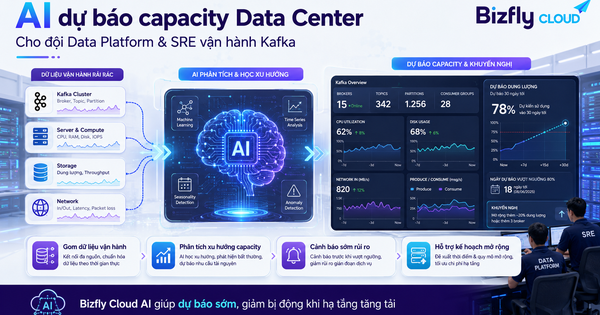
AI giám sát Kubernetes Cluster

Một doanh nghiệp công nghệ triển khai nhiều dịch vụ trên Kubernetes gặp tình trạng đội DevOps phải kiểm tra log, metric và alert thủ công mỗi khi hệ thống có dấu hiệu bất thường. Bizfly Cloud AI được đưa vào bài toán giám sát Kubernetes Cluster để tổng hợp dữ liệu vận hành, phân tích rủi ro và gợi ý hướng xử lý theo ngữ cảnh thực tế của từng workload.
Bối cảnh khách hàng và áp lực cần thay đổi
Khách hàng trong case study mô phỏng này là một công ty công nghệ B2B đang vận hành nhiều ứng dụng nội bộ và dịch vụ khách hàng trên Kubernetes. Hệ thống có nhiều namespace, nhiều nhóm phát triển cùng triển khai workload, lịch release diễn ra hằng tuần và có một số dịch vụ cần duy trì tính sẵn sàng cao. Đội IT gồm Head of IT, DevOps và SRE phải theo dõi tình trạng cluster gần như liên tục, nhất là sau mỗi đợt deploy hoặc khi traffic tăng bất thường.
Vấn đề không nằm ở việc doanh nghiệp thiếu công cụ giám sát. Thực ra họ đã có metric, log, alert, dashboard và ticket sự cố, nhưng dữ liệu bị tách thành nhiều lớp khác nhau. Một cảnh báo CPU tăng có thể nằm ở monitoring, log lỗi lại nằm ở hệ thống logging, còn lịch deploy thì ở CI/CD. Khi sự cố xảy ra, DevOps phải tự ghép từng mảnh dữ liệu để hiểu chuyện gì đang diễn ra trong cluster.
Bài toán lớn khách hàng cần giải quyết
Kubernetes giúp doanh nghiệp mở rộng ứng dụng linh hoạt hơn, nhưng khi số lượng service tăng lên, bài toán giám sát cũng phức tạp hơn rất nhiều. Một Pod restart không chỉ là một cảnh báo kỹ thuật đơn lẻ, mà có thể liên quan đến cấu hình resource, image mới, dependency bên ngoài hoặc thay đổi network policy. Đội DevOps cần một cách nhìn theo ngữ cảnh, không chỉ nhìn từng biểu đồ riêng lẻ. Nếu vẫn xử lý bằng cách cũ, thời gian phát hiện và khoanh vùng nguyên nhân sẽ phụ thuộc quá nhiều vào kinh nghiệm cá nhân của từng kỹ sư.
Các bài toán chính được xác định trong giai đoạn khảo sát gồm:
Cảnh báo Kubernetes rời rạc, khó xác định mức ưu tiên: Alert từ CPU, memory, Pod restart, node pressure và ingress error xuất hiện ở nhiều kênh khác nhau. DevOps mất thời gian lọc cảnh báo nhiễu, trong khi cảnh báo quan trọng có thể bị chìm giữa nhiều thông báo lặp lại.
Dữ liệu vận hành phân tán giữa nhiều hệ thống: Metric nằm ở monitoring, log nằm ở logging platform, manifest nằm trong Git, lịch deploy nằm ở CI/CD và ticket nằm ở hệ thống quản lý sự cố. Khi cần điều tra, SRE phải mở nhiều màn hình để ghép mối liên hệ giữa thời điểm deploy, thay đổi cấu hình và lỗi runtime.
Khó phát hiện sớm rủi ro trước khi thành sự cố: Một số dấu hiệu như memory tăng chậm, Pod restart thưa, request timeout theo cụm hoặc số lượng pending Pod tăng dần thường không đủ nghiêm trọng để kích hoạt incident ngay. Nhưng nếu không được gom lại và phân tích theo chuỗi, các dấu hiệu này có thể dẫn tới downtime hoặc degraded performance.
Tri thức xử lý sự cố phụ thuộc vào một số kỹ sư giàu kinh nghiệm: Nhiều nguyên nhân lỗi từng xảy ra trước đây đã được xử lý trong ticket hoặc trao đổi nội bộ, nhưng chưa được chuẩn hóa thành playbook dễ tra cứu. Khi kỹ sư mới trực ca, họ vẫn phải hỏi lại người cũ hoặc dò từng log để xử lý.
Báo cáo tình trạng cluster chưa đủ rõ cho cấp quản lý kỹ thuật: CTO hoặc Head of IT không cần đọc từng log, nhưng cần biết cluster nào đang có rủi ro, workload nào cần tối ưu và khu vực nào có khả năng ảnh hưởng đến SLA. Dashboard hiện tại có số liệu, nhưng thiếu phần diễn giải và ưu tiên hành động.
Những bài toán này có liên quan chặt với nhau vì đều xuất phát từ cùng một điểm nghẽn: Dữ liệu vận hành Kubernetes có nhiều, nhưng chưa được tổ chức thành luồng phân tích có ngữ cảnh. Khi alert, log, event và lịch deploy không được đặt cạnh nhau, đội vận hành chỉ nhìn thấy triệu chứng thay vì nhìn thấy chuỗi nguyên nhân. Vì vậy, giải pháp cần xử lý bài toán như một hệ thống giám sát thông minh, thay vì thêm một dashboard riêng lẻ.
Cách Bizfly Cloud AI được triển khai trong case study này
Trong case study này, Bizfly Cloud AI được triển khai như một lớp AI Agent hỗ trợ giám sát và phân tích vận hành Kubernetes Cluster. Lớp này không thay thế các công cụ monitoring sẵn có, mà kết nối dữ liệu từ nhiều nguồn để tạo ra bức tranh vận hành dễ hiểu hơn. Dữ liệu đầu vào gồm Kubernetes events, Pod logs, container metrics, node metrics, deployment history, manifest thay đổi gần nhất, ticket sự cố cũ và playbook xử lý nội bộ nếu có.
Trước khi đưa vào AI workflow, dữ liệu được chuẩn hóa theo các thực thể chính của Kubernetes như cluster, node, namespace, deployment, service, ingress, Pod và container. Các alert được gắn thêm thông tin về thời điểm, mức độ ảnh hưởng, owner team và workload liên quan. Với log, hệ thống không đưa toàn bộ dữ liệu thô vào phân tích một cách tràn lan, mà lọc theo khoảng thời gian, service, severity và pattern lỗi. Khi triển khai với dữ liệu phân tán, trong thực tế tôi thấy vấn đề không nằm ở AI trước mà nằm ở cách chuẩn hóa nguồn dữ liệu để AI có đủ ngữ cảnh và không suy luận lệch.
AI Agent được thiết kế theo luồng xử lý gồm bốn bước. Đầu tiên, hệ thống gom tín hiệu từ metric, event và log theo cùng một mốc thời gian. Tiếp theo, AI phân loại nhóm vấn đề như resource saturation, scheduling issue, image pull error, crash loop, network timeout, autoscaling bất thường hoặc lỗi sau deploy. Sau đó, AI đối chiếu với lịch thay đổi gần nhất và ticket cũ để đưa ra giả thuyết nguyên nhân. Cuối cùng, hệ thống gợi ý hướng kiểm tra hoặc bước xử lý phù hợp với quyền của từng nhóm người dùng.
Đầu ra của Bizfly Cloud AI không chỉ là một cảnh báo mới. Đội DevOps nhận được bản tóm tắt tình trạng cluster theo ngôn ngữ dễ hiểu, danh sách workload có rủi ro, nguyên nhân khả nghi, mức độ ưu tiên và khuyến nghị hành động tiếp theo. SRE có thể dùng kết quả này để rút ngắn thời gian điều tra, còn Head of IT hoặc CTO có thể xem báo cáo tổng hợp theo tuần để biết khu vực nào cần tối ưu tài nguyên, chuẩn hóa cấu hình hoặc bổ sung playbook vận hành.
So sánh hiệu quả trước và sau triển khai
Trước khi triển khai, đội DevOps không thiếu dữ liệu nhưng thiếu một luồng phân tích chung để kết nối các tín hiệu. Sau khi Bizfly Cloud AI được đưa vào vận hành thử nghiệm, thay đổi lớn nhất không phải là “có thêm cảnh báo”, mà là cảnh báo được đặt vào đúng ngữ cảnh. Người trực ca có thể bắt đầu điều tra từ một bản tóm tắt có thứ tự ưu tiên, thay vì mở nhiều dashboard và tự suy luận từ đầu.
Tiêu chí | Trước khi triển khai | Sau khi triển khai Bizfly Cloud AI | Giá trị mang lại |
Phân loại cảnh báo Kubernetes | Alert được gửi rời rạc theo từng metric hoặc từng rule. DevOps phải tự đánh giá cảnh báo nào cần xử lý trước. | AI gom alert theo workload, namespace, thời điểm và mức độ ảnh hưởng để đề xuất thứ tự ưu tiên. | Giảm nhiễu cảnh báo, giúp ca trực tập trung vào vấn đề có rủi ro cao hơn. |
Điều tra lỗi Pod và workload | Kỹ sư phải mở log, event, manifest và lịch deploy ở nhiều nơi để tìm nguyên nhân. | AI tổng hợp log liên quan, event gần nhất, thay đổi cấu hình và lỗi tương tự trong quá khứ. | Rút ngắn bước khoanh vùng nguyên nhân và giảm phụ thuộc vào kinh nghiệm cá nhân. |
Theo dõi rủi ro cluster | Các dấu hiệu nhỏ như memory tăng chậm hoặc Pod restart rải rác dễ bị bỏ qua. | AI nhận diện chuỗi tín hiệu bất thường theo thời gian và gợi ý workload cần kiểm tra sớm. | Hỗ trợ phát hiện sớm rủi ro trước khi ảnh hưởng tới người dùng cuối. |
Báo cáo cho CTO/Head of IT | Báo cáo chủ yếu dựa trên biểu đồ và ghi chú thủ công từ đội vận hành. | AI tạo tóm tắt tình trạng cluster, nhóm vấn đề nổi bật và khuyến nghị tối ưu theo tuần. | Giúp quản lý kỹ thuật nắm được rủi ro vận hành mà không cần đọc toàn bộ log kỹ thuật. |
Chuẩn hóa tri thức xử lý sự cố | Playbook nằm rải rác trong ticket, tài liệu nội bộ hoặc kinh nghiệm của từng kỹ sư. | AI liên kết sự cố mới với ticket cũ và đề xuất bước xử lý đã từng hiệu quả. | Tăng khả năng tái sử dụng tri thức và hỗ trợ kỹ sư mới trong ca trực. |
Thay đổi quan trọng nhất trong case study này là đội vận hành chuyển từ phản ứng theo từng cảnh báo sang xử lý theo ngữ cảnh sự cố. Khi metric, log, event và lịch deploy được đặt vào cùng một luồng phân tích, DevOps có cơ sở rõ hơn để quyết định nên kiểm tra gì trước. Điều này cũng giúp cấp quản lý kỹ thuật nhìn Kubernetes Cluster như một hệ thống có trạng thái, có rủi ro và có xu hướng, thay vì một tập hợp dashboard kỹ thuật khó diễn giải.
Quy trình triển khai Bizfly Cloud AI
Quy trình triển khai được thiết kế theo hướng bắt đầu nhỏ, đo được kết quả và mở rộng dần theo mức độ sẵn sàng dữ liệu. Với Kubernetes, không nên đưa toàn bộ cluster và toàn bộ log vào AI ngay từ đầu vì dễ tạo nhiễu và khó kiểm soát quyền truy cập. Phạm vi POC phù hợp thường là một vài namespace, một nhóm workload quan trọng hoặc một nhóm sự cố lặp lại nhiều lần trong vận hành.
Khảo sát hiện trạng và xác định bài toán chính: Đội triển khai làm việc với CTO, Head of IT, DevOps và SRE để xác định các tình huống vận hành gây tốn thời gian nhất. Ở bước này, mục tiêu không phải là liệt kê mọi loại alert, mà là chọn nhóm vấn đề có ảnh hưởng rõ đến uptime, trải nghiệm khách hàng hoặc năng suất ca trực.
Thu thập, làm sạch và phân nhóm dữ liệu đầu vào: Dữ liệu được gom từ monitoring, logging, Kubernetes API, CI/CD, ticket và tài liệu vận hành hiện có. Sau đó, dữ liệu được phân nhóm theo cluster, namespace, service, deployment, thời điểm xảy ra lỗi và team phụ trách để AI có thể phân tích đúng ngữ cảnh.
Thiết kế AI Agent hoặc workflow theo từng use case con: Mỗi use case cần một luồng xử lý riêng, ví dụ phát hiện bất thường, phân tích lỗi Pod hoặc tạo báo cáo vận hành. AI Agent được giới hạn phạm vi hành động rõ ràng, ưu tiên tổng hợp, phân tích, gợi ý và tạo checklist kiểm tra thay vì tự động can thiệp vào hệ thống production.
Tích hợp với hệ thống hiện có như ticket, CI/CD, monitoring, logging và data warehouse: Bizfly Cloud AI được kết nối với các nguồn dữ liệu đang dùng để tránh tạo thêm một hệ thống vận hành tách biệt. Với dữ liệu nhạy cảm như log chứa thông tin người dùng hoặc token, quy trình cần có bước lọc, ẩn hoặc giới hạn quyền truy cập trước khi đưa vào phân tích.
Chạy thử POC với phạm vi nhỏ: POC có thể bắt đầu từ một nhóm service có tần suất deploy cao hoặc từng xảy ra nhiều sự cố. Trong giai đoạn này, đội DevOps đối chiếu kết quả AI gợi ý với cách điều tra thủ công để đánh giá độ hữu ích, độ nhiễu và khả năng áp dụng vào ca trực thật.
Đo lường, tinh chỉnh và mở rộng triển khai: Sau POC, doanh nghiệp tinh chỉnh rule phân loại, bổ sung playbook, điều chỉnh quyền truy cập và mở rộng sang nhiều namespace hoặc cluster hơn. Việc đo lường nên tập trung vào chất lượng vận hành như thời gian khoanh vùng nguyên nhân, mức độ giảm alert nhiễu và khả năng tái sử dụng tri thức xử lý sự cố.
Một điểm khó thường gặp là dữ liệu Kubernetes có nhiều tầng và thay đổi rất nhanh. Nếu chỉ lấy log mà bỏ qua deployment history, AI có thể nhìn thấy lỗi runtime nhưng không biết lỗi đó xuất hiện ngay sau một lần release. Cách xử lý tốt hơn là chuẩn hóa dữ liệu theo timeline sự kiện, trong đó alert, log, event và thay đổi cấu hình được gắn chung vào một bối cảnh điều tra.
Kết quả và giá trị doanh nghiệp nhận được
Sau khi triển khai, giá trị đầu tiên doanh nghiệp nhận thấy là đội DevOps giảm bớt thời gian xử lý các bước lặp lại trong điều tra sự cố. Thay vì phải mở từng nguồn dữ liệu, người trực ca có thể bắt đầu từ bản tóm tắt tình trạng workload, các tín hiệu bất thường và danh sách nguyên nhân khả nghi. Đây không phải là việc AI “sửa lỗi Kubernetes”, mà là AI giúp rút ngắn phần thu thập và liên kết dữ liệu vốn chiếm nhiều thời gian trong ca trực.
Giá trị thứ hai nằm ở khả năng chuẩn hóa tri thức vận hành. Những lỗi đã từng xảy ra, cách kiểm tra đã từng dùng và playbook đã từng hiệu quả được đưa vào luồng tham chiếu để hỗ trợ tình huống mới. Với đội SRE, điều này giúp giảm phụ thuộc vào một vài cá nhân có nhiều kinh nghiệm. Với Head of IT, đây là cơ sở để biến vận hành Kubernetes từ kinh nghiệm rời rạc thành quy trình có thể đào tạo, kiểm tra và cải tiến.
Ở cấp quản lý, báo cáo từ Bizfly Cloud AI giúp CTO nhìn rõ hơn các nhóm rủi ro trong cluster. Ví dụ workload nào thường xuyên thiếu resource, namespace nào phát sinh nhiều cảnh báo, nhóm deploy nào có tần suất lỗi cao hoặc khu vực nào cần tối ưu autoscaling. Khi dữ liệu kỹ thuật được chuyển thành thông tin có thể hành động, doanh nghiệp có thể mở rộng vận hành Kubernetes mà không cần tăng tương ứng số lượng nhân sự trực giám sát.
AI chưa làm được gì trong case study này
AI không tự chịu trách nhiệm cho các quyết định quan trọng trên Kubernetes Cluster. Những hành động như scale workload production, rollback release, thay đổi network policy, xóa Pod hàng loạt hoặc điều chỉnh quota vẫn cần con người kiểm tra và phê duyệt. Bizfly Cloud AI đóng vai trò hỗ trợ tổng hợp, phân tích, gợi ý và tự động hóa một phần quy trình điều tra, không thay thế toàn bộ đội DevOps/SRE.
AI cũng phụ thuộc vào chất lượng dữ liệu đầu vào. Nếu log thiếu ngữ cảnh, alert đặt tên không rõ, quyền truy cập bị thiếu hoặc ticket sự cố cũ không được ghi nhận đầy đủ, kết quả phân tích sẽ bị giới hạn. Các tình huống ngoại lệ, dữ liệu nhạy cảm và quyết định có tác động lớn đến SLA vẫn cần người có chuyên môn kiểm soát cuối cùng. Đây là ranh giới quan trọng khi đưa AI vào vận hành hạ tầng thật.
FAQ
1. Doanh nghiệp đã có monitoring rồi thì có cần AI giám sát Kubernetes Cluster không?
Có, nếu monitoring hiện tại mới dừng ở mức hiển thị metric và gửi alert rời rạc. Trong nhiều hệ thống Kubernetes, vấn đề không phải là thiếu cảnh báo mà là quá nhiều cảnh báo thiếu ngữ cảnh. AI giúp gom tín hiệu từ log, event, metric và lịch deploy để đội DevOps hiểu sự cố nhanh hơn. Bizfly Cloud AI phù hợp với bài toán này khi doanh nghiệp muốn biến dữ liệu giám sát thành luồng phân tích có thể hành động.
2. AI có thể tự động xử lý sự cố Kubernetes không?
AI có thể hỗ trợ đề xuất hướng xử lý, tạo checklist kiểm tra hoặc gợi ý playbook phù hợp với tình huống. Tuy nhiên, với môi trường production, các hành động can thiệp trực tiếp như rollback, scale hoặc thay đổi cấu hình vẫn nên có bước phê duyệt của con người. Cách triển khai an toàn là để AI hỗ trợ điều tra và khuyến nghị trước, sau đó mới xem xét tự động hóa một số thao tác ít rủi ro. Điều này giúp doanh nghiệp kiểm soát tốt hơn khi đưa AI vào vận hành hạ tầng.
3. Dữ liệu nào cần chuẩn bị trước khi triển khai use case này?
Doanh nghiệp nên chuẩn bị dữ liệu từ monitoring, logging, Kubernetes events, CI/CD, manifest thay đổi gần nhất, ticket sự cố và tài liệu playbook nếu có. Không nhất thiết mọi nguồn dữ liệu phải hoàn hảo ngay từ đầu, nhưng cần xác định rõ nguồn nào là dữ liệu chính cho từng use case. Với Bizfly Cloud, bước chuẩn hóa dữ liệu thường được xem là phần quan trọng trước khi thiết kế AI Agent. Dữ liệu càng có cấu trúc tốt, kết quả phân tích càng dễ kiểm chứng.
4. Giới hạn lớn nhất của AI trong giám sát Kubernetes là gì?
Giới hạn lớn nhất là AI không thể hiểu đúng nếu dữ liệu bị thiếu, nhiễu hoặc không có ngữ cảnh vận hành. Ví dụ một log lỗi có thể do code, do resource, do dependency hoặc do thay đổi cấu hình, nên AI cần thêm event, metric và lịch deploy để phân tích hợp lý. AI cũng không thay thế trách nhiệm của SRE trong các quyết định có rủi ro cao. Vì vậy, doanh nghiệp cần thiết kế cơ chế kiểm soát, phê duyệt và ghi nhận kết quả sau mỗi lần xử lý.
5. Use case này phù hợp với nhóm doanh nghiệp nào?
Use case này phù hợp với doanh nghiệp đang vận hành nhiều service trên Kubernetes, có đội DevOps/SRE trực ca và thường xuyên phải xử lý alert, log hoặc sự cố sau deploy. Nhóm CTO, Head of IT và trưởng nhóm vận hành cũng hưởng lợi vì có báo cáo tình trạng cluster dễ hiểu hơn. Nếu hệ thống còn nhỏ và ít thay đổi, doanh nghiệp có thể bắt đầu bằng một phạm vi POC hẹp. Khi số lượng workload tăng, giá trị của AI giám sát sẽ rõ hơn.
Kết bài
Bài toán giám sát Kubernetes Cluster không chỉ là thêm dashboard hay thêm cảnh báo. Vấn đề nằm ở việc đội vận hành cần hiểu nhanh mối liên hệ giữa metric, log, event, lịch deploy và tri thức xử lý sự cố đã có.
Trong case study mô phỏng này, Bizfly Cloud AI đóng vai trò biến dữ liệu vận hành phân tán thành một quy trình giám sát có ngữ cảnh, có ưu tiên và có thể đo lường. Khi được triển khai đúng phạm vi, AI giúp DevOps/SRE giảm tải bước điều tra lặp lại, đồng thời hỗ trợ CTO và Head of IT quản trị rủi ro Kubernetes theo cách chủ động hơn.