Làm thế nào để tiết kiệm token (tiếp)
Route đến các model dựa trên độ khó của tác vụ
Request-level routing có nghĩa là cố gắng ước tính độ khó và mục đích trước khi thấy bất kỳ output nào. Ưu điểm rất cao, nhưng một lựa chọn sai có thể làm hỏng toàn bộ session, vì vậy cần lưu ý một số nhược điểm về chất lượng.
Để làm điều này, bạn cần một router model nào đó quyết định route request tới đâu.

Chúng ta có thể cân nhắc RouteLLM từ LMSYS, team tại Berkeley với Chatbot Arena. Giải pháp này học hỏi từ preference data thực tế từ Chatbot Arena.
RouteLLM sử dụng các embedding tiêu chuẩn và một router nhỏ, vì vậy việc lưu trữ nó sẽ không quá tốn kém.
Có báo cáo rằng công cụ giúp giảm chi phí đáng kể trong khi vẫn giữ được hầu hết hiệu năng của GPT-4.
Tuy nhiên, theo bài báo LLMRouterBench, trong đó về cơ bản nói rằng nhiều router được học máy hầu như không vượt trội hơn các phương pháp cơ bản đơn giản, như keyword/heuristic routing, embedding nearest-neighbor, hay kNN-style routing..

Điều này có nghĩa là các router cao cấp hiện nay có thể không mang lại nhiều cải thiện so với việc sử dụng một thiết bị đơn giản.
Mọi người không từ bỏ việc sử dụng định tuyến vì lý do này, nhưng họ vẫn đang mày mò cải tiến nó, vì vậy nếu chất lượng phản hồi không theo kịp thì nó không phải là giải pháp tiết kiệm hoàn toàn.
Hiện nay, cũng có những giải pháp có sẵn trong lĩnh vực này, như OpenRouter Auto và Switchpoint. Tuy nhiên, không có thông tin nào được công bố về cấu trúc bên trong của hệ thống routing hoặc số liệu về độ chính xác mà bạn có thể quan tâm.
Một số thiết bị đang được thử nghiệm bao gồm: LLMRouter, heuristics, self-hosted classifier, LLM-as-router, RouteLLM, OpenRouter Auto.
Bắt đầu với model rẻ và chỉ nâng cấp khi độ tin cậy thấp
Thay vì cố đoán từ prompt xem một request là “dễ” hay “khó”, ta có thể để model rẻ xử lý trước, rồi mới quyết định có chấp nhận câu trả lời đó hay chuyển lên model mạnh hơn.
Bài viết “Speculative Cascades” của Google mô tả chính xác kiểu đánh đổi này: dùng các model nhỏ trước để tối ưu chi phí và tốc độ, sau đó chỉ chuyển sang model lớn khi thực sự cần thiết.
Để làm điều đó, bạn cho model rẻ generate câu trả lời trước, rồi dùng một bộ kiểm tra nhẹ (lightweight checker) để đánh giá chất lượng đầu ra dựa trên các yếu tố như:
- logprobs / xác suất token,
- entropy hoặc mức độ bất định kiểu margin,
- và/hoặc mức độ semantic alignment (độ khớp ngữ nghĩa).

Ý tưởng này khá hấp dẫn, vì độ khó của prompt thường rất khó dự đoán và phần lớn các hệ thống router cũng không hoạt động hoàn hảo. Hơn nữa, việc đánh giá chất lượng thường dễ hơn sau khi đã có câu trả lời.
Cách tiếp cận này cũng chỉ hợp lý nếu bạn tin rằng phần lớn câu hỏi có thể được xử lý bởi model đơn giản hơn, bởi với những request bị escalate thì bạn sẽ phải trả chi phí cho hai lần gọi model.
Tuy vậy, theo những người đang triển khai thực tế, đây vẫn là một lựa chọn đáng cân nhắc vì độ trễ của bước validation giữa hai lần gọi có thể giữ dưới 20ms.
Ủy quyền công việc cho các subagent
Subagent là cách phân chia công việc cho các agent độc lập xử lý riêng từng phần. Trong nhiều trường hợp, các subagent này dùng model nhỏ hơn, nên về bản chất cũng có thể xem đây là một dạng routing.
Mức tiết kiệm chi phí ở đây không quá lớn, nhưng vẫn đáng để nhắc tới.
Việc dùng subagent không chỉ nhằm giảm chi phí. Nó còn giúp giữ context sạch hơn để mỗi agent có thể tập trung hoàn toàn vào đúng nhiệm vụ mà nó cần xử lý.
Anthropic hiện tích hợp sẵn cơ chế subagent trong Claude Code, điều mà nhiều người có lẽ đã thấy. Ví dụ, subagent “Explore” được thiết kế rõ ràng như một worker dùng model Haiku để tìm kiếm và khám phá codebase. Tức là nguyên tắc thiết kế ở đây rất rõ: dùng model nhỏ cho các tác vụ rẻ và đơn giản hơn.
Session Claude chính cũng thực hiện việc delegate dựa trên mô tả tác vụ (description matching), nhưng người dùng không nhìn thấy quá trình đó. Thứ chúng ta thấy chỉ là tổng chi phí thấp hơn sau cùng.
Nhưng vì orchestrator vẫn tham gia vào quá trình lập kế hoạch, tổng hợp và thử lại, nên bạn không tiết kiệm được nhiều như khi sử dụng định tuyến.

Giữ cho context luôn gọn gàng
Context engineering tốt thường được nhắc tới dưới góc độ hiệu năng, nhưng thực tế nó cũng ảnh hưởng trực tiếp tới hiệu quả chi phí. Vì vậy, hãy cùng nói về context compaction và cách việc giữ context sạch có thể giúp tiết kiệm token.
Vấn đề là agent thường liên tục tích tụ “rác” theo thời gian: output từ tool, log, các quan sát lặp lại, kế hoạch cũ, những lần thử đã lỗi thời, hay trạng thái bị trùng lặp.

Điều này đặc biệt phổ biến với những người lần đầu xây dựng agent, khi họ liên tục đổ toàn bộ kết quả vào working state của agent chính.
Phần khó là xây dựng một state pipeline
Đây là một vấn đề hai cấp. Bạn không chỉ "nén đoạn hội thoại" mà còn cần giữ cho mọi thứ gọn gàng khi thêm chúng vào trạng thái hoạt động, đây là công việc kỹ thuật tốn nhiều thời gian.
Đầu tiên, để giữ cho context clean, chúng ta không muốn loại kết quả này bắt đầu chiếm dụng context.
bad state:
agent does work
→ dumps tool output into context
→ reads files
→ dumps files into context
→ runs tests
→ dumps logs into context
→ retries
→ keeps everything
Vì vậy, công việc thực sự quan trọng trước tiên là duy trì state chính xác trong khi loại bỏ các dữ liệu không cần thiết trong quá trình hoạt động.
Raw output như thế này có thể được store, và chỉ những gì cần thiết mới được đưa vào active context. Nói chung, thứ gây cản trở ở đây có lẽ là sự phình to tool-output, vì vậy công việc cần làm là làm cho các công cụ ít gây nhiễu hơn một cách mặc định.
Good active context
[system rules]
[project rules]
[user task]
[current working state]
Keep:
+ auth flow lives in auth.ts + session.ts
+ bug only happens on refresh path
+ failing test: session_refresh_keeps_user
+ likely overwrite during refresh
+ files in scope: auth.ts, session.ts, auth.test.ts
Drop:
- raw grep results
- full test logs
- duplicate file dumps
- dead-end retries
Nếu đọc thêm tài liệu của Anthropic về các tác vụ dài hạn (long-horizon tasks), họ cũng nhấn mạnh rằng khi bắt đầu nén context, bạn cần tìm cách giữ lại những thứ quan trọng như: các quyết định kiến trúc, những bug chưa được giải quyết và các chi tiết triển khai quan trọng.
Còn với cơ chế autonomous compression của LangChain, họ để chính agent quyết định khi nào nên compact context, thay vì chỉ thực hiện sau khi context đã bị phình to, điều mà có thể Anthropic hiện đang làm.
Tổng kết
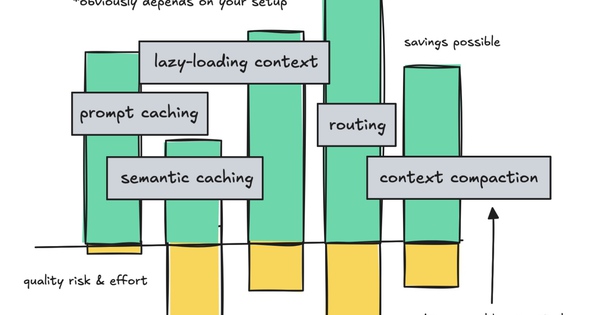
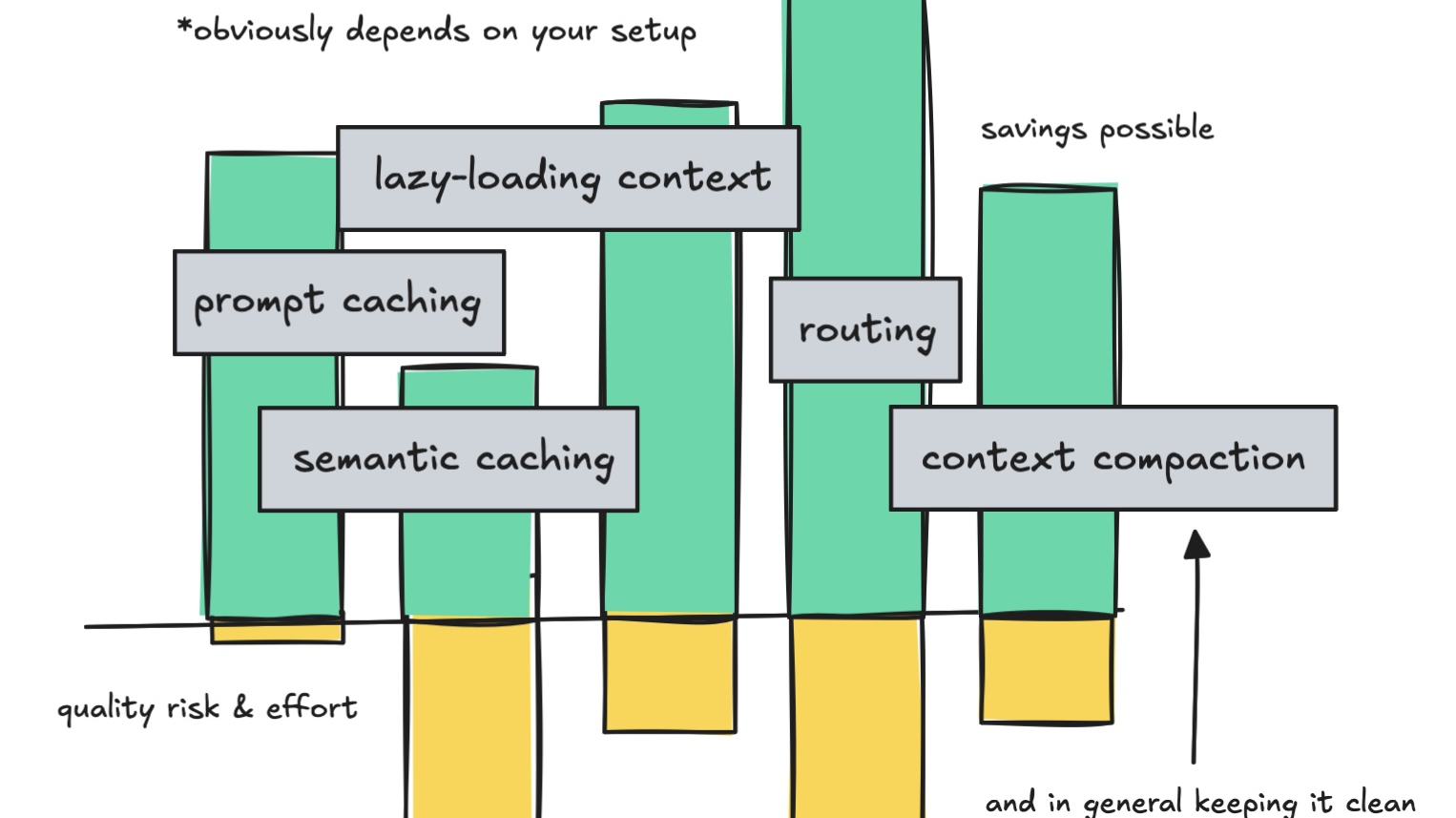
Lựa chọn cách phù hợp nhất sẽ phụ thuộc nhiều vào use case của bạn: dùng prompt caching khi phải làm việc với các system prompt lớn nhưng ít thay đổi qua nhiều vòng gọi LLM, dùng semantic caching nếu bạn đang xây một chatbot Q/A phổ thông và muốn tối ưu chi phí.
Hãy thử routing nếu hệ thống của bạn cần xử lý cả câu hỏi dễ lẫn khó. Và nếu muốn tránh gửi những token không cần thiết, hãy giữ context sạch và gọn nhất có thể.