Triển khai graceful shutdown và zero-downtime trong Kubernetes
Trong bài viết này, Bizfly Cloud sẽ chia sẻ cách ngăn kết nối bị hỏng khi một Pod khởi động hoặc tắt. Bạn cũng sẽ học cách tắt các tác vụ chạy lâu dài một cách dễ dàng. Hãy cùng tìm hiểu nhé!
Trong Kubernetes, tạo và xóa Pod là một trong những tác vụ phổ biến nhất. Các nhóm được tạo ra khi bạn thực hiện cập nhật liên tục, triển khai scale cho mọi bản phát hành mới, cho mọi công việc v.v. Nhưng các Nod cũng bị xóa và được tạo lại sau khi bị loại bỏ - ví dụ như khi bạn đánh dấu một node là không thể lên lịch.
Nếu bản chất của các Pod đó là không bền vững, điều gì sẽ xảy ra khi một Pod đang trong quá trình phản hồi một yêu cầu nhưng nó được ra lệnh tắt? Yêu cầu có được hoàn thành trước khi tắt máy không? Còn những yêu cầu tiếp theo thì sao, những yêu cầu đó có được chuyển hướng đến một nơi khác không?
Trước khi thảo luận về điều gì sẽ xảy ra khi một Pod bị xóa, cần phải bàn về những gì sẽ xảy ra khi một Pod được tạo.
Giả sử bạn muốn tạo Pod sau trong cụm của mình:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
Bạn có thể gửi định nghĩa YAML cho cụm với:
kubectl apply -f pod.yaml
Ngay sau khi bạn nhập lệnh, kubectl sẽ gửi định nghĩa Pod tới Kubernetes API.
Đây là nơi cuộc hành trình bắt đầu.
Lưu trạng thái của cụm trong cơ sở dữ liệu
Định nghĩa Pod được API tiếp nhận và kiểm tra, sau đó được lưu trữ trong cơ sở dữ liệu - etcd.
Pod cũng được thêm vào hàng đợi của Scheduler.
Scheduler:
1. Kiểm tra định nghĩa
2. Thu thập thông tin chi tiết về khối lượng công việc như yêu cầu CPU và bộ nhớ
3. Quyết định Node nào phù hợp nhất để chạy nó (thông qua một quá trình được gọi là Filters và Predicates).
Vào cuối quá trình:
- Pod được đánh dấu là Đã lên lịch trong etcd.
- Pod có một Node được gán cho nó.
- Trạng thái của Pod được lưu trữ trong etcd.
Nhưng Pod vẫn không tồn tại.

Các tác vụ trước đó đã xảy ra trong control plane và trạng thái được lưu trữ trong cơ sở dữ liệu.
Vậy ai là người tạo Pod trong các Node của bạn?
Kubelet - Kubernetes agent
Nhiệm vụ của kubelet là thăm dò control plane để cập nhật.
Bạn có thể tưởng tượng kubelet không ngừng hỏi master node: "Tôi trông coi Worker Node 1, có Pod nào mới cho tôi không?".
Khi có một Pod, kubelet sẽ tạo ra nó.
Kubelet không tự tạo Pod. Thay vào đó, nó ủy quyền công việc cho ba thành phần khác:
- Container Runtime Interface (CRI) - thành phần tạo ra các container cho Pod.
- Container Network Interface (CNI) - thành phần kết nối các container với mạng lưới cluster và chỉ định địa chỉ IP.
- Container Storage Interface (CSI) - thành phần gắn kết khối lượng trong container của bạn.
Trong hầu hết các trường hợp, Container Runtime Interface (CRI) đang thực hiện công việc tương tự như:
docker run -d <my-container-image>
Container Network Interface (CNI) thú vị hơn một chút vì nó phụ trách:
1. Tạo địa chỉ IP hợp lệ cho Pod.
2. Kết nối container với phần còn lại của mạng.
Như bạn có thể tưởng tượng, có một số cách để kết nối container với mạng và chỉ định địa chỉ IP hợp lệ (bạn có thể chọn giữa IPv4 hoặc IPv6 hoặc có thể chỉ định nhiều địa chỉ IP).
Ví dụ: Docker tạo các cặp ethernet ảo và gắn nó vào một cầu nối, trong khi AWS-CNI kết nối các Pod trực tiếp với phần còn lại của Đám mây riêng ảo (VPC).
Khi Container Network Interface (CNI) hoàn thành công việc của nó, Pod được kết nối với phần còn lại của mạng và được gán địa chỉ IP hợp lệ.
Chỉ có một vấn đề.
Kubelet biết về địa chỉ IP (vì nó đã liên hệ CNI), nhưng control plane thì không.
Không ai nói với Master Node rằng Pod đã được gán địa chỉ IP và nó đã sẵn sàng để nhận lưu lượng truy cập.
Nhiệm vụ của kubelet là thu thập tất cả các chi tiết của Pod như địa chỉ IP và báo cáo lại control plane.
Bạn có thể tưởng tượng rằng việc kiểm tra etcd sẽ không chỉ tiết lộ vị trí Pod đang chạy mà còn cả địa chỉ IP của nó.
Nếu Pod không phải là một phần của bất kỳ Service nào, thì đây là phần cuối của cuộc hành trình.
Pod đã được tạo và sẵn sàng sử dụng.
Khi Pod là một phần của Service, cần thực hiện thêm một số bước.
Các Pod và Service
Khi bạn tạo một Service, thường có hai phần thông tin mà bạn nên chú ý:
1. Selector được sử dụng để chỉ định các Pod sẽ nhận lưu lượng truy cập.
2. Các targetPort- cổng được sử dụng bởi các Pod nhận lưu lượng truy cập.
Định nghĩa YAML điển hình cho Service sẽ như sau:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- port: 80
targetPort: 3000
selector:
name: app
Khi bạn gửi Service đến cluster với kubectl apply, Kubernetes tìm tất cả các Pod có cùng nhãn với selector (name: app) và thu thập địa chỉ IP của chúng - nhưng chỉ khi chúng vượt qua thăm dò Mức độ sẵn sàng .
Sau đó, đối với mỗi địa chỉ IP, nó sẽ nối địa chỉ IP và cổng (port).
Nếu địa chỉ IP là 10.0.0.3 và targetPort là 3000, Kubernetes sẽ nối hai giá trị và gọi chúng là một điểm cuối.
IP address + port = endpoint
---------------------------------
10.0.0.3 + 3000 = 10.0.0.3:3000
Các điểm cuối được lưu trữ trong etcd trong một đối tượng khác được gọi là Endpoint.
Đối tượng Endpoint là một đối tượng thực trong Kubernetes và đối với mọi Service Kubernetes sẽ tự động tạo một đối tượng Endpoint.
Bạn có thể xác minh điều đó bằng:

Endpoint thu thập tất cả các địa chỉ IP và cổng từ các Pod.
Nhưng không chỉ một lần.
Đối tượng Endpoint được làm mới với danh sách điểm cuối mới khi:
1. Một Pod được tạo.
2. Một Pod đã bị xóa.
3. Một nhãn được sửa đổi trên Pod.
Vì vậy, bạn có thể tưởng tượng rằng mỗi khi bạn tạo Pod và sau khi kubelet đăng địa chỉ IP của nó lên Master Node, Kubernetes sẽ cập nhật tất cả các điểm cuối để phản ánh sự thay đổi:

Điểm cuối được lưu trữ trong control plane và đối tượng Endpoint đã được cập nhật.

Kubernetes react với mọi thay đổi nhỏ trong cụm của bạn.
Sử dụng Endpoint trong Kubernetes
Các điểm cuối được sử dụng bởi một số thành phần trong Kubernetes.
Kube-proxy sử dụng các điểm cuối để thiết lập các quy tắc iptables trên các Node.
Vì vậy, mỗi khi có thay đổi đối với Endpoint (đối tượng), kube-proxy sẽ truy xuất danh sách địa chỉ IP và cổng mới và viết các quy tắc iptables mới.

Kube-proxy sử dụng các điểm cuối để tạo các quy tắc iptables trên mỗi Node trong cụm của bạn
Bộ điều khiển Ingress sử dụng cùng một danh sách các điểm cuối. Bộ điều khiển Ingress là thành phần trong cụm định tuyến lưu lượng truy cập bên ngoài vào cụm. Khi bạn thiết lập tệp kê khai Ingress, bạn thường chỉ định Service làm đích:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- http:
paths:
- backend:
service:
name: my-service
port:
number: 80
path: /
pathType: Prefix
Trên thực tế, lưu lượng truy cập không được chuyển đến Service.
Thay vào đó, bộ điều khiển Ingress thiết lập một đăng ký để được thông báo mỗi khi các điểm cuối cho Service đó thay đổi.
Ingress định tuyến lưu lượng truy cập trực tiếp đến các Pod bỏ qua Service.
Như bạn có thể tưởng tượng, mỗi khi có thay đổi đối với Endpoint (đối tượng), Ingress sẽ truy xuất danh sách địa chỉ IP và cổng mới và định cấu hình lại bộ điều khiển để bao gồm các Pod mới.
Lần này bạn đã hoàn thành!
Tóm tắt nhanh về những gì sẽ xảy ra khi bạn tạo Pod:
1. Pod được lưu trữ trong etcd.
2. Scheduler chỉ định một Node. Nó ghi node trong etcd.
3. Kubelet được thông báo về một Pod mới và được lên lịch.
4. Kubelet ủy nhiệm việc tạo container cho Container Runtime Interface (CRI).
5. Kubelet ủy quyền gắn container vào Container Network Interface (CNI).
6. Kubelet ủy quyền việc gắn khối lượng trong container vào Container Storage Interface (CSI).
7. Container Network Interface chỉ định địa chỉ IP.
8. Kubelet báo cáo địa chỉ IP cho control plane.
9. Địa chỉ IP được lưu trữ trong etcd.
Và nếu Pod của bạn thuộc về một Service:
1. Kubelet chờ một Readiness probe thành công.
2. Tất cả các Endpoint (đối tượng) có liên quan đều được thông báo về sự thay đổi.
3. Endpoint thêm một điểm cuối mới (địa chỉ IP + cặp port) vào danh sách của chúng.
4. Kube-proxy được thông báo về sự thay đổi Endpoint. Kube-proxy cập nhật các quy tắc iptables trên mọi node.
5. Bộ điều khiển Ingress được thông báo về sự thay đổi Endpoint. Bộ điều khiển định tuyến lưu lượng đến các địa chỉ IP mới.
6. CoreDNS được thông báo về sự thay đổi Endpoint. Nếu Service thuộc loại Headless, DNS entry sẽ được cập nhật.
7. Nhà cung cấp đám mây được thông báo về sự thay đổi Endpoint. Nếu Service là của type: LoadBalancer, điểm cuối mới được định cấu hình như một phần của nhóm cân bằng tải.
8. Bất kỳ lưới dịch vụ nào được cài đặt trong cụm đều được thông báo về sự thay đổi Endpoint.
9. Bất kỳ nhà điều hành nào khác đã đăng ký thay đổi Endpoint cũng sẽ được thông báo.
Pod đang chạy. Đã đến lúc thảo luận điều gì sẽ xảy ra khi bạn xóa nó.
Xóa một Pod
Khi Pod bị xóa, bạn phải làm theo các bước tương tự nhưng ngược lại.
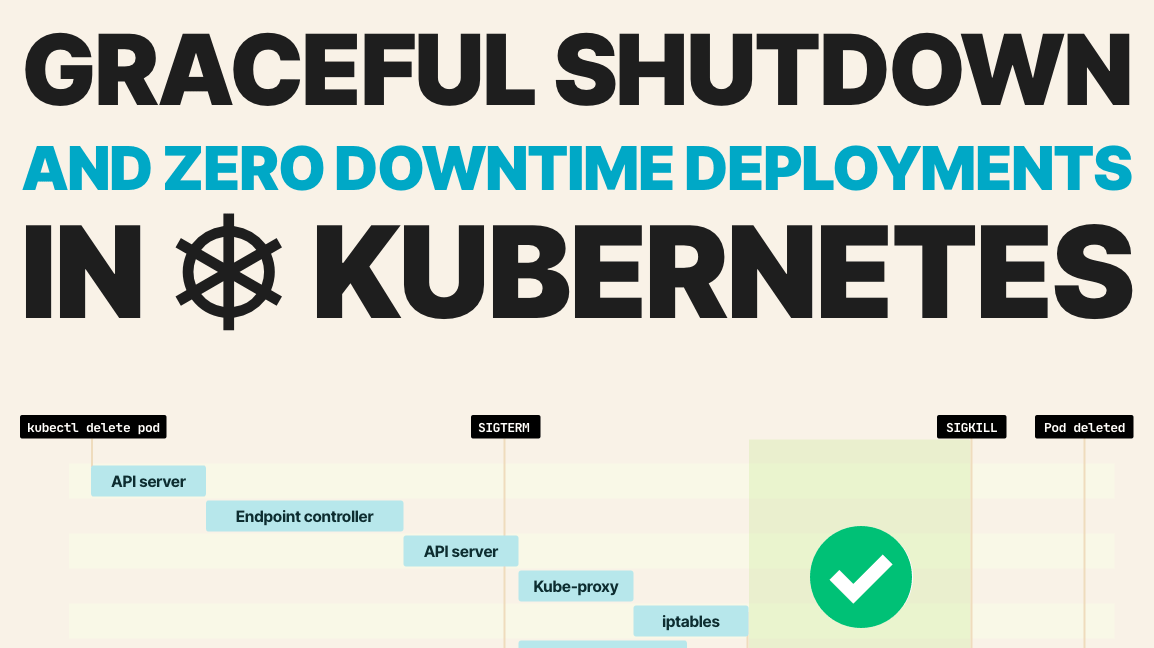
Đầu tiên, điểm cuối nên được xóa khỏi Endpoint (đối tượng). Lần này, Readiness probe bị bỏ qua và điểm cuối bị xóa ngay lập tức khỏi control plane. Khi đến lượt, nó kích hoạt tất cả các event tới kube-proxy, Ingress controller, DNS, service mesh, v.v.
Các thành phần đó sẽ cập nhật trạng thái bên trong của chúng và ngừng định tuyến lưu lượng truy cập đến địa chỉ IP. Vì các thành phần có thể bận làm việc khác, nên không có gì đảm bảo sẽ mất bao lâu để xóa địa chỉ IP khỏi trạng thái bên trong của chúng. Đối với một số người, nó có thể mất ít hơn một giây; đối với những người khác, nó có thể mất nhiều hơn. Đồng thời, trạng thái của Pod trong etcd được thay đổi thành Terminating.
Kubelet được thông báo về sự thay đổi và ủy quyền:
1. Ngắt kết nối bất kỳ khối lượng nào từ vùng chứa với CSI.
2. Tách vùng chứa khỏi mạng và giải phóng địa chỉ IP cho CNI.
3. Phá hủy vùng chứa đối với CRI.
Nói cách khác, Kubernetes thực hiện chính xác các bước tương tự để tạo Pod nhưng ngược lại. Khi bạn kết thúc một Pod, việc loại bỏ điểm cuối và tín hiệu đến kubelet được phát ra cùng một lúc. Khi bạn tạo Pod lần đầu tiên, Kubernetes đợi kubelet báo cáo địa chỉ IP và sau đó bắt đầu truyền điểm cuối. Tuy nhiên, khi bạn xóa một Pod, các event bắt đầu song song.
Graceful shutdown
Khi một Pod bị kết thúc trước khi điểm cuối bị xóa khỏi kube-proxy hoặc bộ điều khiển Ingress, bạn có thể gặp phải downtime. Kubernetes vẫn đang định tuyến lưu lượng truy cập đến địa chỉ IP, nhưng Pod không còn ở đó nữa. Bộ điều khiển Ingress, kube-proxy, CoreDNS, v.v. không có đủ thời gian để xóa địa chỉ IP khỏi trạng thái nội bộ của chúng.
Tốt nhất, Kubernetes nên đợi tất cả các thành phần trong cụm có danh sách cập nhật các điểm cuối trước khi Pod bị xóa. Nhưng Kubernetes không hoạt động như vậy.
Kubernetes cung cấp các nguyên bản mạnh mẽ để phân phối các điểm cuối (tức là đối tượng Endpoint và các phần trừu tượng nâng cao hơn như Endpoint Slices). Tuy nhiên, Kubernetes không xác minh rằng các thành phần đăng ký thay đổi điểm cuối được cập nhật với trạng thái của cụm.
Khi Pod sắp bị xóa, nó nhận được tín hiệu SIGTERM.
Ứng dụng của bạn có thể nắm bắt tín hiệu đó và bắt đầu tắt. Vì không có khả năng điểm cuối bị xóa ngay lập tức khỏi tất cả các thành phần trong Kubernetes, bạn có thể:
1. Chờ một chút nữa trước khi thoát.
2. Vẫn xử lý lưu lượng đến, bất chấp SIGTERM.
3. Cuối cùng, đóng các kết nối tồn tại lâu dài hiện có (có thể là kết nối cơ sở dữ liệu hoặc WebSockets).
4. Đóng quá trình.
Theo mặc định, Kubernetes sẽ gửi tín hiệu SIGTERM và đợi 30 giây trước khi buộc thực hiện quá trình. Vì vậy, bạn có thể sử dụng 15 giây đầu tiên để tiếp tục hoạt động như không có gì xảy ra.
Hy vọng rằng khoảng thời gian này sẽ đủ để truyền việc loại bỏ điểm cuối tới kube-proxy, bộ điều khiển Ingress, CoreDNS, v.v. Và kết quả là lưu lượng truy cập ngày càng ít hơn sẽ đến Pod của bạn cho đến khi nó dừng lại.
Sau 15 giây, có thể an toàn để đóng kết nối của bạn với cơ sở dữ liệu (hoặc bất kỳ kết nối liên tục nào) và chấm dứt quá trình. Nếu bạn nghĩ rằng bạn cần thêm thời gian, bạn có thể dừng quá trình ở 20 hoặc 25 giây.
Tuy nhiên, bạn nên nhớ rằng Kubernetes sẽ buộc thực hiện quá trình này sau 30 giây (trừ khi bạn thay đổi định nghĩa terminationGracePeriodSeconds trong Pod của mình).
Nếu bạn không thể đổi mã để chờ lâu hơn thì sao?
Bạn có thể gọi một tập lệnh để đợi một khoảng thời gian cố định và sau đó để ứng dụng thoát. Trước khi SIGTERM được gọi, Kubernetes hiển thị preStop hook trong Pod. Bạn có thể đặt preStop hook để đợi trong 15 giây.
Hãy xem một ví dụ:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
lifecycle:
preStop:
exec:
command: ["sleep", "15"]
Thời gian gia hạn và cập nhật liên tục
Tính năng Graceful shutdown áp dụng cho các Pod bị xóa.
Nhưng điều gì sẽ xảy ra nếu bạn không xóa các Pod?
Ngay cả khi bạn không làm vậy, Kubernetes luôn xóa Pod. Đặc biệt, Kubernetes tạo và xóa Pod mỗi khi bạn triển khai phiên bản ứng dụng mới hơn của mình. Khi bạn thay đổi image trong Deployment của mình, Kubernetes sẽ dần dần thực hiện thay đổi.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
replicas: 3
selector:
matchLabels:
name: app
template:
metadata:
labels:
name: app
spec:
containers:
- name: app
# image: nginx:1.18 OLD
image: nginx:1.19
ports:
- containerPort: 3000
Nếu bạn có ba replica và ngay sau khi bạn gửi tài nguyên YAML Kubernetes mới:
- Tạo một Pod với container image mới.
- Hủy một Pod hiện có.
- Chờ Pod sẵn sàng.
Và nó lặp lại các bước ở trên cho đến khi tất cả các Pod được chuyển sang phiên bản mới hơn.
Kubernetes chỉ lặp lại mỗi chu kỳ sau khi Pod mới sẵn sàng nhận lưu lượng truy cập (nói cách khác, nó vượt qua kiểm tra Readiness).
Kubernetes có đợi Pod bị xóa trước khi chuyển sang Pod tiếp theo không? Câu trả lời là Không.
Nếu bạn có 10 Pod và Pod mất 2 giây để sẵn sàng và 20 Pod để tắt thì điều này sẽ xảy ra:
1. Pod đầu tiên được tạo và Pod trước đó sẽ bị kết thúc.
2. Pod mới mất 2 giây để sẵn sàng sau đó Kubernetes tạo một Pod mới.
3. Trong thời gian chờ đợi, Pod được kết thúc sẽ kết thúc trong 20 giây
Sau 20 giây, tất cả các Pod mới tồn tại (10 Pod, Ready sau 2 giây) và tất cả 10 các Pods trước đó bị kết thúc (Terminated Pod đầu tiên sẽ kết thúc). Tổng cộng, bạn có gấp đôi số lượng Pod trong một khoảng thời gian ngắn (10 Running và 10 Terminating).

Thời gian gia hạn càng dài so với Readiness probe, bạn sẽ càng có nhiều Pod Running (và Terminating) cùng một lúc.
Chấm dứt các tác vụ kéo dài
Nếu bạn đang chuyển mã một video lớn, có cách nào để trì hoãn việc dừng Pod không?
Hãy tưởng tượng bạn có một Deployment với 3 replica. Mỗi bản sao được gán một video để chuyển mã và nhiệm vụ có thể mất vài giờ để hoàn thành. Khi bạn kích hoạt cập nhật liên tục, Pod có 30 giây để hoàn thành nhiệm vụ trước khi bị loại bỏ.
Làm thế nào bạn có thể tránh trì hoãn việc tắt Pod?
Bạn có thể tăng terminationGracePeriodSeconds vài giờ.
Tuy nhiên, điểm cuối của Pod không thể truy cập được vào thời điểm đó.
Nếu bạn để lộ các chỉ số để theo dõi Pod của mình, thiết bị đo của bạn sẽ không thể tiếp cận Pod của bạn.
Các công cụ như Prometheus dựa vào Endpoint để loại bỏ các Pod trong cụm của bạn.
Tuy nhiên, ngay sau khi bạn xóa Pod, việc xóa điểm cuối sẽ được lan truyền trong cụm - ngay cả với Prometheus!
Thay vì tăng thời gian gia hạn, bạn nên cân nhắc tạo một Deployment mới cho mỗi bản phát hành mới.
Khi bạn tạo một Deployment hoàn toàn mới, Deployment hiện tại sẽ không bị ảnh hưởng. Các công việc kéo dài có thể tiếp tục xử lý video như bình thường. Sau khi hoàn tất, bạn có thể xóa chúng theo cách thủ công. Nếu bạn muốn xóa chúng tự động, bạn có thể muốn thiết lập một bộ đo tự động có thể mở rộng quy mô triển khai của bạn thành 0 bản sao khi chúng hết nhiệm vụ.
Ví dụ như WebSockets. Nếu bạn đang phát trực tuyến các bản cập nhật theo thời gian thực cho người dùng của mình, bạn có thể không muốn chấm dứt WebSockets mỗi khi có bản phát hành. Nếu bạn thường xuyên phát hành trong ngày, điều đó có thể khiến nguồn cấp dữ liệu theo thời gian thực bị gián đoạn.
Tạo một Deployment mới cho mọi bản phát hành là một lựa chọn ít rõ ràng hơn nhưng tốt hơn.
Người dùng hiện tại có thể tiếp tục phát trực tuyến các bản cập nhật trong khi Deployment gần đây nhất phục vụ người dùng mới. Khi người dùng ngắt kết nối khỏi Pod cũ, bạn có thể giảm dần các replica và gỡ bỏ các Deployment trước đây.
Tóm tắt
Bạn nên chú ý đến việc các Pod sẽ bị xóa khỏi cụm của bạn vì địa chỉ IP của chúng có thể vẫn được sử dụng để định tuyến lưu lượng truy cập. Thay vì tắt Pods ngay lập tức, bạn nên cân nhắc chờ đợi lâu hơn một chút trong ứng dụng của mình hoặc thiết lập preStop hook. Chỉ nên xóa Pod sau khi tất cả các điểm cuối trong cụm được truyền và xóa khỏi kube-proxy, bộ điều khiển Ingress, CoreDNS, v.v.
Nếu Pod của bạn chạy các tác vụ lâu dài như chuyển mã video hoặc cung cấp các bản cập nhật theo thời gian thực với WebSockets, bạn nên cân nhắc sử dụng rainbow deployment. Trong rainbow deployment, bạn tạo một Deployment mới cho mọi bản phát hành và xóa bản trước đó khi kết nối (hoặc các tác vụ) cạn kiệt.
Bạn có thể xóa thủ công các deployment cũ hơn ngay sau khi tác vụ chạy dài hoàn thành. Hoặc bạn có thể tự động mở rộng quy mô triển khai của mình thành 0 bản sao để tự động hóa quy trình.
Bizfly Kubernetes Engine với những tính năng ưu việt và vượt trội sẽ mang lại những tác động tích cực đến các Dev team/DevOps cũng như toàn bộ doanh nghiệp. Nếu bạn đang muốn bắt đầu với Kubernetes, truy cập: https://bizflycloud.vn/kubernetes-engine để trải nghiệm miễn phí ngay hôm nay.
>> Có thể bạn quan tâm: Cách triển khai Nginx Ingress với Cert-Manager trên Bizfly Kubernetes Engine