Prometheus + Grafana trên Kubernetes: Setup monitoring hoàn chỉnh cho DevOps
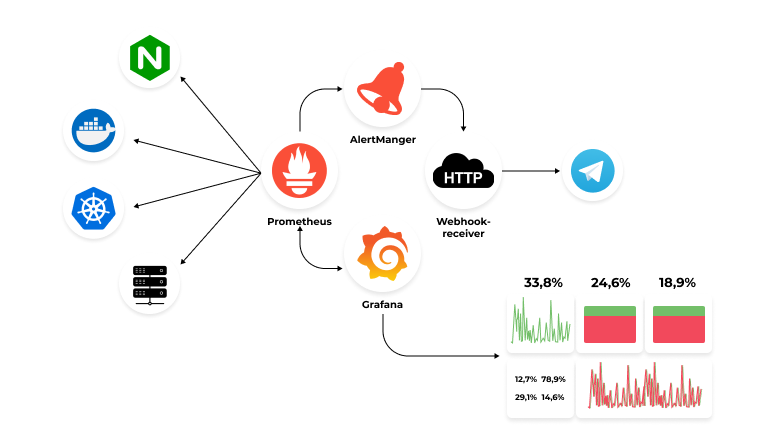
Nếu bạn là một DevOps junior, Kubernetes cluster đã chạy ổn định nhưng làm thế nào bạn biết K8s thực sự chạy ổn? Việc rà soát log thủ công hoặc chạy từng lệnh kubectl không chỉ tốn thời gian mà còn dễ bỏ sót lỗi. Nhiều người mới thường bỏ qua monitoring, khiến cluster dễ gặp các sự cố “thầm lặng”. Trong khi đó, các DevOps senior sử dụng Prometheus và Grafana để nắm bắt tình trạng hệ thống theo thời gian thực, phát hiện vấn đề trước khi chúng trở thành sự cố nghiêm trọng.
Vì sao lại là Prometheus và Grafana? Góc nhìn từ DevOps senior
Prometheus là hệ thống thu thập và lưu trữ dữ liệu dạng time-series, chuyên dùng để lấy các metric từ Kubernetes cluster. Grafana giúp chuyển những metric này thành các dashboard trực quan, dễ theo dõi và triển khai. Khi kết hợp với nhau, đây là bộ công cụ tiêu chuẩn để giám sát pod, node và service, mang lại cái nhìn tổng thể về trạng thái của cluster.
Sai lầm thường gặp của junior: Bỏ qua monitoring hoặc chỉ dựa vào kiểm tra thủ công, dẫn đến việc không phát hiện kịp thời các vấn đề như CPU hoặc memory sử dụng quá cao.
Cách làm của senior: Triển khai Prometheus để thu thập metric và Grafana để trực quan hóa dữ liệu, từ đó xử lý sự cố một cách chủ động thay vì bị động.
Trong hướng dẫn này, chúng ta sẽ sử dụng Minikube để triển khai Prometheus và Grafana, sau đó xây dựng một dashboard đơn giản để theo dõi tình trạng pod. Nội dung được chia thành ba “bí quyết” theo tư duy DevOps senior, nhưng được trình bày phù hợp cho người mới bắt đầu.
Bí quyết #1: Triển khai Prometheus chỉ với một lệnh bằng Helm
Nhiều DevOps junior thường cảm thấy “choáng ngợp” khi làm việc với các file YAML của Kubernetes, dành hàng giờ chỉnh sửa cấu hình và cuối cùng là… hệ thống không chạy như mong muốn. Điều này dễ gây nản và dẫn đến việc thiết lập không hoàn chỉnh.
Cách làm của senior: Sử dụng Helm để triển khai Prometheus chỉ với một lệnh duy nhất, tận dụng các Helm chart đã được cấu hình sẵn để có một hệ thống ổn định và đáng tin cậy ngay từ đầu.
Từng bước triển khai Prometheus
1. Thiết lập Minikube
Cài đặt Minikube và khởi động cluster bằng lệnh: minikube start
2. Cài đặt Helm
Tải Helm từ trang chính thức tại helm.sh và kiểm tra cài đặt với: helm version.
3. Thêm repository Helm của Prometheus
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
4. Deploy Prometheus:
kubectl create namespace monitoring
helm install prometheus prometheus-community/prometheus --namespace monitoring --set server.service.type=NodePort
Ý nghĩa của bước này:
Bước này sẽ cài đặt Prometheus vào namespace monitoring và cấu hình service kiểu NodePort để dễ dàng truy cập từ bên ngoài. Gói cài đặt bao gồm Prometheus server, có nhiệm vụ thu thập (scrape) các metric từ Kubernetes và lưu trữ chúng để phục vụ cho việc giám sát và phân tích.
5. Xác minh việc triển khai
Kiểm tra các pod:
Chạy lệnh kubectl get pods -n monitoring để đảm bảo tất cả pod của Prometheus đều đang ở trạng thái Running.
Truy cập giao diện Prometheus:
Chạy lệnh
kubectl port-forward -n monitoring svc/prometheus-server 9090
sau đó mở trình duyệt và truy cập http://localhost:9090.
Mẹo từ senior:
Sử dụng helm list -n monitoring để xác nhận Prometheus đã được cài đặt thành công, và dùng helm upgrade khi bạn cần tinh chỉnh cấu hình sau này.
Sai lầm cần tránh:
Tự viết YAML thủ công để triển khai Prometheus. Helm giúp bạn có một thiết lập sẵn sàng cho production với công sức tối thiểu và ít rủi ro hơn.
Bí quyết #2: Thêm Grafana và kết nối với Prometheus
Việc thường chỉ triển khai Prometheus rồi dừng lại, khiến các metric chỉ là những con số khô khan khó hiểu. Không có trực quan hóa, bạn sẽ bỏ lỡ bức tranh tổng thể về tình trạng hệ thống.
Gợi ý cách làm của senior:
Triển khai Grafana để xây dựng các dashboard trực quan và kết nối trực tiếp với Prometheus, từ đó biến metric thành thông tin dễ hiểu và có thể hành động ngay.
Thiết lập Grafana
1. Cài đặt Grafana bằng Helm:
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install grafana grafana/grafana --namespace monitoring --set service.type=NodePort
2. Lấy thông tin đăng nhập Grafana:
Chạy lệnh
kubectl get secret -n monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode
để lấy mật khẩu admin (tên đăng nhập mặc định là admin).
3. Truy cập Grafana:
Chạy lệnh
kubectl port-forward -n monitoring svc/grafana 3000:80
Sau đó truy cập http://localhost:3000 và đăng nhập bằng tài khoản admin cùng mật khẩu vừa lấy được.
4. Thêm Prometheus làm nguồn dữ liệu:
Trong Grafana, vào Connections > Data Sources > Add data source.
Chọn Prometheus.
Thiết lập URL:
http://prometheus-server.monitoring.svc.cluster.local:9090
Nhấn Save & Test.
Ý nghĩa:
Bước này triển khai Grafana và kết nối nó với Prometheus, cho phép bạn truy vấn metric và xây dựng dashboard trực quan.
Mẹo tham khảo:
Hãy lưu mật khẩu Grafana ở nơi an toàn hoặc tùy chỉnh mật khẩu thông qua Helm values khi triển khai môi trường production.
Lỗi có thể bạn cần tránh:
Dùng sai URL của Prometheus. Hãy kiểm tra kỹ tên service trong cluster của bạn.
Bí quyết #3: Tạo dashboard đơn giản để theo dõi tình trạng Pod
Nhiều Junior thường thu thập được metric nhưng không biết cách khai thác, khiến cluster không được giám sát các vấn đề quan trọng như pod bị crash hoặc tài nguyên tăng đột biến.
Cách làm của senior:
Xây dựng dashboard Grafana để trực quan hóa metric của pod, giúp dễ dàng phát hiện và khắc phục sự cố.
Tạo Dashboard theo dõi Pod
Triển khai ứng dụng thử nghiệm:
1. Tạo một pod Nginx đơn giản để sinh metric:
# nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
namespace: default
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
2. Áp dụng cấu hình:
Chạy lệnh: kubectl apply -f nginx-pod.yaml.
3. Tạo dashboard trong Grafana:
Vào Dashboards > New > New Dashboard.
Thêm một panel:
Query: rate(container_cpu_usage_seconds_total{namespace="default"}[5m])
Visualization: Line chart
Title: “Pod CPU Usage”
Thêm một panel khác:
Query: container_memory_working_set_bytes{namespace="default"}
Visualization: Gauge
Title: “Pod Memory Usage”
Lưu dashboard với tên “Pod Health Monitor”.
Ý nghĩa:
Dashboard này hiển thị mức sử dụng CPU và bộ nhớ của các pod trong namespace mặc định, giúp bạn dễ dàng theo dõi ứng dụng thử nghiệm.
Mẹo tham khảo:
Bạn có thể import dashboard dựng sẵn của Grafana (ID 6417) để giám sát toàn bộ Kubernetes cluster và tiết kiệm thời gian.
Lỗi cần tránh:
Bỏ qua dashboard. Việc trực quan hóa metric là chìa khóa để phát hiện sớm sự cố.
Quy trình của senior: Giám sát kỹ càng
- Cách các senior tiếp cận việc monitoring Kubernetes:
- Tận dụng Helm: Dùng chart để triển khai nhanh và ổn định.
- Tập trung metric quan trọng: Ưu tiên CPU, bộ nhớ và trạng thái pod.
- Xây dựng dashboard: Tạo các biểu đồ đơn giản nhưng dễ hành động.
- Quản lý phiên bản: Lưu Helm values và YAML trong Git.
Chuẩn bị cảnh báo: Thêm Prometheus Alertmanager để gửi thông báo (bước tiếp theo).
Thông điệp chính:
Monitoring là để có sự rõ ràng - hãy dùng Prometheus và Grafana để biến dữ liệu thô thành insight có thể hành động.
Những cạm bẫy thường gặp và cách tránh
Cấu hình thủ công: Dùng Helm để tránh lỗi YAML.
Sai URL: Kiểm tra kỹ tên service của Prometheus và Grafana.
Thiếu metric: Đảm bảo Prometheus đang scrape đúng namespace (kiểm tra ServiceMonitor).
Không có dashboard: Luôn tạo hoặc import dashboard.
Tài nguyên thừa: Dọn dẹp bằng
helm uninstall prometheus -n monitoring và
helm uninstall grafana -n monitoring.
Công cụ bạn cần
- Minikube: Test Kubernetes local.
- Helm: Triển khai Prometheus và Grafana.
- kubectl: Tương tác với cluster.
- Git: Quản lý version cấu hình.
- VS Code: Kèm extension YAML để chỉnh Helm values.
Bước xử lý tiếp theo
Bạn đã cài Prometheus và Grafana trên Kubernetes và xây dựng dashboard theo dõi pod! Giờ hãy nâng cấp:
Thêm Prometheus Alertmanager để gửi cảnh báo Slack hoặc email.
Theo dõi metric ứng dụng custom bằng Prometheus client libraries.
Triển khai lên cluster cloud (ví dụ BKE) để giám sát môi trường production.
Bạn đã sẵn sàng để làm chủ? Áp dụng những bí quyết monitoring này, cluster Kubernetes của bạn sẽ luôn ở trạng thái ổn định và ghi điểm lớn với cả team DevOps