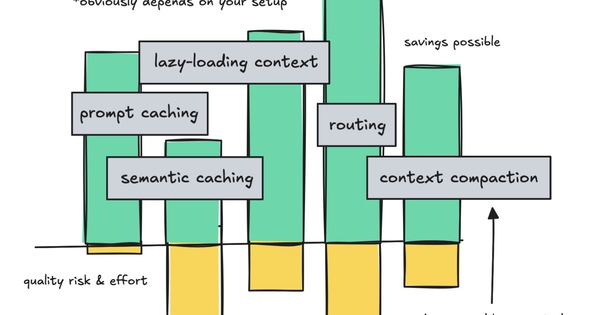
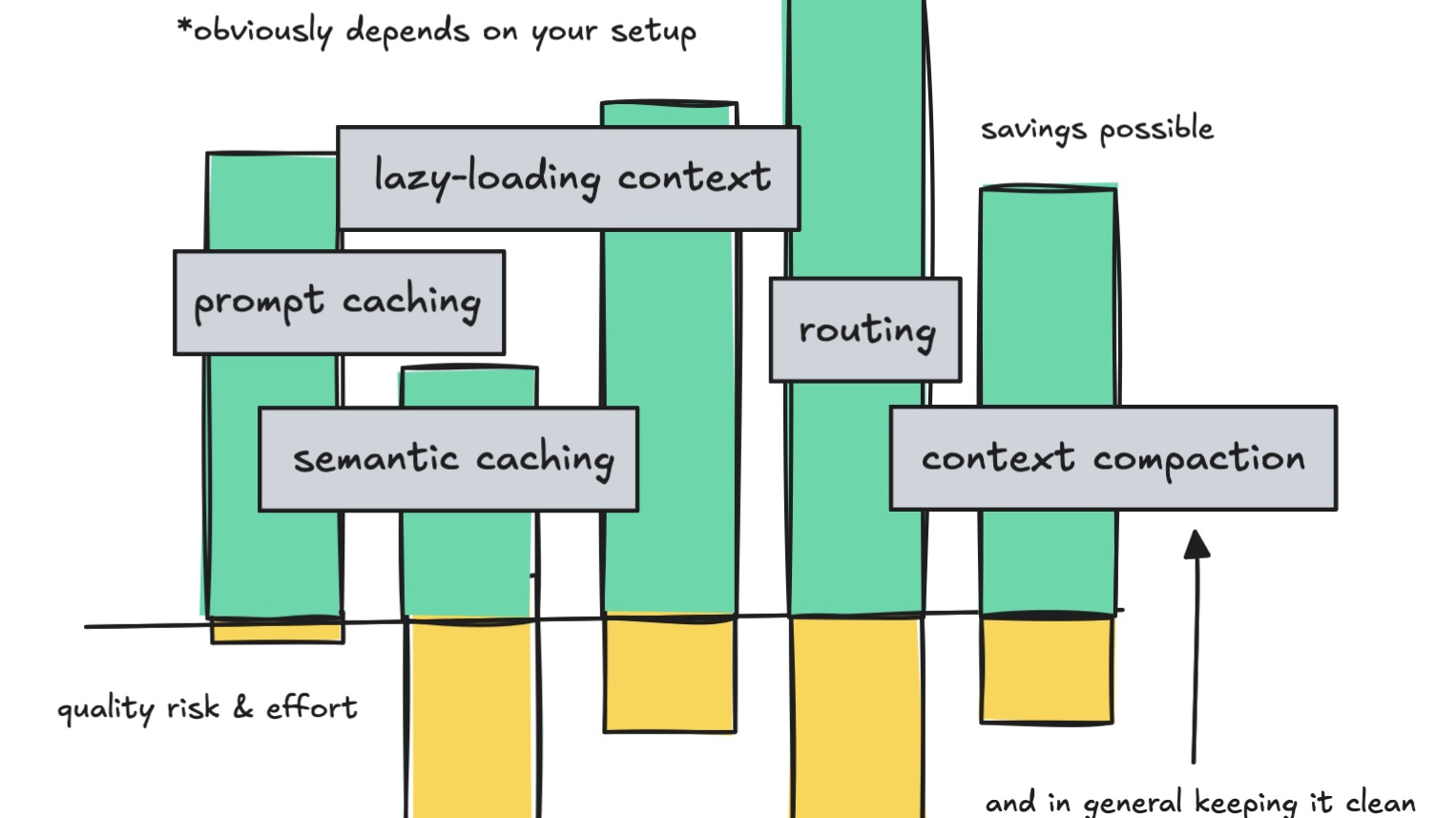
Làm thế nào để tiết kiệm token (II)
Semantic caching
Việc khớp ngữ nghĩa dựa trên ý nghĩa, tức là nếu yêu cầu đủ tương đồng, trả về kết quả đã được lưu trong bộ nhớ cache. Mặc dù nghe có vẻ dễ dàng, nhưng vẫn có những vấn đề chúng ta cần phải lưu ý.
Để khớp văn bản về mặt ngữ nghĩa, chúng ta sử dụng embedding. Bạn có thể tìm hiểu thêm nếu thuật ngữ này còn mới mẻ với bạn.
Về bản chất, embedding là các vectơ mà chúng ta có thể so sánh với nhau bằng cách sử dụng độ tương đồng cosine. Nếu độ tương đồng cao, ý nghĩa sẽ tương tự, mặc dù điều này phụ thuộc vào mô hình.

Ý tưởng của việc semantic caching là khớp các yêu cầu tương tự với các câu trả lời đã tồn tại. Ví dụ, khi hỏi "Thủ đô của Pháp là gì?" và "Nhanh lên, cho tôi biết thủ đô của Pháp", kết quả trả về sẽ giống nhau.
Không cần sử dụng mô hình tuyến tính logic (LLM) để trả lời cùng một câu hỏi nhiều lần.
Cache này sẽ hiệu quả nếu nhiều người hỏi những câu hỏi chung chung gần giống nhau và dữ liệu không bị outdate quá nhanh.
Vậy tại sao không làm điều đó cho mọi trường hợp? Có rất nhiều “cạm bẫy” ở đây.
Đầu tiên, chúng ta cần xem xét ngưỡng tương đồng là bao nhiêu, câu trả lời nên được giữ hiệu lực trong bao lâu, và điều gì xảy ra với các câu hỏi nhiều lượt trả lời.
Sau đó, bạn cần nghĩ về những gì thực sự được cache, liệu có nên triển khai route hay không, làm thế nào để phân tách người dùng và điều gì xảy ra nếu câu trả lời sai được cache.
Bạn cũng cần xem xét (Time To Live – TTL), tức là khi nào thông tin trở nên outdate và đối với những câu hỏi nào.
Vì vậy, mặc dù cơ chế khá đơn giản, bạn vẫn cần các filter và tag cho metadata, như user, workspace, corpus version, chân dung người dùng, phạm vi phiên/người dùng, TTL thông minh và một số quy tắc cho việc "liệu kết quả trả về có đủ hay không?".
Và do đó sau đó công việc trở thành một dự án khá phức tạp.
Vì vậy, nếu muốn triển khai theo hướng này, bạn có thể dùng semantic index để tìm một câu hỏi đã từng xuất hiện trước đó. Nhiều câu hỏi khác nhau có thể cùng trỏ tới một câu trả lời đã lưu, từ đó giảm tình trạng phình to dung lượng lưu trữ.
Bạn cũng nên quản lý TTL (thời gian sống của cache) một cách thông minh dựa trên mức độ sử dụng: nếu một mục được tái sử dụng thường xuyên thì giữ lại lâu hơn, còn nếu ít dùng thì nên xóa đi.
Ngoài ra, tôi khuyên chỉ nên triển khai sau khi bạn thực sự thấy có sự lặp lại trong log, thay vì làm ngay từ đầu. Có thể use case của bạn vốn không phù hợp với semantic caching.
Về cách triển khai, nhiều cơ sở dữ liệu hiện nay đã hỗ trợ sẵn tính năng này. Ngoài ra còn có các thư viện như semanticcache, prompt-cache, GPTCache, vCache, Upstash semantic-cache, hay Redis + LangCache giúp xử lý phần plumbing/infrastructure phía dưới.
Trước khi chuyển sang phần tiếp theo, có một lưu ý lớn rằng việc sử dụng caching tiêu chuẩn cũng mang lại nhiều lợi ích tiết kiệm.
Hãy nhớ chỉ cache những dữ liệu tốn kém và mang tính xác định như kết quả truy vấn SQL, tool output và kết quả truy xuất. Đừng bao giờ chạy những thứ này nhiều hơn mức cần thiết.
Có thể kết luận semantic caching là một khái niệm thú vị và có thể giúp bạn tiết kiệm token trong một số trường hợp sử dụng nhất định, nhưng cần có kỹ thuật để thực hiện nó một cách hiệu quả.
Không nên preload các token không active
Phần này nói về những gì xảy ra khi system prompt bắt đầu phình to do các công cụ cồng kềnh hoặc bộ nhớ tăng lên.
Đối với các agent nhỏ hơn, điều này không thực sự là vấn đề, nhưng nếu bạn đang làm việc với các agent specs ngày càng lớn, có những cách để thu nhỏ lại và lấy thông tin theo yêu cầu (hoặc ít nhất là cố gắng làm vậy).
Giữ cho context đơn giản và chỉ lấy thông tin chi tiết khi cần
Khi agent prompt phát triển vượt quá một điểm nhất định, cần giữ cho layer luôn được tải càng nhỏ và ổn định càng tốt, đồng thời tách biệt các thông tin chi tiết đang phát triển.
Điều này rất quan trọng vì khi các layer này bắt đầu phát triển, ví dụ như khi bạn tải vài trăm công cụ hoặc liên tục gửi thay đổi mô tả máy chủ MCP đầy đủ, mọi thứ sẽ khá cồng kềnh.

Vấn đề rõ ràng không chỉ nằm ở chi phí, mà còn ở hiệu năng. Và nếu một trong những layer này liên tục thay đổi, việc truy cập prompt caching nhanh chóng sẽ trở nên khó khăn hơn nhiều.
Vì vậy, ý tưởng là giữ cho top layer càng nhỏ gọn và ổn định càng tốt. Top layer nên giúp model hiểu nó đang ở đâu và nên đi tiếp theo hướng nào chứ không cần phải mang toàn bộ thông tin vào prompt ngay từ đầu.

Nếu bạn từng xem qua source code của Claude Code, bạn sẽ thấy rằng họ sử dụng một hệ thống quản lý bộ nhớ tương tự như thế này.
Họ có một index file always-loaded - luôn được tải - và không được vượt quá 200 dòng, cùng với các topic file chi tiết ở nơi khác. Tuy nhiên, những gì agent thực hiện trên thực tế so với những gì hệ thống mong muốn lại là một câu chuyện khác.
Bạn cũng có thể thấy ý tưởng tương tự xuất hiện ở những nơi khác, như trong tool setup nâng cao của Claude, setup phân lớp của Claude Skills, và các nỗ lực thực hiện lazy-load MCP tool thay vì đưa tất cả các định nghĩa máy chủ vào prompt ngay từ đầu.
Việc này được thực hiện ở đâu và liệu nó có hiệu quả không?
Ý tưởng này rất hay. Khi context mở rộng, việc chọn đúng hành động sẽ trở nên khó khăn hơn cho LLM. Nhưng đây vẫn là giai đoạn đầu, vậy chúng ta sẽ lấy 1 tool làm ví dụ để xem cách nó hoạt động như thế nào.
Vài tháng trước, Anthropic đã phát hành công cụ Tool Search. Công cụ này giúp giải quyết yêu cầu về context gọn nhẹ trong khi vẫn cung cấp cho mô hình quyền truy cập vào hàng trăm công cụ.
Anthropic cho biết họ đã từng thấy từ 55K đến 134K token định nghĩa công cụ khi chưa tối ưu, và việc lựa chọn công cụ sai là một lỗi thường gặp khi context trở nên lớn như vậy.

Vì vậy, một search tool sẽ tối ưu hóa context khi cho phép LLM sử dụng nó để tìm các công cụ, thay vì định nghĩa tất cả chúng ngay từ đầu.
tools=[
{
"type": "tool_search_tool_bm25_20251119",
"name": "tool_search"
},
{
"name": "search_contacts",
"description": "Find a contact by name or email.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
},
{
"name": "send_email",
"description": "Send an email to one or more recipients.",
"input_schema": {
"type": "object",
"properties": {
"to": {"type": "string"},
"subject": {"type": "string"},
"body": {"type": "string"}
},
"required": ["to", "subject", "body"]
},
"defer_loading": True
}
]
Ở ví dụ trên, chúng ta định nghĩa một tool tên là tool_search. Bạn có thể chọn một trong các cơ chế có sẵn như BM25 hoặc Regex, hoặc tự xây dựng một cơ chế tìm kiếm riêng.
Sau đó, chúng ta đánh dấu một tool là deferred để làm ví dụ. Tuy nhiên, cách này thường chỉ thực sự cần thiết khi bạn có hơn 10 tool trở lên.
Anthropic xử lý phần tìm kiếm tool thay cho bạn, nên bạn sẽ không thấy cách họ chèn schema của tool vào system prompt, cũng như không thấy quá trình search diễn ra phía dưới như thế nào.
Tuy vậy, họ có nói rằng khi tìm được tool phù hợp, phần định nghĩa của tool đó sẽ được append trực tiếp vào cuộc hội thoại dưới dạng một block tool_reference để LLM sử dụng.

Ý tưởng này khá hay: giảm kích thước context ban đầu, nhưng đổi lại bạn phải thêm một bước search trung gian. Mọi người cũng đã thử nghiệm cách làm này, dù kết quả ban đầu chưa thực sự quá ấn tượng — tuy nhiên các thử nghiệm đó được thực hiện với khoảng 4.000 tool, nên vẫn còn nhiều không gian để tối ưu và kiểm chứng thêm.
Ngoài ra, trách nhiệm cũng nằm ở phía chúng ta: phải định nghĩa tool đủ tốt để chúng có thể được tìm kiếm chính xác. Nhưng việc debug cũng trở nên khó hơn khi bạn không nhìn thấy bước trung gian đang diễn ra như thế nào.
Ý tưởng này thực ra xuất hiện ở nhiều nơi khác nữa, chỉ là mọi người thường gọi nó bằng cái tên chung hơn: “AI engineering tốt”. Nghĩa là đừng nhét cho agent một context khổng lồ và lộn xộn ngay từ đầu. Thay vào đó, hãy cho nó một cơ chế để thu hẹp phạm vi trước, rồi chỉ tải hoặc inspect tool khi thực sự cần.
Ở khía cạnh này, bạn cũng có thể tiết kiệm được kha khá chi phí, dù mức tiết kiệm còn phụ thuộc vào số token bạn gửi vào ban đầu. Chúng tôi cũng tạo thêm một công cụ tính toán để so sánh giữa tool search và prompt caching.

Kết quả cho thấy cả prompt caching lẫn lazy-loading context đều giúp tiết kiệm token, nhưng khi kết hợp lại thì mức thay đổi không quá lớn. Dù vậy, kiểu tool search này không chỉ nhằm tiết kiệm chi phí - nó còn giúp giữ cho context “sạch” hơn về mặt hiệu năng.
Nhưng nếu mục tiêu chính của bạn chỉ là tiết kiệm chi phí, thì thắng lợi lớn nhất là: hãy chọn triển khai ít nhất một trong hai cách.
Sử dụng model chi phí thấp cho công việc giá trị thấp
Phần này nói về việc routing các prompt đến các model khác nhau, cùng với việc sử dụng các subagent với các model rẻ hơn cho một số tác vụ nhất định, và phân tích về việc giảm chi phí token nhưng cũng tiềm ẩn rủi ro về chất lượng.
Phần này rất thú vị vì hầu hết mọi người cho rằng 60% các câu hỏi đến hoặc hơn là những tác vụ dễ dàng, và do đó không cần mô hình mạnh nhất, đặc biệt là mô hình tư duy.
ChatGPT sử dụng các tín hiệu như loại hội thoại, độ phức tạp, nhu cầu công cụ và ý định rõ ràng . Claude sử dụng ủy quyền dựa trên mô tả và các subagent tích hợp sẵn như Explore.
Ý tưởng rất dễ hiểu, nhưng làm thế nào để thực hiện đúng cách mà không gây rủi ro quá nhiều về chất lượng mới là phần khó.
Vậy, chúng ta hãy cùng xem cả predictive routing và các phương pháp check output như các chuỗi lệnh và subagent, để bạn có thể hình dung được những gì mình có thể tự kiểm tra.