Hãy cùng tìm hiểu TOON — Định dạng dữ liệu mới có thể thay thế JSON trong kỷ nguyên AI
Mỗi khi bạn mở một tệp JSON, bạn thường sẽ thấy các dấu ngoặc nhọn, dấu ngoặc kép và dấu phẩy có thể dài… bất tận.
Json đã là ngôn ngữ dữ liệu phổ quát của chúng ta trong nhiều thập kỷ, mang đến sức mạnh cho mọi thứ - từ API, Database cho đến cấu hình giao diện người dùng. Nhưng khi chúng ta tiến sâu hơn vào thế giới do AI và LLM điều khiển, JSON đang bắt đầu bộc lộ một số dấu hiệu lỗi thời.
Đó là khởi nguồn của ý tưởng về một mô hình mà dữ liệu giờ đây chỉ còn một nửa dung lượng, dễ đọc hơn, phân tích nhanh hơn và được thiết kế riêng cho các mô hình ngôn ngữ lớn (LLM).
Hãy cùng đến với Token-Oriented Object Notation (TOON) - định dạng dữ liệu mới được thiết kế để giúp việc giao tiếp của AI trở nên chuẩn xác hơn, tiết kiệm hơn và thông minh hơn.
Vì sao JSON lại trở thành một nút thắt
JSON đã phục vụ người dùng rất tốt, nhưng cấu trúc từng “thanh thoát” trước kia giờ đây trở nên cồng kềnh trong kỷ nguyên AI chú trọng đến token.
Các yếu tố khiến JSON trở nên chậm chạp:
Cú pháp dài dòng: Dấu ngoặc nhọn, dấu phẩy và dấu ngoặc kép xuất hiện phần lớn.
Sự lặp lại: Mỗi object lặp lại cùng một key name nhiều lần.
Chi phí token: Đối với các mô hình LLM như GPT hoặc Claude, mỗi ký hiệu thêm vào đều sẽ bị tính phí.
Chi phí phân tích cú pháp: Các tệp JSON lớn sẽ chậm hơn khi phân tích cú pháp, đặc biệt là đối với dữ liệu đồng nhất.
Không được tối ưu hóa cho AI: JSON được thiết kế cho máy móc, không phải cho các mô hình đọc token theo ngữ nghĩa.
Về bản chất, JSON “nói” quá nhiều. Trong khi TOON học cách “nói cùng một điều với một nửa số từ, và đây là sự khác biệt lớn nhất và bao hàm nhất.
Tổng quan nhanh về TOON
Hãy cùng xem TOON loại bỏ những chi tiết thừa mà vẫn giữ được sự rõ ràng.
Dưới đây là một ví dụ đơn giản:
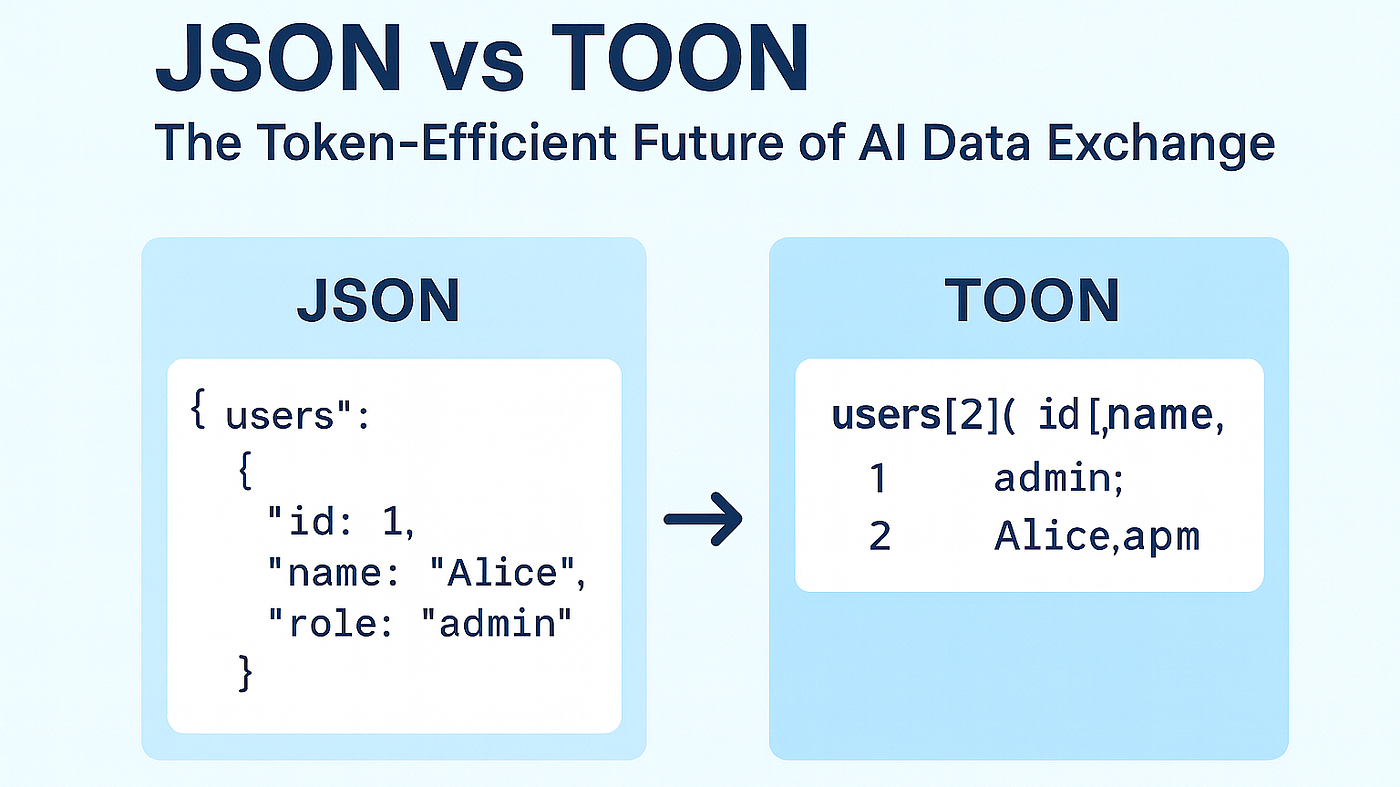
{ "name": "Alice", "age": 30, "city": "Bengaluru" }
name: Alice
age: 30
city: Bengaluru
Không dấu ngoặc nhọn, không dấu phẩy, không dấu ngoặc kép, chỉ có dữ liệu có ý nghĩa.
Arrays
JSON:
{ "colors": ["red", "green", "blue"] }
TOON:
colors: red,green,blue
Câu lệnh Toon cho ta thấy độ dài array. Các yếu tố khác đã không còn.
Array của Objects
JSON:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
TOON:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
Tại {id, name, role} quy định schema, và mỗi dòng đều tuân thủ thứ tự đó giúp câu lệnh thanh thoát và ngắn gọn hơn.
Nested Objects
JSON:
{
"user": {
"id": 1,
"profile": { "age": 30, "city": "Bengaluru" }
}
}
TOON:
user:
id: 1
profile:
age: 30
city: Bengaluru
Dễ đọc, có cấu trúc nhưng vẫn tối giản, TOON tạo cảm giác như một cầu nối giữa JSON và YAML, với hiệu quả như tích hợp sẵn LLM.
Tại sao TOON lại trở nên quan trọng
Xử lý Token hiệu quả
Trong JSON, mỗi dấu ngoặc nhọn và dấu phẩy đều làm tăng số lượng token.
TOON loại bỏ các ký tự dư thừa và key name lặp lại, giảm tải token lên đến 40–60% khi test trong thực tế.
Ví dụ: Cùng một câu lệnh
JSON → 257 token
TOON → 166 token
Nếu bạn đang sử dụng LLM với structured data, sự khác biệt này có thể giúp giảm chi phí và tăng tốc độ output cho bạn.
Hiểu Mô hình
TOON được thiết kế cho suy luận dựa trên token.
Vì vậy có cấu trúc phù hợp với cách LLM diễn giải thông tin, giúp dữ liệu có thể được “đọc”, hiểu và xử lý dễ dàng hơn.
Đơn giản cho người dùng
Các developer sẽ cực kỳ nhanh chóng làm quen với TOON nhờ tính “dễ đọc”. Các cấu trúc khác và thụt lề vẫn được giữ nguyên nhưng không còn dấu câu dày đặc như thường thấy.
Gọn nhẹ cho Dữ liệu Đồng nhất
Khi dataset của bạn có đến hàng ngàn hàng và khá tương đồng với nhau (như giao dịch, log hoặc event), lúc này TOON sẽ phát huy tối đa hiệu quả. Việc xử lý schema-first giúp TOON lý tưởng cho các bản ghi nhất quán.
Ví dụ thực tế: Dữ liệu cho một LLM Agent
Giả định bạn đang xây dựng một chatbot phân tích doanh số cho một công ty thương mại điện tử.
Mô hình của bạn cần truy cập vào hàng nghìn giao dịch hàng ngày.
JSON Version
{
"transactions": [
{ "id": "T1", "user": "U1", "amount": 120.00, "date": "2025-11-15", "category": "Electronics" },
{ "id": "T2", "user": "U2", "amount": 45.50, "date": "2025-11-14", "category": "Books" }
]
}
TOON Version
transactions[500]{id,user,amount,date,category}:
T1,U1,120.00,2025-11-15,Electronics
T2,U2,45.50,2025-11-14,Books
Kết quả:
Giảm 40% số token
Sơ đồ dễ hơn để mô hình phân tích
Tương tác LLM nhanh hơn và tiết kiệm hơn
AI Agent của bạn giờ đây có thể tập trung vào thông tin chi tiết, chứ không phải cú pháp.
Benchmarks và Token Savings
| Format | Size (KB) | Tokens | Parse Time (ms) |
| ------ | --------- | ------ | --------------- |
| JSON | 240 | 2600 | 145 |
| TOON | 145 | 1650 | 103 |
Ít văn bản hơn, ít mã thông báo hơn và xử lý nhanh hơn, đây chính xác là những gì quy trình làm việc AI hiện đại cần.
Tương lai của TOON
TOON còn non trẻ, nhưng tiềm năng của nó là không thể phủ nhận. Chúng ta có thể kỳ vọng vào một kịch bản tương lai:
- Các công cụ chuyển đổi như json2toon trong các hệ sinh thái lớn.
- Các dataset gốc LLM được xuất bản ở định dạng TOON.
- Các framework (LangChain, LlamaIndex, v.v.) khuyến khích áp dụng TOON để trao đổi dữ liệu nhỏ gọn.
- Tích hợp công cụ trong IDE và notebook để tự động chuyển đổi.
Theo thời gian, TOON có thể không thay thế hoàn toàn JSON, nhưng nó có khả năng trở thành ngôn ngữ được ưa chuộng giữa con người và máy móc trong các quy trình làm việc tập trung vào AI.