Agentic AI: Làm thế nào để tiết kiệm token

Agent của bạn có thể được trang bị hệ thống prompt 500 token và hai công cụ, nhưng những con số đó thường tăng lên rất nhanh.
Để minh họa, hệ thống prompt Claude bị rò rỉ có khoảng 24.000 token, và người dùng OpenClaw đã báo cáo hơn 150.000 token input được gửi đến Gemini 3.1 Pro để nhận được 29 token output trong lượt đầu tiên.
Một hệ thống tự động gửi email chưa được tối ưu hóa, chạy với tốc độ 100 tin nhắn mỗi ngày và sử dụng 166.000 token input, có thể tiêu tốn khoảng 996 đô mỗi tháng trên Gemini 3.1 Pro và khoảng 2.490 đô trên Claude Opus 4.6.
Có những thủ thuật để giảm chi phí xuống còn khoảng 50 đô và 100 đô mỗi tháng.
Vì vậy, bài viết muốn trình bày một vài nguyên tắc thiết kế mà mọi người thường cân nhắc khi xây dựng hệ thống.
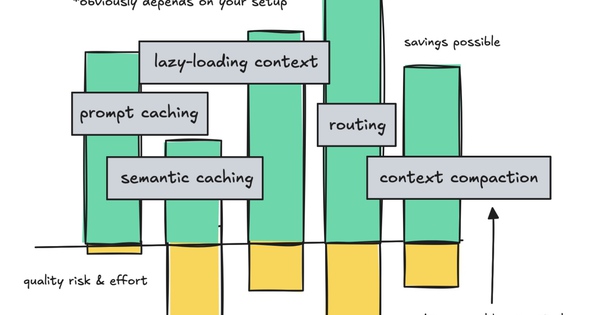
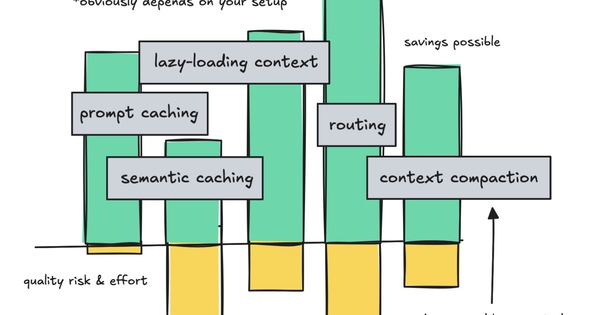
Chúng ta sẽ cùng tìm hiểu cách thức hoạt động của prompt caching và lý do tại sao nó mang lại hiệu quả nhanh chóng, các công cụ semantic caching, lazy-loading và MCP, routing và phân cấp, ủy quyền cho các subagent, và một chút về những lợi ích tiết kiệm được khi giữ cho context được clean.
Và chúng ta cũng cần thẳng thắn rằng mọi sự tiết kiệm đều đi kèm với những đánh đổi.
Bốn nguyên tắc thiết kế cần ghi nhớ
Trong bài viết này, chúng ta sẽ xem xét bốn phần khác nhau với bốn máy tính tương tác khác nhau.

Đầu tiên, chúng ta sẽ xem xét cách tái sử dụng token khi có thể, tập trung vào prompt caching và semantic caching. Sau đó, chúng ta sẽ xem xét cách giảm thiểu các token ổn định và luôn được thêm vào như định nghĩa bộ nhớ và công cụ.
Phần này cũng sẽ đề cập đến cách định tuyến đến các mô hình nhỏ hơn, hoặc leo thang lên mô hình lớn hơn, xem xét các rủi ro về chất lượng và lợi ích tiết kiệm được.
Phần cuối cùng sẽ nói về việc giữ cho context clean vì lý do hiệu suất và kinh tế, đồng thời đề cập ngắn gọn đến việc nén dữ liệu.
Tái sử dụng token khi có thể
Chi phí LLM không chỉ đến từ việc gọi mô hình quá thường xuyên. Nó còn đến từ việc liên tục phải trả tiền để xử lý cùng một token nhiều lần.
Vì vậy, trong phần này, chúng ta sẽ đề cập đến K/V caching, cơ chế hoạt động ngầm đằng sau prompt caching và semantic caching, hai khái niệm rất khác nhau. Chúng ta sẽ xem xét chúng là gì, chúng làm gì và bạn có thể tiết kiệm được bao nhiêu.
Prompt caching là một giải pháp nhanh chóng cho các system prompt dài, trong khi semantic caching tốn nhiều công sức hơn và đi kèm với rủi ro cao hơn.
K/V caching & prefix caching
Trước khi một mô hình có thể tạo ra bất cứ thứ gì, nó trước tiên phải xử lý prompt. Phần này thường tiêu tốn tài nguyên tính toán, tương đương với độ trễ và chi phí. Vì vậy, để hiệu quả, chúng ta không nên liên tục xử lý lại cùng một nội dung.
Khi bạn sử dụng một mô hình ngôn ngữ lớn LLM, prompt trước tiên được mã hóa thành token, sau đó các token đó được chuyển thành vector, và sau đó bên trong mỗi attention layer, các vector đó được chiếu thành tensor K/V.

Công cụ suy luận lưu trữ các tensor K/V trong quá trình tạo, nếu không thì phép toán sẽ không hoạt động với tốc độ hợp lý, có thể là như vậy.
Nhưng thay vì loại bỏ caching khi phản hồi kết thúc, chúng ta có thể lưu trữ nó.
Lần tới khi có yêu cầu đến, chúng ta sẽ kiểm tra xem phần đó của prompt có khớp với thứ gì đó mà chúng ta đã có tensor hay không. Nếu có, chúng ta sẽ tải các tensor đó và bỏ qua việc xử lý lại.

Để hiểu rõ hơn tầm quan trọng về mặt kinh tế của điều này: giả sử mất một giây để xử lý 2.000 token, và bạn có một system prompt gồm 10.000 token.
Điều đó có nghĩa là tiết kiệm được 5 giây cho mỗi lần gọi LLM, chỉ bằng cách không tính toán lại cùng một start của prompt thông qua mô hình lặp đi lặp lại (mặc dù prefill throughput trước thay đổi rất nhiều tùy thuộc vào cấu hình).
Điều quan trọng cần lưu ý là chúng ta phải khớp chính xác input với K/V cache đã lưu trữ.
Nếu các token thay đổi, chúng ta không còn tensor K/V được tính toán trước cho phần chính xác đó của prompt nữa, vì vậy nó phải được xử lý lại. Đây là nơi mọi người thường gặp khó khăn: một khoảng trắng mới được thêm vào, một định nghĩa công cụ được sắp xếp lại, một dấu thời gian ở sai vị trí.
Vì vậy, việc lưu cache có giá trị thực sự về mặt tăng tốc request, và từ đó làm cho request rẻ hơn.
Lưu ý rằng việc lưu trữ các tensor này không phải là miễn phí. Việc lưu trữ cặp key/value (K/V) sẽ chiếm bộ nhớ ở phía máy chủ, đó là lý do tại sao nhiều nhà cung cấp có TTL window khoảng 5-10 phút.
Bây giờ, chúng ta không cần phải tự xây dựng điều này, đây chỉ là để suy nghĩ về cơ chế hoạt động. Có những framework hỗ trợ việc này, và các nhà cung cấp API cũng có các quy tắc lưu trữ prompt riêng, và chúng ta sẽ xem xét cả hai.
Prefix caching cho self-hosted inference
Nếu bạn đang lưu trữ một open source model, lý tưởng nhất là bạn nên sử dụng một LLM serving framework như vLLM. Mặc dù có các framework khác có thể hỗ trợ caching layer, vLLM có một tính năng bổ sung mà chúng ta có thể xem xét.
Caching layer trong vLLM hoạt động nhờ chia nhỏ prompt thành các block, hashing mỗi block dựa trên các token của nó (cộng với các token trước đó), và lưu trữ các tensor K/V tương ứng với các giá trị hashing đó.
Giống như hầu hết các thiết lập, phần tĩnh cần được lưu vào bộ nhớ đệm nên được đặt ở phần start của prompt.

Để bật caching trong vLLM, hãy sử dụng flag `--enable-prefix-caching`.
Để điều chỉnh block size, bạn có thể sử dụng flag `--block-size`. Block size tương đương với số token trên mỗi khối. Nếu block size là 16, thì bạn có 16 token trên mỗi block trước khi nó bị cắt và bắt đầu một block khác.
Bạn cũng có thể sử dụng flag `--kv-cache-memory-bytes` để thiết lập rõ ràng KV cache size cho mỗi GPU. Bạn cấp càng nhiều memory, nó càng có thể giữ các block được lưu trong cache lâu hơn. Nhưng nếu bạn có nhiều long request khác nhau cùng một lúc, memory sẽ đầy nhanh hơn, vì vậy các block cũ sẽ bị xóa nhanh hơn.
Còn nhiều giải pháp khác nữa, nhưng bạn hiểu ý rồi đấy. Cơ chế hoạt động cũng tương tự như phần trước.
Bạn cũng có thể tham khảo SGLang và RadixAttention để lưu trữ prefix caching, cũng như LMCache, có thể tích hợp vào các máy chủ.
Tuy nhiên, hầu hết mọi người sử dụng các API provider và họ có chính sách riêng về cách sử dụng prompt caching.
Prompt caching via API providers
Khi sử dụng các API provider, bạn cần đảm bảo cấu trúc prompt sao cho chúng được lưu vào bộ nhớ cache. Có một số điều bạn cần tuân theo để thực hiện điều này một cách chính xác.
Sau đây là ví dụ từ OpenAI
Đối với OpenAI, họ nêu rõ, để cache một phần của prompt, họ yêu cầu phải khớp chính xác prefix. Tức là, cùng một static input ở đầu prompt.
Điều này có nghĩa là bạn luôn đặt các hướng dẫn, ví dụ và tool ổn định lên trước, và nội dung thay đổi ở sau.

Bạn cũng có thể truyền thêm tham số prompt-cache-key, giúp nhóm các request tương tự lại với nhau và cải thiện tỷ lệ cache hit.
Ngoài ra còn có một số chi tiết kỹ thuật đáng chú ý. Caching sẽ tự động được bật cho các prompt có độ dài từ 1.024 token trở lên, nhưng hệ thống sử dụng 256 token đầu tiên để route request quay lại đúng cache tương ứng. Vì vậy, static part của prompt cần dài hơn 256 token.
Với Anthropic, bạn phải chủ động bật caching thông qua tham số cache-control.
Cũng cần lưu ý rằng thông thường việc loại bỏ tài khoản (TTL) xảy ra sau khoảng 5-10 phút không hoạt động, nhưng có thể kéo dài hơn. Điều này cũng tương tự với Anthropic, nhưng bạn có thể kéo dài thời gian lên đến một giờ (nhưng chi phí sẽ cao hơn gấp đôi).
Trước đó chúng ta đã nói về thời gian bạn tiết kiệm được, và nếu bạn tự host điều này cũng giúp tiết kiệm chi phí. Với các API provider, khoản tiết kiệm thể hiện ở việc giảm giá token input được lưu cache.
Với OpenAI, cache input có thể giúp giảm chi phí tới 90% so với base input.

Anthropic cũng cung cấp mức discount tương tự cho cache input, nhưng bạn cũng phải trả phí để store cache. Vì vậy, nếu bạn không sử dụng đúng cách, Anthropic sẽ đắt hơn.
Tuy nhiên, nhìn chung, nếu 90% cache input của bạn là tĩnh, nếu sử dụng bộ nhớ cache đúng cách, chi phí OpenAI sẽ thấp hơn.