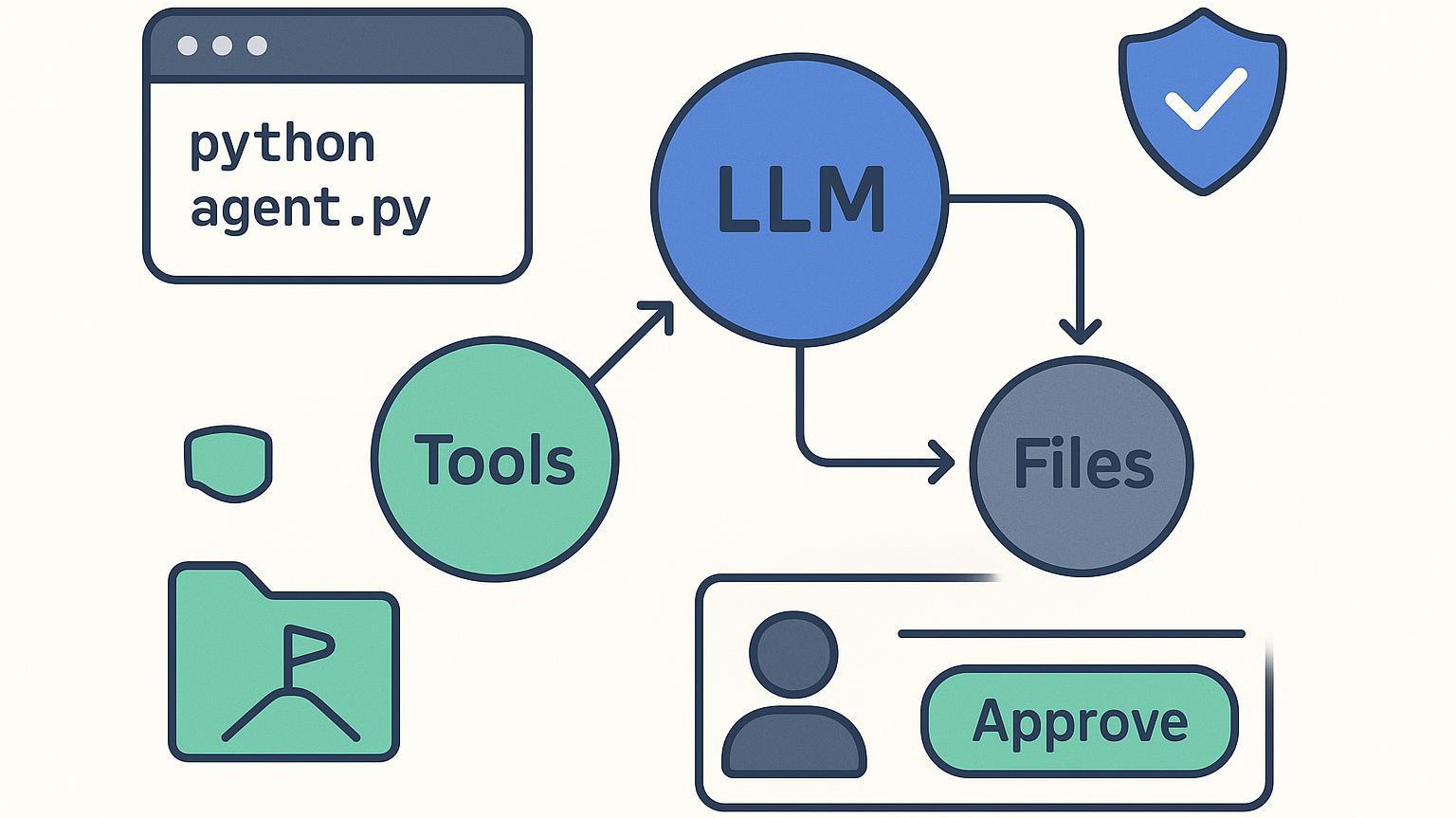
Từ lý thuyết đến triển khai: Build một AI agent mạnh mẽ, tự điều chỉnh từ đầu thuần Python
Trong hướng dẫn này, chúng ta sẽ xây dựng một Agent Lập kế hoạch và Thực thi có cấu trúc. Mặc dù thường được xếp vào nhóm “ReAct”, kiến trúc này mạnh mẽ hơn đối với các workflow làm việc phức tạp thông qua việc chia nhỏ query thành một danh sách tác vụ JSON-based trước khi thực thi.
Những gì chúng ta đang xây dựng:
Phần thao tác: Xác định các hàm Python và lược đồ JSON của các hàm này để tương thích với LLM.
Phần lập kế hoạch: Sử dụng một lệnh gọi LLM thiên về suy luận để phân tách các query phức tạp thành một task list.
Phần thực thi: Lặp lại các từng tác vụ và ánh xạ chúng tới các công cụ cụ thể để thực hiện.
Cơ chế an toàn: Triển khai vòng lặp thử lại 3 giai đoạn để xử lý "sự hỗn loạn" của JSON không xác định (non-deterministic).
Kiến trúc: Lập kế hoạch rồi thực thi
Không giống như mô hình ReAct cổ điển (suy nghĩ và hành động từng bước một), agent chúng ta đang triển khai tuân theo một quy trình ba giai đoạn được tổ chức bài bản hơn:

Phần lập kế hoạch: LLM nhận câu hỏi của người dùng và trả về một danh sách các tác vụ dưới dạng JSON.
Phần thực thi: Đối với mỗi tác vụ, LLM chọn công cụ phù hợp, chạy hàm Python và thêm kết quả.
Phần tổng hợp: Cuối cùng, LLM sử dụng toàn bộ lịch sử thực thi để đưa ra câu trả lời cuối cùng.
Hiểu được pipeline là chúng ta sẽ có 1 map/ bản đồ thực hiện, nhưng map sẽ không thể sử dụng được nếu không có thiết bị phù hợp. Để biến bản thiết kế này thành một cỗ máy hoạt động, trước tiên chúng ta phải xây dựng giao diện cho phép AI tương tác với thế giới thực. Trong thế giới tác nhân, chúng ta gọi những thứ này là "Bàn tay".
Bước 1: Triển khai “Các công cụ” (API Contracts)
Trước khi agent có thể thực thi một kế hoạch, nó cần biết khả năng thực sự của mình. Bước đầu tiên là cần tập trung vào việc xác định “Các công cụ”.
Hãy xem bước này giống như việc tạo một API Contract giữa môi trường Python của bạn và LLM. LLM không thể nhìn thấy trực tiếp code Python của bạn; nó chỉ có thể thấy JSON Schema mà bạn cung cấp. Do đó, mỗi công cụ bao gồm hai phần:
Logic: Hàm Python thực tế thực hiện công việc.
Schema: Mô tả cho LLM biết khi nào và làm thế nào để gọi hàm đó.
Hãy bắt đầu bằng việc xây dựng công cụ cho Agent: Trước tiên, chúng ta cần xác định các hàm Python và JSON schema của chúng.

Kết nối LLM và các công cụ
Trước khi xem xét raw Python, chúng ta cần giải quyết vấn đề kỹ thuật lớn nhất trong AI: Ngôn ngữ: Môi trường Python của bạn nói "Code" (các hàm và biến), nhưng LLM của bạn lại nói "Text". Để thu hẹp khoảng cách này, chúng ta sử dụng JSON schema. Hãy coi đây như "Sổ tay Dịch thuật" cho phép não bộ (LLM) hiểu cách di chuyển của Đôi tay (công cụ).
Trong kiến trúc của chúng ta, Bước 1 là tạo ra sổ tay này. Chúng ta không chỉ viết một hàm; chúng ta viết một Khai báo Hàm cho LLM biết:
Công cụ làm gì (Mô tả).
Dữ liệu cụ thể nào nó cần (Tham số).
Đây là "API Contract" đảm bảo khi phần lập kế hoạch đưa lệnh "Lấy khối lượng của Mars", phần thực thi sẽ biết chính xác hàm nào cần kích hoạt. Đây là một ví dụ về Khai báo Hàm:
# 1. The Schema (What the LLM sees)
tools_schema = [
{
"type": "function",
"name": "get_planet_mass",
"description": "Get the mass of a given planet.",
"parameters": {
"type": "object",
"properties": {
"planet": {"type": "string", "description": "Planet name (e.g., Earth)"},
},
"required": ["planet"],
},
},
# ... additional tools like 'calculate'
]
# 2. The Logic (What Python executes)
defget_planet_mass(planet_dict):
planet = planet_dict["planet"].lower().strip()
masses = {"earth": "5.972e24 kg", "mars": "6.39e23 kg", "jupiter": "1.898e27 kg"}
return masses.get(planet, "Unknown planet.")
Sau khi API Contract được thiết lập và các công cụ agent đã sẵn sàng, chúng ta cần triển khai công cụ suy luận để quyết định chính xác khi nào và bằng cách nào sử dụng các công cụ đó: chính là Phần lập kế hoạch.
Bước 2: Lập Kế Hoạch/ Planner
Bây giờ, khi chúng ta đã có trong tay agent, chúng ta cần triển khai phần Kế Hoạch.
Nhiệm vụ của Planner không phải là trực tiếp thực hiện công việc, mà là phân tách một query có thể là rối loạn từ con người thành một danh sách JSON có cấu trúc và có thể thực thi được. Chúng ta cung cấp cho LLM một System Prompt đóng vai trò như bộ quy tắc, buộc nó phải xuất ra JSON hợp lệ thay vì một đoạn văn hội thoại dài dòng.
Lý do chúng ta sử dụng JSON ở đây: Bằng cách buộc Planner xuất ra một structured list of tasks/ danh sách các nhiệm vụ có cấu trúc, chúng ta tạo ra một sự chuyển giao rõ ràng. Phần Thực Thi không cần phải "đoán" xem bước tiếp theo là gì; mà chỉ đơn giản là lặp qua danh sách các nhiệm vụ và thực thi lần lượt.
def __plan_tasks(self, user_prompt: str)-> json:
'''This plans the task the LLM will do'''
planner_system_prompt = (
"You are a sophisticated planner Agent. "
"Your job is to break down complex user questions into sequential, simple tasks. "
"Return a JSON object with a single key "
" - 'tasks': list[string] #which contains a list of strings."
)
action_plan = self.call_llm(planner_system_prompt, user_prompt)
return json.loads(action_plan.output_text
Tuy nhiên, phần kế hoạch chỉ là một danh sách các ý định. Để biến những ý định đó thành hiện thực, chúng ta cần một cơ chế để liên kết từng nhiệm vụ với các công cụ cụ thể mà chúng ta đã xác định ở Bước 1: Điều này được thực hiện trong Phần thực thi/Executor.
Bước 3: Phần thực thi (Mapping & Doing)
Phần thực thi là “cỗ máy làm việc chính” của agent. Nó sẽ lặp qua danh sách các nhiệm vụ do Planner tạo ra, xác định công cụ nào phù hợp cho từng công việc, và thực hiện việc chạy code Python thực tế. Đây cũng là nơi chúng ta triển khai Retry nhằm đảm bảo rằng nếu LLM mắc lỗi định dạng, agent sẽ tự sửa lỗi chứ không bị crash.
Nói một cách đơn giản: Với mỗi tác vụ trong kế hoạch, chúng ta hỏi LLM: “Công cụ nào phù hợp với tác vụ cụ thể này?” Sau đó, chúng ta thực thi công cụ đó và lưu kết quả vào một execution_plan.
Hãy lưu ý rằng chúng ta không chỉ chạy công cụ; chúng ta còn lưu kết quả trở lại vào một execution_plan. Điều này cho phép agent “ghi nhớ” những gì nó vừa làm, cho phép các tác vụ sau sử dụng hoàn toàn các kết quả trước đó.
def __plan_tools(self, action_plan, tools):
execution_plan = []
for task in action_plan["tasks"]:
# 1. Ask the Brain: "Which tool fits this task?"
response = self.call_llm(execution_system_prompt, user_prompt)
# 2. Map the LLM's string choice to our actual Python function
function_to_call = self.available_tools_dict[response["function"]]
response["result"] = function_to_call(*kwargs)
return execution_plan.append(response)
Để máy móc có thể giao tiếp với nhau, chúng ta cần có prompt rất cụ thể. Chúng ta buộc LLM phải trả về một JSON object với các keys xác định. Cấu trúc này cho phép Python loop chạy mà không cần sự can thiệp của con người.
Mẹo: Hãy chú ý đến execution_system_prompt bên dưới. Chúng ta cần nói rõ với LLM: "Nếu không có công cụ nào phù hợp, hãy ghi None." Điều này giúp ngăn agent “tự bịa ra” một hành động khi nó không có công cụ phù hợp để thực hiện.
execution_system_prompt = (
"You are a sophisticated planner Agent. "
"Your job is to find the correct given tools to the system to solve the given tasks."
"The available tools and the task you will get from the user"
"If no tools fit to Task write None"
"Return a JSON object with a single key "
" - 'id: int #unique id to identify the task "
" - 'task': {task}"
" - 'function': string # name of the tool"
" - 'properties: list # properties to execute the function"
" - 'dependencies': list # id's if the needed results of other tasks"
)
user_prompt = (f"I have the following task to do: {task}"
f"I can use the following tools: {tools} to solve the taks "
"Tell me the correct tool to use for a given task"
f"Here is the full list of tasks {action_plan}"
F"Here are the executions that are already done {execution_plan} take the results of tasks have dependencies."
)
Hiện tại chúng ta đã có Công cụ (Hands), Kế hoạch (Plan) và Dữ liệu thực thi (Execution Trace). Nhưng một agent chỉ chạy code và kết thúc thì đó chỉ đơn thuần là một script. Để biến nó thành một “người cộng tác” thực sự, chúng ta cần một “Voice” (Giọng nói) để chuyển các kết quả kỹ thuật này thành những thông tin dễ hiểu cho con người: đó chính là Synthesizer.
Bước 4: Phần tổng hợp (Voice)
Synthesizer đóng vai trò là khâu kiểm soát chất lượng cuối cùng của hệ thống. Nhiệm vụ của nó là xem xét ba vấn đề sau:
Vấn đề cốt lõi: Người dùng thực sự muốn gì?
Plan: Chúng ta đã quyết định thực hiện những bước nào?
Execution Trace: Kết quả đầu ra thực tế từ các công cụ của chúng ta là gì (khối lượng, các phép tính, v.v.)?
Thay vì chỉ đơn thuần đưa ra dữ liệu thô như 5,972e24 kg, Synthesizer sẽ kết hợp dữ liệu này thành một phản hồi tự nhiên và có tính thuyết phục. Tại đây câu hỏi đào sâu hơn dạng: “Vậy tiếp theo sẽ là gì” giúp dữ liệu trở nên hữu ích.
def __synthesize_answer(self, user_prompt, execution_results):
synthesis_prompt = (
"You are a helpful assistant. You have been given a user question"
"and a set of execution results from various tools. "
"Your goal is to provide a final, concise answer based on these results."
)
# We combine the history into a single 'context' string for the LLM
context = f"User Question: {user_prompt}\nResults: {execution_results}"
return self.call_llm(synthesis_prompt, context)
Khép lại vòng lặp: Vì sao cần phải thực hiện điều này?
Bằng cách tách riêng Planner, Executor và Synthesizer, bạn đã xây dựng một agent mạnh mẽ và ổn định hơn nhiều so với một chatbot cơ bản:
Auditability (Khả năng kiểm tra):
Nếu câu trả lời sai, bạn có thể kiểm tra Planner để xem logic có vấn đề không, hoặc kiểm tra Executor để xem công cụ có bị lỗi hay không.
Token Efficiency (Hiệu quả sử dụng token):
Bạn không bắt LLM phải đọc lại toàn bộ cuộc hội thoại liên tục; thay vào đó, bạn chỉ cung cấp đúng ngữ cảnh cần thiết cho từng nhiệm vụ cụ thể.
User Trust (Niềm tin của người dùng):
Bước tổng hợp cuối cùng (synthesis) giúp người dùng nhận được một câu trả lời rõ ràng, hoàn chỉnh, trong khi phần xử lý phức tạp với nhiều JSON ở giữa được ẩn đi.
Góc Chuyên gia: Sẵn sàng cho môi trường Doanh nghiệp
Một trong những bài học trong kỹ thuật AI là các mô hình học máy (LLM) thường rất khó để dự đoán. Ngay cả GPT-4 đôi khi cũng trả về JSON bị lỗi hoặc "tự đưa" một tham số không tồn tại. Trong khi thử nghiệm, đây là một lỗi nhỏ; trong môi trường doanh nghiệp, đó là một lỗi hệ thống.
Để chuyển từ một mẫu thử sang một agent cấp độ production, bạn cần nhiều lớp bảo vệ. Đây là gợi ý 3 lớp để bắt đầu:
1. Kiểm tra tính hợp lệ của lược đồ một cách nghiêm ngặt (Giới thiệu: Pydantic)
Chúng ta không nên chỉ dựa vào LLM để xử lý chính xác JSON. Thay vào đó, hãy sử dụng một thư viện như Pydantic để thực thi "contract" ở cấp độ code. Khi xác định các tool bạn sử dụng dưới dạng mô hình Pydantic, bạn có thể tự động xác thực output của LLM trước khi nó tác động đến các hàm của bạn.
from pydantic import BaseModel, ValidationError
class PlanetQuery(BaseModel):
planet: str
include_moons: bool = False # Default values add robustness
# If the LLM sends "world" instead of "planet", Pydantic catches it immediately.
2. Retry Loop “Tự sửa lỗi”
Trong triển khai này, chúng ta không chỉ “hy vọng” mô hình hoạt động; chúng ta xây dựng để đối phó với lỗi. Chúng ta sử dụng Retry Loop với khả năng bắt lỗi cụ thể. Nếu việc phân tích cú pháp JSON thất bại, agent không crash, mà nó sẽ thử lại.
Nếu quá trình validation thất bại, đừng chỉ để hệ thống dừng lại. Hãy dùng chính thông báo lỗi làm phản hồi.. Hãy gửi lại thông báo lỗi cho LLM và nói: “Bạn đã cung cấp cho tôi định dạng sai. Đây là lỗi: [ValidationError]. Vui lòng thử lại.”
max_retries = 3
attempts = 0
while attempts < max_retries and not success:
try:
response = self.call_llm(execution_system_prompt, user_prompt)
response_json = json.loads(response.output_text)
success = True
except (json.JSONDecodeError, KeyError):
attempts += 1
Tại sao điều này quan trọng: Mô hình 3 lớp thử này giúp tăng đáng kể độ ổn định của workflow có cấu trúc, giúp agent của bạn sẵn sàng hoạt động trong môi trường production chứ không chỉ là một dự án thử nghiệm.
3. Observability & Tracing
Trong môi trường doanh nghiệp, việc không hiểu tại sao agent lại chạy như vậy rất khó để chấp nhận. Bạn phải ghi lại mọi Suy nghĩ, Hành động và Quan sát. Chức năng “Execution Trace” này cho phép bạn kiểm tra quy trình ra quyết định của agent, đảm bảo rằng nếu một giao dịch trị giá 10.000 USD được kích hoạt, bạn sẽ có bằng chứng bằng văn bản về lý do đằng sau đó.
Bizfly Cloud tổng hợp