Scaling Kubernetes: Giới thiệu về event-driven autoscaling trong Kubernetes (KEDA)

Một cụm Kubernetes yêu cầu tài nguyên tính toán để chạy các ứng dụng và các tài nguyên này có thể cần tăng hoặc giảm tùy theo yêu cầu ứng dụng. Điều này thường thuộc loại "mở rộng quy mô” (scaling) và có thể được chia rộng rãi thành scaling cụm và ứng dụng.
Để đối phó với các yêu cầu ngày càng tăng, chẳng hạn như lưu lượng truy cập cao, bạn có thể mở rộng ứng dụng của mình bằng cách chạy nhiều phiên bản. Trong Kubernetes, điều này tương đương với việc mở rộng quy mô triển khai để thêm nhiều pod hơn.
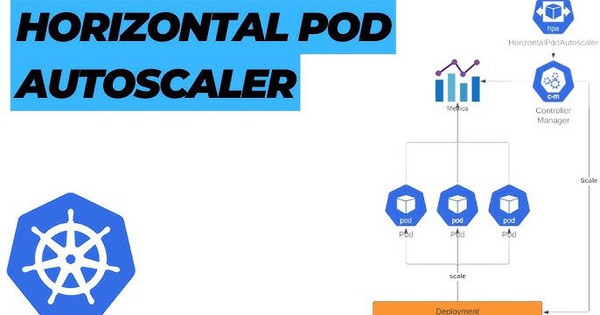
Bạn có thể làm điều đó theo cách thủ công, nhưng Horizontal Pod Autoscaler là một thành phần tích hợp có thể xử lý việc này tự động. Bạn cũng có thể cần phải chia tỷ lệ các node Kubernetes bên dưới, chẳng hạn như máy ảo, phiên bản bare-metal, v.v. Điều này cũng có thể được thực hiện theo cách thủ công, nhưng bạn có thể sử dụng cluster autoscaler để mở rộng cụm của bạn một cách tự động.
Bài viết này sẽ đề cập đến các thành phần mã nguồn mở có thể được sử dụng trên các Kubernetes primitives hiện có để giúp mở rộng các cụm Kubernetes cũng như các ứng dụng:
- Kubelet ảo, triển khai kubelet Kubernetes mã nguồn mở cho phép các Kubernetes node được hỗ trợ bởi các nhà cung cấp, bao gồm cả nền tảng serverless cloud.
- Kubernetes event-driven Autoscaling (KEDA) là một thành phần mã nguồn mở khác có thể được thêm vào bất kỳ cụm Kubernetes nào để thúc đẩy mở rộng quy mô của bất kỳ container nào dựa trên workload.
Trong bài viết này, bạn sẽ có cái nhìn tổng quan về KEDA, kiến trúc của nó và cách nó hoạt động đằng sau.
 - Ảnh 1.")
Tổng quát
KEDA (Kubernetes-based Event-driven Autoscaling) là một thành phần mã nguồn mở được phát triển bởi Microsoft và Red Hat để cho phép bất kỳ Kubernetes workload nào được hưởng lợi từ mô hình kiến trúc event-driven. Đây là một dự án CNCF chính thức và hiện là một phần của CNCF Sandbox. KEDA hoạt động bằng cách mở rộng quy mô theo chiều ngang của Kubernetes Deployment hoặc Job. Nó được xây dựng dựa trên Kubernetes Horizontal Pod Autoscaler và cho phép người dùng tận dụng External Metrics trong Kubernetes để xác định các tiêu chí tự động điều chỉnh quy mô dựa trên thông tin từ bất kỳ nguồn event nào, chẳng hạn như độ trễ của Kafka topic, độ dài của Hàng đợi hoặc số liệu thu được từ truy vấn Prometheus.
Bạn có thể chọn từ danh sách các trình kích hoạt được xác định trước (còn được gọi là Scalers), hoạt động như một nguồn sự kiện và chỉ số để tự động điều chỉnh quy mô một Deployment (hoặc một Job). Chúng có thể được coi là các bộ adapter chứa logic cần thiết để kết nối với nguồn bên ngoài (ví dụ: Kafka, Redis, Queue) và tìm nạp các số liệu cần thiết để thúc đẩy các hoạt động tự động thay đổi quy mô. KEDA sử dụng mô hình Kubernetes Operator model, trong đó xác định Custom Resource Definitions, chẳng hạn như ScaledObject mà bạn có thể sử dụng để tính cấu hình autoscaling.
Kiến trúc cấp cao
Ở cấp độ cao, KEDA thực hiện hai điều để thúc đẩy quá trình autoscaling:
- Cung cấp một thành phần để kích hoạt và hủy kích hoạt Deployment để mở rộng quy mô đến và từ 0 khi không có event nào
- Cung cấp Kubernetes Metrics Server để hiển thị dữ liệu event (ví dụ: độ dài hàng đợi, độ trễ topic)
 - Ảnh 2.")
KEDA sử dụng ba thành phần để hoàn thành nhiệm vụ của mình:
- Scaler: Kết nối với một thành phần bên ngoài (ví dụ: Kafka) và tìm nạp các chỉ số (ví dụ: độ trễ topic)
- Operator (Tác nhân): Chịu trách nhiệm “kích hoạt” một Deployment và tạo một đối tượng Horizontal Pod Autoscaler
- Metrics Adapter: Trình bày các chỉ số từ các nguồn bên ngoài vào Horizontal Pod Autoscaler
Hãy đi sâu hơn vào cách các thành phần này hoạt động cùng nhau.
Scaler
Như đã giải thích trước đó, một Scaler được định nghĩa bởi manifest ScaledObject (Tài nguyên tùy chỉnh). Nó tích hợp với nguồn bên ngoài hoặc các trình kích hoạt được xác định trong ScaledObject để tìm nạp các chỉ số cần thiết và hiển thị chúng cho KEDA metric server. KEDA tích hợp nhiều nguồn và cũng có thể thêm các scaler khác hoặc các nguồn số liệu bên ngoài bằng cách sử dụng giao diện có thể cài cắm được.
Một số scaler bao gồm:
- Apache Kafka: dựa trên độ trễ Kafka topic
- Redis: dựa trên độ dài của danh sách Redis
- Azure Service Bus: dựa trên hàng đợi hoặc chủ đề của Azure Service Bus
- Google Cloud Platform Pub/Sub: dựa trên một số thông báo trong đăng ký GCP Pub/Sub
- Prometheus: dựa trên kết quả của một truy vấn PromQL
KEDA Operator bao gồm một bộ điều khiển (controller) thực hiện “vòng điều chỉnh” và hoạt động như một tác nhân để kích hoạt và hủy kích hoạt một triển khai để mở rộng quy mô từ 0. Điều này được thúc đẩy bởi KEDA-operator container chạy khi bạn cài đặt KEDA.
Nó “phản ứng” với việc tạo ra tài nguyên ScaledObject bằng cách tạo Horizontal Pod Autoscaler (HPA). Điều quan trọng cần lưu ý là KEDA chịu trách nhiệm mở rộng quy mô triển khai từ 0 thành một trường hợp và điều chỉnh nó trở lại 0 trong khi HPA đảm nhận việc tự động điều chỉnh quy mô Deployment từ đó.
Tuy nhiên, Horizontal Pod Autoscaler cũng cần các số liệu để làm cho tính năng tự động điều chỉnh quy mô hoạt động. Nó lấy số liệu từ đâu? Từ Metrics Adapter!
Metrics Adapter
Ngoài việc xác định một Custom Resource Definition và bộ điều khiển/ điều hành để hoạt động dựa trên nó, KEDA cũng triển khai và hoạt động như một máy chủ cho các chỉ số bên ngoài. Nói một cách chính xác, nó triển khai API số liệu bên ngoài Kubernetes (Kubernetes External Metrics API) và hoạt động như một “adapter” để dịch các chỉ số từ các nguồn bên ngoài (đã đề cập ở trên) sang một dạng mà người dùng Horizontal Pod Autoscaler có thể hiểu và sử dụng để thúc đẩy quá trình autoscaling.
Bạn có thể sử dụng KEDA như thế nào?
Dưới đây là cái nhìn sơ lược về cách một người có thể sử dụng KEDA từ quan điểm của một developer. Khi nó được cài đặt vào cụm Kubernetes của bạn, đây là cách bạn thường sử dụng KEDA:
- Tạo Deployment (hoặc một Job): Đây chỉ đơn giản là ứng dụng bạn muốn KEDA mở rộng quy mô dựa trên kích hoạt quy mô. Ngoài điều đó ra, nó hoàn toàn độc lập.
- Tạo ScaledObject: Đây là định nghĩa tài nguyên tùy chỉnh, với đó bạn có thể xác định nguồn của số liệu, cũng như các tiêu chí autoscaling.
Sau khi hoàn thành việc này, KEDA sẽ bắt đầu thu thập thông tin từ nguồn sự kiện và định hướng autoscaling cho phù hợp. Dưới đây là một ví dụ về một ScaledObject, định nghĩa cách autoscale một danh sách Redis được gọi là bộ xử lý đang chạy trong một cụm với tư cách là Kubernetes Deployment.
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: redis-scaledobject
namespace: default
labels:
deploymentName: processor
spec:
scaleTargetRef:
deploymentName: processor
pollingInterval: 20
cooldownPeriod: 200
minReplicaCount: 0
maxReplicaCount: 50
triggers:
- type: redis
metadata:
address: redis:6739
listName: jobs
listLength: "20"
authenticationRef:
name: redis-auth-secret
Lưu ý rằng định nghĩa ScaledObject phần lớn được chia thành hai phần: một phần chung chung và phần còn lại dành riêng cho nguồn sự kiện (Redis đã được sử dụng làm ví dụ).
Các thông số chung bao gồm:
- scaleTargetRef.deploymentName: tên của Deployment bạn muốn tự động xếp tỷ lệ
- minReplicaCount: số lượng bản sao tối thiểu mà KEDA sẽ mở rộng quy mô triển khai xuống. Bạn có thể giảm tỷ lệ xuống 0, nhưng có thể sử dụng bất kỳ giá trị nào khác
- cooldownPeriod: khoảng thời gian chờ sau khi trình kích hoạt cuối cùng được báo cáo hoạt động trước khi mở rộng quy mô triển khai trở lại minReplicaCount
- pollingInterval: khoảng thời gian để kiểm tra từng trình kích hoạt trên
- maxReplicaCount: số lượng bản sao tối đa mà KEDA sẽ mở rộng quy mô triển khai đến
Nguồn sự kiện hoặc các thông số cụ thể của trình kích hoạt là:
- triggers.type: nguồn sự kiện đang được sử dụng (ví dụ redis)
- triggers.metadata: các thuộc tính khác với trình kích hoạt (ví dụ: trong trường hợp redis, địa chỉ của nó là listName và listLength)
- triggers.authenticationRef: cho phép bạn tham chiếu đến một đối tượng TriggerAuthentication, là một đối tượng cụ thể khác của KEDA để nắm bắt cơ chế xác thực của nguồn sự kiện
Kết luận
KEDA là một thành phần đơn giản có thể được thêm vào bất kỳ cụm Kubernetes nào để mở rộng chức năng của nó. Nó có thể được sử dụng để autoscale nhiều workload khác nhau, từ triển khai truyền thống đến FaaS (serverless functions).
Bạn có thể chọn và định cấu hình các ứng dụng cụ thể (Deployment và Job) một cách rõ ràng mà bạn muốn KEDA tự động điều chỉnh quy mô mà không ảnh hưởng đến các thành phần khác. KEDA sẽ đảm bảo rằng ứng dụng của bạn được thu nhỏ xuống 0 phiên bản (có thể định cấu hình), trừ khi có việc phải làm. Và cuối cùng nhưng không kém phần quan trọng, nó có thể mở rộng. Bạn có thể tích hợp các nguồn sự kiện tùy chỉnh dưới dạng bộ điều chỉnh tỷ lệ để thúc đẩy quá trình autoscaling.
Để biết thêm thông tin liên quan đến Kubernetes hãy theo dõi thêm những bài viết tiếp theo của Bizfly Cloud nhé.
>> Có thể bạn quan tâm: Kubernetes Ingress là gì? Cách tạo Kubernetes Ingress bằng NGINX Controller.