Ứng dụng AI giám sát hiệu năng Cloud Server cho đội IT, DevOps và SRE
Một doanh nghiệp công nghệ B2B vận hành website, API và hệ thống backend trên nhiều Cloud Server bắt đầu gặp tình trạng hiệu năng giảm âm thầm vào các khung giờ cao điểm. Hệ thống chưa sập, nhưng phản hồi chậm, log lỗi tăng và đội IT mất nhiều thời gian để xác định nguyên nhân. Bizfly Cloud AI được triển khai để hỗ trợ giám sát hiệu năng Cloud Server, phát hiện bất thường sớm hơn và giúp đội kỹ thuật xử lý sự cố có thứ tự hơn.
Bối cảnh triển khai

Bối cảnh triển khai AI giám sát hiệu năng Cloud Server
Khách hàng trong tình huống này là một doanh nghiệp có nền tảng số phục vụ nhiều nhóm người dùng cùng lúc, gồm khách hàng bên ngoài, đội kinh doanh nội bộ và bộ phận vận hành. Hệ thống chạy trên nhiều Cloud Server, chia thành các nhóm dịch vụ như website, API, cơ sở dữ liệu, backend xử lý tác vụ nền và một số dịch vụ tích hợp với hệ thống nội bộ. Đội chịu trách nhiệm vận hành gồm CTO, Head of IT, DevOps, System Admin và SRE.
Trước khi áp dụng AI, doanh nghiệp đã có công cụ theo dõi CPU, RAM, disk, network, trạng thái dịch vụ và log hệ thống. Vấn đề là dữ liệu nằm rải rác ở nhiều màn hình, nhiều cảnh báo xuất hiện cùng lúc nhưng không phải cảnh báo nào cũng cần xử lý ngay. Có những thời điểm CPU tăng, response time tăng, log lỗi xuất hiện nhiều hơn, nhưng nguyên nhân thật lại nằm ở một job nền hoặc một thay đổi cấu hình được đẩy lên trước đó.
Trong thực tế tôi thấy, bài toán giám sát hiệu năng Cloud Server không khó ở chỗ có dữ liệu hay không. Phần khó hơn là đội vận hành có đọc đúng tín hiệu từ dữ liệu đó hay không. Một chỉ số CPU tăng không tự nói được nguyên nhân, một dòng log lỗi cũng chưa đủ để kết luận sự cố. Vì vậy, doanh nghiệp cần một lớp hỗ trợ giúp gom dữ liệu, nhận diện mẫu bất thường và gợi ý hướng kiểm tra trước khi sự cố lan rộng.
Bài toán chi tiết cần giải quyết
Đội IT của khách hàng không chỉ muốn có thêm cảnh báo. Điều họ cần là giảm thời gian đọc dữ liệu vận hành, giảm cảnh báo nhiễu và phát hiện sớm dấu hiệu suy giảm hiệu năng trước khi người dùng cuối bị ảnh hưởng. Bài toán nằm giữa nhiều nhóm công việc: theo dõi tài nguyên, phân tích log, kiểm tra thay đổi cấu hình, đánh giá rủi ro tải tăng và điều phối xử lý sự cố. Nếu từng nhóm xử lý riêng lẻ, đội kỹ thuật rất dễ mất thời gian ở bước xác định nguyên nhân ban đầu.

Bài toán AI giám sát hiệu năng Cloud Server chi tiết cần giải quyết
Các vấn đề cụ thể gồm:
Cảnh báo hiệu năng chưa đủ ngữ cảnh: Nhiều hệ thống chỉ báo CPU, RAM hoặc disk tăng cao, nhưng không giải thích được chỉ số này có bất thường so với hành vi trước đó hay không. DevOps phải tự mở nhiều dashboard để đối chiếu. Khi đang có nhiều cảnh báo cùng lúc, việc xác định cảnh báo nào cần ưu tiên trở nên khó hơn.
Log hệ thống phân tán và khó đọc nhanh: Log nằm ở nhiều nguồn như application log, system log, web server log, database log hoặc log từ các tác vụ nền. Mỗi nguồn có định dạng khác nhau, tần suất sinh log khác nhau và mức độ quan trọng khác nhau. Khi có sự cố, System Admin thường phải tìm theo kinh nghiệm, dễ bỏ sót tín hiệu nhỏ xuất hiện trước thời điểm lỗi chính.
Khó phát hiện suy giảm hiệu năng âm thầm: Không phải sự cố nào cũng tạo ra downtime rõ ràng. Có trường hợp response time tăng dần, hàng đợi xử lý chậm hơn, disk I/O cao bất thường hoặc số lượng kết nối tăng mà chưa chạm ngưỡng cảnh báo cứng. Nếu chỉ dựa vào rule cố định, đội IT có thể phát hiện muộn.
Thiếu cơ chế gom nguyên nhân và gợi ý hướng xử lý: Khi một API chậm, nguyên nhân có thể đến từ server, database, network, cache, deployment mới hoặc traffic tăng đột biến. Cách làm cũ thường yêu cầu nhiều người cùng kiểm tra từng lớp. Việc này tốn thời gian, nhất là khi sự cố xảy ra ngoài giờ hành chính.
Báo cáo hiệu năng chưa phục vụ tốt cho quản lý IT: CTO hoặc Head of IT không cần đọc từng dòng log, nhưng cần biết hệ thống đang có rủi ro gì, nhóm server nào thường xuyên quá tải và đâu là khu vực cần nâng cấp hoặc điều chỉnh kiến trúc. Trước khi có AI hỗ trợ tổng hợp, các báo cáo này thường phải làm thủ công từ nhiều nguồn dữ liệu.
Các vấn đề trên liên quan chặt với nhau vì hiệu năng Cloud Server không phải một chỉ số đơn lẻ. Nó là kết quả của tài nguyên, cấu hình, ứng dụng, dữ liệu, traffic và hành vi người dùng. Vì vậy, Bizfly Cloud AI không được triển khai như một công cụ cảnh báo thay thế hệ thống giám sát cũ, mà như một lớp phân tích giúp đội IT đọc dữ liệu vận hành nhanh hơn và có thứ tự ưu tiên rõ hơn.
Bizfly Cloud AI xử lý bài toán này như thế nào?
Trong tình huống triển khai này, Bizfly Cloud AI được đặt vào lớp phân tích dữ liệu sau khi hệ thống đã có nguồn metric, log và thông tin vận hành cơ bản. Dữ liệu đầu vào gồm CPU, RAM, disk usage, disk I/O, network traffic, response time, request volume, error rate, trạng thái dịch vụ, log ứng dụng, log hệ thống và lịch sử thay đổi cấu hình nếu khách hàng có lưu lại. Với các hệ thống đã có ticket hoặc báo cáo sự cố cũ, dữ liệu xử lý sự cố trước đây cũng được đưa vào để AI nhận diện các mẫu lỗi lặp lại.

Bizfly Cloud AI xử lý bài toán AI giám sát hiệu năng Cloud Server như thế nào?
Trước khi AI xử lý, dữ liệu được chuẩn hóa theo nhóm server, nhóm dịch vụ, thời gian, mức độ nghiêm trọng và loại tín hiệu. Đây là bước rất quan trọng. Khi triển khai với dữ liệu phân tán, vấn đề không nằm ở AI trước mà nằm ở cách chuẩn hóa nguồn dữ liệu. Nếu tên server, tag dịch vụ, định dạng log hoặc mốc thời gian không thống nhất, AI rất khó liên kết đúng các dấu hiệu thuộc cùng một sự cố.
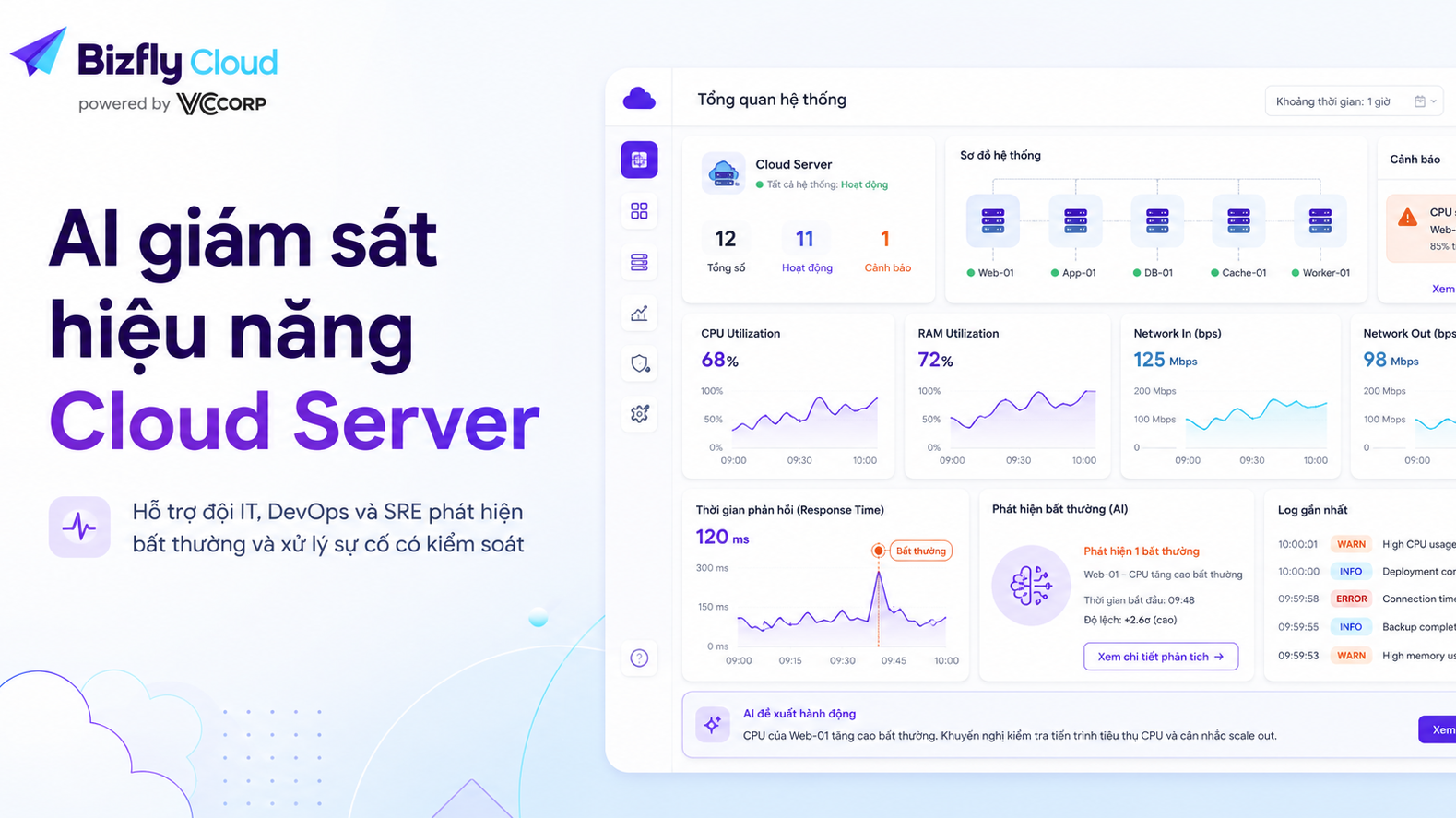
Luồng xử lý của Bizfly Cloud AI thường đi qua bốn nhóm việc. Đầu tiên, AI đọc dữ liệu giám sát theo thời gian và so sánh với hành vi vận hành trước đó để nhận diện điểm bất thường. Sau đó, AI gom các tín hiệu liên quan, ví dụ CPU tăng, response time tăng, error log xuất hiện nhiều hơn và một tác vụ nền chạy dài bất thường. Tiếp theo, hệ thống phân loại mức độ ưu tiên theo phạm vi ảnh hưởng, tần suất lặp lại và khả năng tác động đến người dùng. Cuối cùng, AI tạo bản tóm tắt sự kiện, gợi ý nguyên nhân cần kiểm tra trước và đề xuất bước xử lý phù hợp cho DevOps hoặc SRE.
Với dữ liệu nhạy cảm, quyền truy cập cần được kiểm soát theo vai trò. System Admin có thể xem chi tiết log kỹ thuật, trong khi CTO hoặc Head of IT chỉ cần xem báo cáo tổng hợp theo nhóm dịch vụ, mức độ rủi ro và xu hướng hiệu năng. Bizfly Cloud AI trong trường hợp này không tự ý mở toàn bộ dữ liệu cho mọi người dùng. Cách triển khai hợp lý là phân quyền đầu ra, lọc thông tin nhạy cảm trong log và ghi nhận lịch sử truy vấn để đội IT kiểm soát được ai đã xem dữ liệu nào.
Đầu ra của quá trình triển khai không chỉ là một cảnh báo. Đầu ra gồm bảng ưu tiên sự cố, mô tả bất thường bằng ngôn ngữ dễ hiểu, nhóm server bị ảnh hưởng, tín hiệu liên quan, khả năng nguyên nhân, hướng kiểm tra đề xuất và báo cáo xu hướng hiệu năng theo ngày hoặc theo giai đoạn. Người sử dụng kết quả này là DevOps, SRE, System Admin và quản lý IT. Với đội kỹ thuật, kết quả giúp rút ngắn bước đọc dữ liệu ban đầu. Với cấp quản lý, kết quả giúp nhìn thấy khu vực hạ tầng cần điều chỉnh trước khi phát sinh rủi ro lớn hơn.
So sánh hiệu quả trước và sau triển khai

So sánh hiệu quả trước và sau triển khai
Trước khi triển khai Bizfly Cloud AI, đội IT vẫn có dữ liệu vận hành nhưng phải tự ghép bức tranh từ nhiều công cụ. Sau khi triển khai, điểm thay đổi chính nằm ở khả năng gom tín hiệu, giải thích ngữ cảnh và đưa ra thứ tự ưu tiên xử lý. Bảng dưới đây tập trung vào các tiêu chí sát với bài toán giám sát hiệu năng Cloud Server, không so sánh theo kiểu chung chung về AI.
Tiêu chí | Trước khi triển khai | Sau khi triển khai Bizfly Cloud AI | Giá trị mang lại |
Phát hiện bất thường hiệu năng | Chủ yếu dựa vào ngưỡng cảnh báo cố định và kinh nghiệm của DevOps | AI so sánh tín hiệu hiện tại với hành vi vận hành trước đó để nhận diện bất thường | Phát hiện sớm các dấu hiệu suy giảm âm thầm |
Đọc log khi có sự cố | System Admin phải mở nhiều nguồn log và tự tìm mốc liên quan | AI gom log theo thời gian, dịch vụ và nhóm lỗi có liên quan | Rút ngắn bước xác định dấu hiệu ban đầu |
Ưu tiên cảnh báo | Nhiều cảnh báo xuất hiện cùng lúc, dễ gây nhiễu | Hệ thống phân loại theo mức ảnh hưởng, tần suất và phạm vi server | Giúp đội IT xử lý đúng việc trước |
Báo cáo cho quản lý IT | Báo cáo thường làm thủ công, phụ thuộc người tổng hợp | AI tạo bản tóm tắt xu hướng hiệu năng và nhóm rủi ro chính | CTO, CIO và Head of IT nắm tình hình nhanh hơn |
Điều phối xử lý sự cố | DevOps, SRE và System Admin phải trao đổi nhiều để thống nhất nguyên nhân | AI cung cấp bản tóm tắt chung để các bên cùng nhìn một ngữ cảnh | Giảm lệch thông tin giữa các nhóm kỹ thuật |
Thay đổi quan trọng nhất không phải là đội IT có thêm một màn hình cảnh báo mới. Điểm đáng giá nằm ở việc dữ liệu vận hành được chuyển từ dạng rời rạc sang dạng có ngữ cảnh. Khi DevOps nhận một cảnh báo, họ không chỉ thấy server đang cao tải, mà còn thấy các tín hiệu liên quan và hướng kiểm tra hợp lý. Điều này giúp các ca trực vận hành bớt phụ thuộc vào trí nhớ cá nhân của một vài kỹ sư nhiều kinh nghiệm. Nó cũng giúp quản lý IT có căn cứ tốt hơn khi quyết định mở rộng tài nguyên, điều chỉnh cấu hình hoặc rà soát lại kiến trúc ứng dụng.
Quy trình triển khai bài toán giám sát hiệu năng Cloud Server

Quy trình triển khai bài toán giám sát hiệu năng Cloud Server
Để triển khai AI giám sát hiệu năng Cloud Server, doanh nghiệp không nên bắt đầu bằng việc đưa toàn bộ log và metric vào AI ngay từ đầu. Cách làm hiệu quả hơn là chọn một nhóm server hoặc một dịch vụ có rủi ro rõ, sau đó mở rộng dần khi dữ liệu đã được chuẩn hóa. Với tình huống này, quy trình triển khai có thể đi theo sáu bước dưới đây:
Khảo sát hiện trạng và xác định bài toán chính
Đội Bizfly Cloud cùng khách hàng rà soát mô hình Cloud Server, nhóm dịch vụ đang chạy, công cụ giám sát hiện có và quy trình xử lý sự cố hiện tại. Ở bước này, cần xác định rõ vấn đề ưu tiên là cảnh báo nhiễu, phát hiện muộn, đọc log chậm hay báo cáo hiệu năng thiếu hệ thống. Nếu không chốt đúng bài toán, AI rất dễ được triển khai rộng nhưng không tạo ra thay đổi rõ trong vận hành.Thu thập, làm sạch và phân nhóm dữ liệu đầu vào
Dữ liệu được gom từ metric tài nguyên, log hệ thống, log ứng dụng, cảnh báo cũ, ticket vận hành và thông tin thay đổi cấu hình nếu có. Các nguồn này cần được chuẩn hóa theo thời gian, tên server, nhóm dịch vụ, môi trường chạy và mức độ nghiêm trọng. Với log có chứa dữ liệu nhạy cảm, doanh nghiệp cần lọc hoặc che bớt thông tin trước khi đưa vào luồng xử lý.Thiết kế luồng AI theo bài toán giám sát hiệu năng
Luồng AI được thiết kế để đọc dữ liệu theo từng nhóm tín hiệu, nhận diện bất thường, gom nguyên nhân tiềm năng và tạo tóm tắt cho người vận hành. Quy trình cũng cần quy định khi nào AI chỉ ghi nhận, khi nào tạo cảnh báo và khi nào đẩy thông tin sang kênh xử lý của đội IT. Đây là phần cần làm sát thực tế, vì mỗi doanh nghiệp có cách đặt ngưỡng, cách chia ca trực và cách phân quyền khác nhau.Tích hợp với hệ thống hiện có
Bizfly Cloud AI có thể được kết nối với hệ thống giám sát, ticket, kênh thông báo nội bộ, dashboard vận hành hoặc data warehouse tùy hiện trạng của khách hàng. Mục tiêu không phải thay thế toàn bộ công cụ cũ, mà là bổ sung lớp phân tích và diễn giải dữ liệu. Khi tích hợp đúng, DevOps vẫn làm việc trên luồng quen thuộc nhưng nhận được thông tin giàu ngữ cảnh hơn.Chạy thử trong phạm vi nhỏ
Giai đoạn thử nghiệm nên bắt đầu từ một nhóm server hoặc một dịch vụ có lịch sử phát sinh cảnh báo rõ ràng. Trong giai đoạn này, đội IT so sánh kết quả AI với cách xử lý thủ công trước đó để xem AI có gom đúng tín hiệu, giảm nhiễu cảnh báo và gợi ý đúng hướng kiểm tra hay không. Các phản hồi của DevOps, SRE và System Admin được dùng để tinh chỉnh quy trình.Đo lường, tinh chỉnh và mở rộng triển khai
Sau giai đoạn thử nghiệm, doanh nghiệp đánh giá mức độ phù hợp của cảnh báo, chất lượng tóm tắt, độ hữu ích của gợi ý xử lý và khả năng hỗ trợ báo cáo quản lý. Những nguồn dữ liệu chưa sạch, cảnh báo chưa đúng mức ưu tiên hoặc log còn nhiễu sẽ được điều chỉnh. Khi quy trình ổn định, hệ thống có thể mở rộng sang nhiều nhóm server, nhiều môi trường hoặc nhiều hệ thống ứng dụng hơn.
Kinh nghiệm thực tế là không nên kỳ vọng AI hiểu đúng mọi bất thường ngay từ lần chạy đầu. Với dữ liệu vận hành, mỗi doanh nghiệp có thói quen hệ thống riêng: có server thường xuyên tăng CPU vào một khung giờ, có tác vụ nền chạy định kỳ, có API chỉ chậm trong một số chiến dịch traffic cao. Vì vậy, giai đoạn tinh chỉnh phải có người vận hành tham gia phản hồi. AI càng được gắn với ngữ cảnh vận hành thật, kết quả càng có giá trị.
Kết quả và giá trị nhận được

Kết quả và giá trị nhận được trong AI giám sát hiệu năng Cloud Server
Sau khi triển khai bài toán giám sát hiệu năng Cloud Server, thay đổi đầu tiên thường thấy là đội IT bớt mất thời gian ở bước đọc và gom dữ liệu ban đầu. Thay vì mở từng dashboard, đối chiếu từng log và tự suy luận từ nhiều nguồn, DevOps có một bản tóm tắt sự kiện để bắt đầu kiểm tra. Việc này không thay thế kỹ năng kỹ thuật, nhưng giúp kỹ sư tập trung nhanh hơn vào phần cần xác minh.
Giá trị thứ hai nằm ở việc cảnh báo được đặt trong bối cảnh vận hành. Một chỉ số tăng cao không còn được nhìn như một con số đơn lẻ, mà được xem cùng lịch sử tải, nhóm dịch vụ liên quan, log lỗi gần thời điểm đó và phạm vi ảnh hưởng. Với CTO hoặc Head of IT, đây là nền tảng để đánh giá nhóm server nào thường xuyên có rủi ro, dịch vụ nào cần tối ưu cấu hình và khu vực nào cần đưa vào kế hoạch nâng cấp.
Giá trị thứ ba là khả năng mở rộng vận hành mà không phải tăng tương ứng khối lượng kiểm tra thủ công. Khi số lượng Cloud Server tăng, nếu vẫn dùng cách đọc log thủ công và cảnh báo rời rạc, đội IT rất dễ quá tải. Bizfly Cloud AI giúp chuẩn hóa cách đọc tín hiệu, cách phân loại rủi ro và cách báo cáo hiệu năng. Nhờ đó, đội vận hành có thể kiểm soát nhiều điểm giám sát hơn mà vẫn giữ được quy trình xử lý có trật tự.
AI chưa làm được gì trong bài toán này

AI chưa làm được gì trong bài toán này
AI chưa thể tự chịu trách nhiệm cho các quyết định quan trọng liên quan đến hạ tầng sản xuất. Ví dụ, AI có thể gợi ý kiểm tra một dịch vụ, đề xuất tăng tài nguyên hoặc cảnh báo một nhóm log bất thường, nhưng quyết định restart service, thay đổi cấu hình, mở rộng tài nguyên hay rollback phiên bản vẫn cần con người phê duyệt. Với các hệ thống có yêu cầu nghiêm ngặt về bảo mật và uptime, bước kiểm soát của System Admin, DevOps hoặc SRE vẫn là bắt buộc.
AI cũng phụ thuộc nhiều vào chất lượng dữ liệu đầu vào. Nếu log thiếu mốc thời gian, metric không đồng nhất, server không được gắn tag rõ hoặc dữ liệu sự cố cũ không được ghi nhận, kết quả phân tích sẽ bị hạn chế. Bizfly Cloud AI trong tình huống này đóng vai trò hỗ trợ xử lý, tổng hợp, gợi ý và tự động hóa một phần quy trình giám sát hiệu năng Cloud Server. Nó không thay thế toàn bộ đội IT, nhất là trong các tình huống ngoại lệ, dữ liệu nhạy cảm hoặc quyết định có tác động lớn đến hệ thống sản xuất.
FAQ
Bizfly Cloud AI có thay thế công cụ giám sát hiện tại không?
Không nên hiểu bài toán này theo hướng thay thế hoàn toàn công cụ giám sát hiện tại. Bizfly Cloud AI thường được triển khai như một lớp phân tích bổ sung phía trên các nguồn metric, log và cảnh báo sẵn có. Công cụ giám sát vẫn giữ vai trò thu thập tín hiệu vận hành. AI giúp gom tín hiệu, giải thích ngữ cảnh và hỗ trợ đội IT ưu tiên xử lý.
AI giám sát hiệu năng Cloud Server phù hợp với doanh nghiệp nào?
Giải pháp này phù hợp với doanh nghiệp đang vận hành nhiều Cloud Server, nhiều dịch vụ backend hoặc hệ thống có yêu cầu cao về uptime và tốc độ phản hồi. Nhóm hưởng lợi trực tiếp thường là DevOps, SRE, System Admin và Head of IT. Nếu doanh nghiệp chỉ có vài server đơn giản, nhu cầu AI có thể chưa cấp thiết. Nhưng khi số lượng cảnh báo, log và dịch vụ tăng lên, giá trị của lớp phân tích AI sẽ rõ hơn.
Dữ liệu đầu vào cần chuẩn bị gồm những gì?
Doanh nghiệp nên chuẩn bị metric tài nguyên như CPU, RAM, disk, network, response time, error rate và trạng thái dịch vụ. Nếu có log ứng dụng, log hệ thống, ticket sự cố, lịch sử thay đổi cấu hình và báo cáo lỗi cũ thì AI có thêm ngữ cảnh để phân tích. Dữ liệu không nhất thiết phải hoàn hảo ngay từ đầu. Tuy vậy, cần có bước chuẩn hóa tên server, nhóm dịch vụ, mốc thời gian và quyền truy cập trước khi chạy thử.
AI có thể tự xử lý sự cố server không?
AI có thể hỗ trợ nhận diện bất thường, tóm tắt sự kiện, gợi ý nguyên nhân và đề xuất bước kiểm tra tiếp theo. Tuy nhiên, AI không nên tự thực hiện các hành động có rủi ro cao trên môi trường production nếu chưa có cơ chế phê duyệt rõ ràng. Các quyết định như restart dịch vụ, thay đổi cấu hình hoặc mở rộng tài nguyên vẫn cần người có trách nhiệm kiểm soát. Đây là giới hạn quan trọng để tránh biến tự động hóa thành rủi ro vận hành.
Bizfly Cloud AI giúp CTO hoặc Head of IT ở điểm nào?
Với CTO hoặc Head of IT, giá trị không nằm ở việc đọc từng log chi tiết. Giá trị nằm ở báo cáo xu hướng hiệu năng, nhóm server có rủi ro, loại sự cố lặp lại và khu vực cần ưu tiên cải thiện. Bizfly Cloud AI có thể chuyển dữ liệu kỹ thuật rời rạc thành bản tóm tắt dễ theo dõi hơn cho quản lý. Nhờ vậy, quyết định về nâng cấp hạ tầng hoặc điều chỉnh quy trình vận hành có cơ sở rõ hơn.
Có cần triển khai trên toàn bộ hệ thống ngay từ đầu không?
Không nên triển khai toàn bộ ngay từ đầu nếu dữ liệu còn phân tán hoặc quy trình vận hành chưa thống nhất. Cách hợp lý là chọn một nhóm server, một dịch vụ quan trọng hoặc một luồng cảnh báo thường xuyên gây quá tải cho đội IT. Sau giai đoạn chạy thử, doanh nghiệp đánh giá chất lượng cảnh báo, độ chính xác của tóm tắt và mức hữu ích của gợi ý xử lý. Khi quy trình ổn định, phạm vi triển khai có thể mở rộng dần.
Kết bài
Với bài toán giám sát hiệu năng Cloud Server, vấn đề chính của doanh nghiệp không phải là thiếu dữ liệu vận hành. Vấn đề nằm ở việc dữ liệu quá phân tán, cảnh báo thiếu ngữ cảnh và đội IT mất nhiều thời gian để xác định điểm cần xử lý trước.
Bizfly Cloud AI giúp biến quá trình giám sát hiệu năng từ một công việc phụ thuộc nhiều vào thao tác thủ công thành một quy trình có thể đo lường, phân loại và mở rộng. Từ nền tảng này, doanh nghiệp có thể tiếp tục triển khai các bài toán liên quan như phân tích log, dự báo tải, cảnh báo rủi ro và hỗ trợ xử lý sự cố để hình thành một hệ thống vận hành Cloud Server chủ động hơn.