 giây một lần. Khi một hoặc nhiều Pod được phát hiện, nó sẽ chạy một thuật toán để quyết định:
- Cần có bao nhiêu node để triển khai tất cả các Pod đang chờ xử lý.
- Loại nhóm node nào nên được tạo.
Toàn bộ quá trình sẽ diễn ra:
- Không quá 30 giây trên các cluster có ít hơn 100 node với tối đa 30 mỗi pod. Độ trễ trung bình sẽ là khoảng 5 giây.
- Không quá 60 giây trên cluster có 100 đến 1000 node. Độ trễ trung bình sẽ là khoảng 15 giây.

Sau đó, là thời gian cung cấp Node, phụ thuộc chủ yếu vào nhà cung cấp đám mây.
Đó là tiêu chuẩn cho một tài nguyên máy tính mới sẽ được cung cấp trong 3 đến 5 phút.

Cuối cùng, Pod phải được tạo bởi container runtime.
Việc khởi chạy container sẽ không mất quá vài mili giây nhưng việc tải xuống container image có thể mất vài giây.
Nếu bạn không lưu vào bộ nhớ đệm container image của mình, việc tải xuống image từ container registry có thể mất từ vài giây đến một phút, tùy thuộc vào kích thước và số lượng layer.

Vì vậy, tổng thời gian để kích hoạt tính năng autoscaling khi không có khoảng trống trong cluster hiện tại là:
Tính năng Horizontal Pod Autoscaler có thể mất tới 1 phút 30 giây để tăng số lượng replica.
Cluster Autoscaler sẽ mất ít hơn 30 giây cho một cluster có ít hơn 100 node và ít hơn một phút cho một cluster có hơn 100 node.
Nhà cung cấp dịch vụ đám mây có thể mất 3 đến 5 phút để tạo tài nguyên máy tính.
Container runtime có thể mất tới 30 giây để tải xuống container image.
Trong trường hợp tệ hơn, với một cluster nhỏ, bạn có:
HPA delay: 1m30s +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m30s
Với một cụm có hơn 100 node, tổng thời gian trễ có thể lên đến 7 phút.
Bạn có bằng lòng đợi 7 phút trước khi có thêm các Pod để xử lý lưu lượng truy cập tăng đột biến không? Làm thế nào bạn có thể điều chỉnh tự động thay đổi tỷ lệ để giảm thời gian mở rộng 7 phút nếu bạn cần một node mới?
Bạn có thể thay đổi:
- Thời gian làm mới cho Horizontal Pod Autoscaler (được điều khiển bởi --horizontal-pod-autoscaler-sync-period, mặc định là 15 giây).
- Khoảng thời gian để rà soát số liệu trong Metrics Server (được kiểm soát bởi metric-resolution, mặc định là 60 giây).
- Tần suất cluster autoscaler quét tìm các Pod không được lên lịch (do scan-interval điều khiển , mặc định là 10 giây).
- Cách bạn lưu image vào bộ nhớ cache trên node cục bộ (với một công cụ như kube-fledged).
Nhưng ngay cả khi bạn đã điều chỉnh các cài đặt đó ở một số nhỏ, bạn vẫn sẽ bị giới hạn bởi thời gian cấp phép của nhà cung cấp dịch vụ đám mây.
Vậy, làm thế nào bạn có thể sửa chữa điều đó?
Vì bạn không thể thay đổi thời gian cấp phép, bạn sẽ cần một giải pháp thay thế lần này. Bạn có thể thử hai điều:
- Tránh tạo các node mới nếu có thể.
- Tạo các node một cách chủ động để chúng đã được cấp phép khi bạn cần.
Chúng ta hãy xem xét các tùy chọn tại một thời điểm.
Chọn kích thước tiến trình tối ưu cho Kubernetes node
Việc chọn loại phiên bản phù hợp cho cluster của bạn có hậu quả đáng kể đối với chiến lược mở rộng quy mô của bạn.
Hãy xem xét tình huống sau.
Bạn có một ứng dụng yêu cầu bộ nhớ 1GB và 0.1 vCPU. Bạn cung cấp một node có bộ nhớ 4GB và 1 vCPU. Sau khi dự trữ bộ nhớ và CPU cho kubelet, hệ điều hành và ngưỡng loại bỏ, bạn còn lại ~ 2.5GB bộ nhớ và 0.7 vCPU có thể được sử dụng để chạy các Pod.

Node của bạn chỉ có không gian cho hai Pod. Mỗi khi bạn mở rộng quy mô các replica của mình, bạn có thể phải chịu sự chậm trễ lên đến 7 phút (thời gian dẫn để kích hoạt Horizontal Pod Autoscaler, Cluster Autoscaler, và cung cấp tài nguyên tính toán trên nhà cung cấp đám mây).
Hãy xem điều gì sẽ xảy ra nếu bạn quyết định sử dụng bộ nhớ 64GB và nút 16 vCPU thay thế.
Sau khi dự trữ bộ nhớ và CPU cho kubelet, hệ điều hành và ngưỡng loại bỏ, bạn còn lại ~ 58.32GB bộ nhớ và 15.8 vCPU có thể được sử dụng để chạy Pod.
Không gian có sẵn có thể lưu trữ 58 Pod và bạn có thể chỉ cần một node mới khi bạn có hơn 58 replica.

Ngoài ra, mỗi khi một node được thêm vào cluster, một số pod có thể được triển khai.
Có ít cơ hội để kích hoạt lại Cluster Autoscaler (và cung cấp các đơn vị tính toán mới trên nhà cung cấp đám mây).
Chọn các loại tiến trình lớn cũng có một lợi ích khác.
Tỷ lệ giữa tài nguyên dành riêng cho Kubelet, hệ điều hành, ngưỡng loại bỏ và tài nguyên có sẵn để chạy Pod lớn hơn.
Hãy xem biểu đồ này cho thấy bộ nhớ có sẵn cho các pod.

Khi kích thước tiến trình tăng lên, bạn có thể nhận thấy rằng (theo tỷ lệ) các tài nguyên có sẵn cho các pod tăng lên. Nói cách khác, bạn đang sử dụng tài nguyên của mình hiệu quả hơn là có hai tiến trình có kích thước bằng một nửa.
Bạn có nên chọn tiến trình lớn nhất mọi lúc?
Một số nhà cung cấp đám mây giới hạn số lượng Pod là 110 (tức là GKE). Những người khác có các giới hạn do mạng bên dưới quy định trên cơ sở từng trường hợp.
Và việc chọn một kiểu tiến trình lớn hơn không phải lúc nào cũng là một lựa chọn tốt.
Bạn cũng nên xem xét:
- Blast radius - nếu bạn chỉ có một vài node, thì tác động của một node bị lỗi sẽ lớn hơn nếu bạn có nhiều node.
- Tính năng autoscaling ít hiệu quả hơn về chi phí vì bước tăng tiếp theo là một node (rất) lớn.
Giả sử bạn đã chọn đúng loại tiến trình cho cluster của mình, bạn vẫn có thể gặp phải sự chậm trễ trong việc cung cấp đơn vị tính toán mới.
Làm thế nào bạn có thể giải quyết vấn đề đó?
Điều gì sẽ xảy ra nếu thay vì tạo một node mới khi đã đến lúc mở rộng quy mô, bạn tạo cùng một node trước thời hạn?
Dự phòng nút trong cụm Kubernetes
Nếu bạn có đủ khả năng để luôn có sẵn một node dự phòng, bạn có thể:
- Tạo một node và để trống.
- Ngay sau khi có một Pod trong node trống, bạn tạo một node trống khác.
Nói cách khác, bạn dạy cho autoscaler luôn có một node trống dự phòng nếu bạn cần scale.
Đó là một sự đánh đổi: bạn phải trả thêm chi phí (một đơn vị tính toán trống luôn có sẵn), nhưng bạn đạt được tốc độ. Với chiến lược này, bạn có thể mở rộng quy mô nhanh hơn nhiều.
Tin xấu là Cluster Autoscaler không được tích hợp sẵn chức năng này. Nó không thể được cấu hình để chủ động và không có flag để "luôn cung cấp một node trống".
Tin tốt là bạn vẫn có thể giả mạo nó. Bạn có thể chạy Deployment với đủ yêu cầu để đặt trước toàn bộ node. Bạn có thể nghĩ về pod này như một trình giữ chỗ - có nghĩa là dành không gian, không sử dụng bất kỳ tài nguyên nào. Ngay sau khi một Pod thực được tạo, bạn có thể loại bỏ trình giữ chỗ và triển khai Pod.
Lưu ý rằng lần này, bạn vẫn phải đợi 5 phút để node được thêm vào cluster, nhưng bạn có thể tiếp tục sử dụng node hiện tại. Trong khi chờ đợi, một node mới được cung cấp trong background.
Làm thế nào bạn có thể đạt được điều đó?
Overprovisioning có thể được định cấu hình bằng cách sử dụng triển khai chạy một pod sleep mãi mãi.
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'
Bạn nên chú ý thêm đến bộ nhớ và yêu cầu CPU. Scheduler sử dụng các giá trị đó để quyết định nơi triển khai Pod. Trong trường hợp cụ thể này, chúng được sử dụng để dự trữ không gian. Bạn có thể cung cấp một pod lớn có gần như các yêu cầu phù hợp với các tài nguyên node có sẵn.
Hãy đảm bảo rằng bạn tính đến các tài nguyên được sử dụng bởi kubelet, hệ điều hành, kube-proxy, v.v. Nếu tiến trình node của bạn là 2 vCPU và 8GB bộ nhớ và không gian khả dụng cho nhóm là 1.73 vCPU và ~ 5.9 GB bộ nhớ, pod tạm dừng của bạn phải khớp với pod sau.

Để đảm bảo rằng Pod được loại bỏ ngay sau khi một Pod thực được tạo ra, bạn có thể sử dụng Ưu tiên và Dự phòng (Priorities and Preemptions). Mức độ ưu tiên của Pod cho biết tầm quan trọng của Pod đó so với các Pod khác. Khi một Node không thể được lên lịch, scheduler sẽ cố gắng chặn trước (loại bỏ) các Pod có mức ưu tiên thấp hơn để lên lịch cho Pending pod.
Bạn có thể định cấu hình Pod Priorities trong cụm của mình bằng PodPooterClass:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: 'Priority class used by overprovisioning.'
Vì mức độ ưu tiên mặc định cho một Pod là 0 và overprovisioning PriorityClass có giá trị là -1, các Pod đó là nhóm đầu tiên bị loại bỏ khi cluster hết dung lượng.
PriorityClass cũng có hai trường tùy chọn: globalDefault và description.
- Đây description là bản ghi nhớ mà con người có thể đọc được về nội dung của PriorityClass.
- Trường globalDefault chỉ ra rằng giá trị của PriorityClass này sẽ được sử dụng cho Pod không có priorityClassName. Chỉ một PriorityClass với globalDefault được đặt thành true có thể tồn tại trong hệ thống.
Bạn có thể chỉ định mức độ ưu tiên cho sleep Pod của mình bằng:
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: k8s.gcr.io/pause
resources:
requests:
cpu: '1739m'
memory: '5.9G'
Quá trình thiết lập đã hoàn tất!
Khi không có đủ tài nguyên trong cluster, pod tạm dừng sẽ được ưu tiên và các pod mới sẽ thế chỗ. Vì pod tạm dừng không thể lên lịch được, nó buộc Cluster Autoscaler phải thêm nhiều node hơn vào cluster.
Bây giờ bạn đã sẵn sàng để overprovision cluster của mình, bạn nên xem xét việc tối ưu hóa các ứng dụng của mình để mở rộng quy mô.
Chọn đúng bộ nhớ và CPU yêu cầu cho Pod
Cluster autoscaler đưa ra quyết định mở rộng quy mô dựa trên sự hiện diện của các pod đang chờ xử lý. Kubernetes scheduler chỉ định (hoặc không) một Pod cho một Node dựa trên các yêu cầu về bộ nhớ và CPU của nó.
Do đó, điều cần thiết là phải đặt các yêu cầu chính xác trên các workload của bạn, nếu không bạn có thể kích hoạt autoscaler của mình quá muộn (hoặc quá sớm).
Hãy xem một ví dụ.
Bạn quyết định lập hồ sơ ứng dụng và bạn phát hiện ra rằng:
- Dưới mức tải trung bình, ứng dụng tiêu thụ 512MB bộ nhớ và 0,25 vCPU.
- Ở mức cao nhất, ứng dụng sẽ tiêu tốn tới 4GB bộ nhớ và 1 vCPU.

Giới hạn cho container của bạn là 4GB bộ nhớ và 1 vCPU.
Scheduler sử dụng bộ nhớ của Pod và các CPU request để chọn nút tốt nhất trước khi tạo Pod.
Vì vậy, bạn có thể:
- Đặt request thấp hơn mức sử dụng trung bình thực tế.
- Hãy thận trọng và chỉ định các request gần với giới hạn hơn.
- Đặt request để phù hợp với giới hạn thực tế.
Việc xác định các request thấp hơn mức sử dụng thực tế là một vấn đề vì các node của bạn sẽ thường bị bỏ qua.
Ví dụ, bạn có thể gán 256MB bộ nhớ như một yêu cầu bộ nhớ.
Kubernetes scheduler có thể phù hợp với số lượng Pod nhiều gấp đôi cho mỗi node. Tuy nhiên, các Pod sử dụng gấp đôi bộ nhớ trong thực tế và bắt đầu cạnh tranh tài nguyên (CPU) và bị loại bỏ (không đủ bộ nhớ trên Node).

Việc kết hợp quá nhiều node có thể dẫn đến việc loại bỏ quá nhiều, nhiều công việc hơn cho kubelet và phải lên lịch lại nhiều lần.
Điều gì xảy ra nếu bạn đặt request bằng cùng một giá trị của giới hạn?
Bạn có thể đặt request và giới hạn thành các giá trị giống nhau.
Trong Kubernetes, điều này thường được gọi là Guaranteed Quality of Service class và đề cập đến thực tế là không thể tránh khỏi việc pod sẽ bị chấm dứt và loại bỏ. Kubernetes scheduler sẽ dành toàn bộ CPU và bộ nhớ cho Pod trên node được chỉ định.
Các Pod với Guaranteed Quality of Service class được đảm bảo ổn định nhưng cũng không hiệu quả. Nếu ứng dụng của bạn sử dụng trung bình 512MB bộ nhớ, nhưng bạn dành 4GB cho nó, thì bạn có 3.5GB không sử dụng hầu hết thời gian.

Nếu bạn muốn hiệu quả, bạn có thể muốn giảm request và để lại khoảng cách giữa những request đó và giới hạn. Đây thường được gọi là Burstable Quality of Service class và đề cập đến thực tế là mức tiêu thụ cơ bản của Pod đôi khi có thể bùng nổ khi sử dụng nhiều bộ nhớ và CPU hơn. Khi request của bạn phù hợp với mức sử dụng thực tế của ứng dụng, scheduler sẽ đóng gói các pod trong các node một cách hiệu quả.
Đôi khi, ứng dụng có thể yêu cầu thêm bộ nhớ hoặc CPU.
- Nếu có tài nguyên trong Node, ứng dụng sẽ sử dụng chúng trước khi quay trở lại mức tiêu thụ cơ bản.
- Nếu node sắp hết tài nguyên, pod sẽ cạnh tranh tài nguyên (CPU) và kubelet có thể cố gắng loại bỏ Pod (bộ nhớ).
Bạn nên sử dụng Guaranteed hay Burstable quality of Service? Nó phụ thuộc vào bạn.
- Sử dụng Guaranteed Quality of Service (yêu cầu ngang bằng với giới hạn) khi bạn muốn giảm thiểu việc đổi lịch và loại bỏ đối với Pod. Một ví dụ tuyệt vời là Pod cho cơ sở dữ liệu.
- Sử dụng Burstable Quality of Service (yêu cầu phù hợp với mức sử dụng trung bình thực tế) khi bạn muốn tối ưu hóa cluster của mình và sử dụng tài nguyên một cách khôn ngoan. Nếu bạn có ứng dụng web hoặc API REST, bạn có thể muốn sử dụng Burstable Quality of Service.
Làm cách nào để bạn chọn đúng các yêu cầu và giá trị giới hạn?
Bạn nên lập hồ sơ ứng dụng và đo mức tiêu thụ bộ nhớ và CPU khi không hoạt động, dưới tải và lúc cao điểm. Một chiến lược đơn giản hơn bao gồm việc triển khai Vertical Pod Autoscaler và đợi nó đề xuất các giá trị chính xác. Vertical Pod Autoscaler thu thập dữ liệu từ Pod và áp dụng mô hình hồi quy để ngoại suy các yêu cầu và giới hạn.
Việc giảm tỷ lệ một cluster
Cứ sau 10 giây, Cluster Autoscaler quyết định loại bỏ một node chỉ khi mức sử dụng yêu cầu giảm xuống dưới 50%. Nói cách khác, đối với tất cả các pod trên cùng một node, nó tính tổng các yêu cầu CPU và bộ nhớ.
Nếu chúng thấp hơn một nửa dung lượng của node, Cluster Autoscaler sẽ xem xét node hiện tại để giảm tỷ lệ. Cần lưu ý rằng Cluster Autoscaler không xem xét việc sử dụng hoặc giới hạn CPU và bộ nhớ thực tế và thay vào đó chỉ xem xét các yêu cầu tài nguyên. Trước khi node bị xóa, Cluster Autoscaler thực thi:
- Các Pod sẽ kiểm tra để đảm bảo rằng các Pod có thể được di chuyển đến các node khác.
- Kiểm tra các node để ngăn các node bị phá hủy sớm.
Nếu các lần kiểm tra thông qua, Cluster Autoscaler sẽ xóa node khỏi cluster.
Tại sao autoscaling không dựa trên bộ nhớ hoặc CPU?
Autoscaler dựa trên CPU hoặc bộ nhớ không quan tâm đến các pod khi tăng và giảm tỷ lệ. Hãy tưởng tượng bạn có một cluster với một node duy nhất và thiết lập autoscaler để thêm một node mới với CPU đạt 80% tổng dung lượng. Bạn quyết định tạo một Deployment với 3 replica. Việc sử dụng tài nguyên kết hợp cho ba pod đạt 85% CPU. Một node mới được cấp phép.
Điều gì sẽ xảy ra nếu bạn không cần thêm bất kỳ pod nào nữa?
Bạn có một node đầy đủ đang chạy không tải. Không khuyến khích sử dụng các loại autoscaler này với Kubernetes.
Tóm tắt
Việc xác định và thực hiện chiến lược mở rộng quy mô thành công trong Kubernetes yêu cầu bạn phải thành thạo một số chủ đề:
- Phân bổ tài nguyên trong các Kubernetes node.
- Tinh chỉnh khoảng thời gian làm mới cho Metrics Server, Horizontal Pod Autoscaler and Cluster Autoscalers.
- Kiến trúc kích thước tiến trình node và cluster.
- Bộ nhớ đệm container image.
- Điểm chuẩn ứng dụng và lập hồ sơ.
Nhưng với công cụ giám sát thích hợp, bạn có thể kiểm tra lặp đi lặp lại chiến lược mở rộng quy mô của mình và điều chỉnh tốc độ cũng như chi phí của cluster. Hãy theo dõi những bài viết tiếp theo của Bizfly Cloud để cập nhật những thủ thuật công nghệ mới hữu ích mỗi ngày.
Bizfly Kubernetes Engine với những tính năng ưu việt và vượt trội sẽ mang lại những tác động tích cực đến các Dev team/DevOps cũng như toàn bộ doanh nghiệp. Nếu bạn đang muốn bắt đầu với Kubernetes, truy cập: https://bizflycloud.vn/kubernetes-engine để trải nghiệm miễn phí ngay hôm nay.