etcd hoạt động như thế nào trong Kubernetes?
Có lẽ bạn đã từng nghe đến từ "etcd" khi nói về Kubernetes. Có thể bạn đã thấy nó được liệt kê như một thành phần của control plane. Hoặc có thể một cụm vô tình bị lỗi và ai đó chỉ vào etcd và nói "đó là vấn đề". Nhưng nếu bạn chưa bao giờ thực sự hiểu nó là gì hoặc nó hoạt động như thế nào… thì bạn không phải là người duy nhất.
Điều quan trọng là, etcd là thành phần quan trọng nhất trong toàn bộ cụm Kubernetes của bạn. Không phải máy chủ API. Không phải scheduler. Không phải controller manager. Mà là etcd. Bởi vì nếu không có nó, không một thành phần nào khác có thể hoạt động được. Nó là nguồn cung cấp thông tin duy nhất cho mọi thứ trong cụm của bạn — mọi Pod, mọi Deployment, mọi Secret, mọi ConfigMap… tất cả đều nằm trong etcd.
Vậy hãy cùng phân tích nó từ đầu. Đến cuối bài viết này, bạn sẽ hiểu etcd thực chất là gì, cách nó lưu trữ và bảo vệ dữ liệu của bạn bằng thuật toán consensus thông minh, cách nó giao tiếp với phần còn lại của Kubernetes, và – điều quan trọng nhất – tại sao bạn nhất định phải sao lưu nó. Cùng bắt đầu nào.
etcd là gì?
Trước khi đi sâu vào cách etcd hoạt động trong Kubernetes, hãy cùng hiểu etcd là gì.
etcd là một kho lưu trữ cặp key-value phân tán, mã nguồn mở. Hãy tưởng tượng nó giống như một cuốn từ điển có độ tin cậy cao - bạn lưu một giá trị với một key, và có thể lấy lại giá trị đó bằng chính key đó. Khái niệm thì đơn giản, nhưng điều “kỳ diệu” nằm ở việc khi cuốn “từ điển” này được phân tán trên nhiều máy chủ khác nhau, nó vẫn đảm bảo tất cả luôn đồng bộ hoàn hảo với nhau — ngay cả khi có node bị lỗi hoặc mạng gặp sự cố.
Kubernetes đã sử dụng etcd làm kho lưu trữ dữ liệu từ những ngày đầu tiên. Mỗi khi bạn tạo một tài nguyên — ví dụ như một Deployment với 3 bản sao — thông số kỹ thuật đó sẽ được ghi vào etcd. Mỗi khi một Pod được lên lịch chạy trên một node, trạng thái đó cũng được ghi vào etcd. Mỗi khi bạn tạo một Secret, mỗi khi bạn cập nhật một ConfigMap, mỗi khi một node tham gia vào cụm… etcd sẽ ghi nhớ tất cả những điều đó.
Cùng xem nếu bạn thử truy cập vào pod etcd và dùng lệnh etcdctl, bạn sẽ thấy các key trông như thế này:
ETCDCTL_API=3 etcdctl get / — prefix — keys-only
Và đây là output:
/registry/deployments/default/my-app
/registry/pods/kube-system/coredns-abc123
/registry/secrets/default/my-secret
/registry/services/specs/default/my-service
/registry/configmaps/default/app-config
Mỗi đối tượng trong Kubernetes đều có một key riêng dưới đường dẫn /registry. Giá trị được lưu tại mỗi key chính là toàn bộ cấu hình YAML/JSON của đối tượng đó, được tuần tự hóa (serialize) sang dạng nhị phân bằng Protocol Buffers.
Vì vậy, khi bạn chạy lệnh kubectl get pod my-pod -o yaml, Kubernetes thực chất đang đọc dữ liệu từ chính kho lưu trữ này (tức etcd) và giải tuần tự (deserialize) lại để hiển thị cho bạn.
Cách etcd giữ đồng bộ
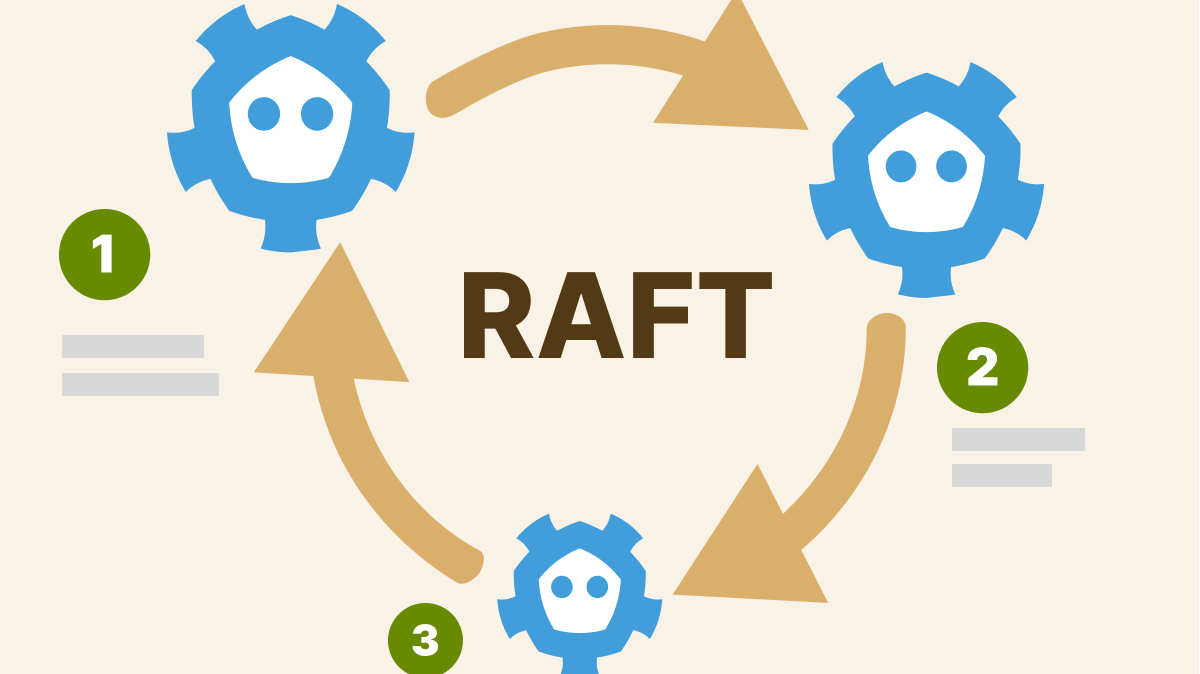
Giờ mới là phần thú vị. Bạn không thể chỉ chạy một instance etcd duy nhất trong môi trường production rồi coi như xong. Nếu node đó bị crash thì toàn bộ trạng thái của cluster sẽ biến mất. Vì vậy, etcd luôn chạy theo dạng cluster — thường là 3 hoặc 5 node — và sử dụng một thuật toán đồng thuận gọi là Raft consensus algorithm để giữ tất cả các node đồng bộ hoàn hảo.
Hãy hình dung Raft như một nền dân chủ với các quy tắc rất nghiêm ngặt. Mỗi cluster etcd sẽ bầu ra một node làm Leader (lãnh đạo). Các node còn lại gọi là Followers (người theo). Leader là node chịu trách nhiệm chính — mọi yêu cầu ghi (write) đều phải đi qua nó. Các Followers chỉ việc sao chép (replicate) lại những gì Leader quyết định, và luôn sẵn sàng thay thế nếu Leader gặp sự cố.
Luồng ghi dữ liệu trong Raft consensus algorithm
Dưới đây là cách một thao tác ghi (write) thực sự diễn ra trong etcd:
Một yêu cầu ghi đến Leader (ví dụ: “tạo một Deployment mới”)
Leader ghi (append) yêu cầu này vào log của chính nó và gửi tới tất cả Followers
Các Followers ghi vào log của chúng và gửi lại xác nhận (acknowledgment)
Khi đa số node (quorum) đã xác nhận, Leader sẽ commit (chốt) bản ghi này
Leader thông báo cho tất cả Followers rằng bản ghi đã được commit và chúng cũng áp dụng thay đổi
Cuối cùng, phản hồi được gửi về client — thành công!
Điểm quan trọng ở đây là đa số (majority).
Cluster 3 node cần 2 node đồng ý
Cluster 5 node cần 3 node đồng ý
Đây là lý do vì sao các cluster etcd luôn dùng số lượng node lẻ — không phải vì số chẵn “xui”, mà vì số lẻ luôn đảm bảo có đa số rõ ràng khi xảy ra phân tách (split).
Ví dụ:
Cluster 4 node cũng chỉ chịu lỗi được 1 node, giống như cluster 3 node
Nhưng lại phức tạp hơn mà không tăng thêm khả năng chịu lỗi
Vì vậy, cluster có số node lẻ sẽ mang lại khả năng chịu lỗi tốt nhất với số lượng node ít nhất.
Khi Leader gặp sự cố thì điều gì xảy ra?
Đây là lúc cơ chế heartbeat của Raft consensus algorithm phát huy tác dụng. Leader liên tục gửi “nhịp tim” (heartbeat) đến các Followers để báo rằng “tôi vẫn còn hoạt động”.
Nếu một Follower không nhận được heartbeat trong một khoảng thời gian nhất định (gọi là election timeout, thường khoảng 150–300ms), nó sẽ giả định rằng Leader đã “chết”, tự nâng cấp thành Candidate và bắt đầu một cuộc bầu cử:
- Nó tự bầu cho chính mình
- Gửi yêu cầu đến các node khác để xin bầu
- Candidate nào nhận được đa số bầu trước sẽ trở thành Leader mới
- Cơ chế này đơn giản, nhanh và hoàn toàn tự động.
Toàn bộ quá trình này diễn ra mà không cần bất kỳ sự can thiệp nào từ con người. Cluster của bạn có thể đang trong quá trình lên lịch một Pod trong Kubernetes khi Leader của etcd bị crash — và chỉ trong vài mili-giây, một Leader mới sẽ được bầu và hệ thống tiếp tục hoạt động bình thường.
Đây chính là đỉnh cao của kỹ thuật hệ thống phân tán.
etcd giao tiếp với Kubernetes như thế nào?
Có một lựa chọn thiết kế rất quan trọng trong Kubernetes mà nhiều người dễ bỏ qua: chỉ có API server mới được nói chuyện trực tiếp với etcd — không phải scheduler, không phải controller manager, cũng không phải kubelet, mà chỉ duy nhất kube-apiserver.
Tất cả các thành phần trong control plane của Kubernetes đều phải đi qua API server để đọc hoặc ghi trạng thái cluster. API server đóng vai trò như “người gác cổng”:
- Xử lý xác thực (authentication)
- Phân quyền (authorization – RBAC)
- Admission webhooks
- Kiểm tra hợp lệ (validation)
Chỉ sau khi vượt qua tất cả các bước này, dữ liệu mới được lưu vào etcd hoặc được trả về từ đó.
Thiết kế này giúp etcd không cần quan tâm ai đang yêu cầu hay họ có quyền hay không — đó là trách nhiệm của API server. etcd chỉ đơn giản là lưu trữ và truy xuất dữ liệu theo yêu cầu.
Kết nối kỹ thuật
API server kết nối tới etcd qua gRPC trên cổng 2379 (client traffic)
Các node etcd giao tiếp với nhau qua cổng 2380 (peer traffic)
Toàn bộ kết nối được bảo mật bằng mutual TLS (mTLS)
Điều đó có nghĩa là certificate xuất hiện ở khắp nơi — và bạn sẽ cần chúng khi chạy các lệnh như etcdctl một cách thủ công.
“Siêu năng lực” Watch của etcd
Một điểm cực kỳ mạnh mẽ mà etcd mang lại cho Kubernetes là Watch API.
Cách hoạt động của control loop trong Kubernetes về cơ bản là:
“Trạng thái mong muốn là gì? Trạng thái thực tế là gì? Làm sao để hai cái khớp nhau?”
Nhưng câu hỏi quan trọng là: làm sao các thành phần biết khi nào có thay đổi mà không phải liên tục polling (hỏi lại)?
Câu trả lời là: cơ chế watch của etcd.
Các controller và scheduler có thể “watch” (theo dõi) các key hoặc prefix cụ thể trong etcd
Ngay khi có thay đổi, chúng sẽ được thông báo tức thì
Ví dụ:
Bạn chạy kubectl apply để tạo một Deployment mới
API server ghi dữ liệu đó vào etcd
etcd ngay lập tức gửi một sự kiện (watch event) đến controller manager
Deployment controller “thức dậy”, đọc cấu hình mới và bắt đầu tạo ReplicaSet và Pod
Không cần polling. Chỉ cần event-driven.
Đây chính là “điều thú vị” đằng sau reconciliation loop — cơ chế giúp Kubernetes luôn tự động đưa hệ thống về đúng trạng thái mong muốn một cách hiệu quả và gần như theo thời gian thực.
Những gì thực sự được lưu trong etcd (và những gì không)
Trong etcd:
Tất cả các đối tượng API của Kubernetes:
Pod, Deployment, Service, ConfigMap, Secret, Namespace, RBAC roles, ServiceAccount, PersistentVolume, CustomResourceDefinition — nói chung là mọi thứ bạn tạo qua kubectl hoặc API
Cấu hình và metadata của cluster
Các lock chọn Leader (leader election locks) được dùng bởi các thành phần như scheduler và controller manager
Và etcd cũng được dùng như một cơ chế distributed locking
Không nằm trong etcd:
- Log của container (được lưu trên node)
- Metrics (được gửi đến hệ thống monitoring)
- Image container
- Dữ liệu mà ứng dụng của bạn ghi xuống disk
Vì sao điều này quan trọng?
etcd không phải là một cơ sở dữ liệu đa năng cho ứng dụng. Nó được thiết kế chuyên biệt để lưu trữ một lượng nhỏ dữ liệu cấu hình, nhưng yêu cầu tính nhất quán rất cao.
Khuyến nghị:
- Kích thước database etcd nên giữ dưới 8 GB
- Bạn có thể kiểm tra kích thước hiện tại bằng các công cụ như etcdctl
- Nếu để etcd phình to quá mức, hiệu năng của toàn bộ cluster Kubernetes có thể bị ảnh hưởng nghiêm trọng.