Sự khác biệt giữa Failover và Back-Up?
Bảo vệ hệ thống quản lý học tập (learning management system) khỏi downtime và lưu dữ liệu ở một nơi an toàn để phục hồi sau thảm họa là hai việc hoàn toàn khác nhau. Để bảo vệ hệ thống một cách hiệu quả, bạn cần thực hiện cả hai điều trên. Một bản back-up sẽ tạo ra một bản sao của hệ thống hiện tại và lưu trữ nó để phục vụ cho việc phục hồi sau này. Failover, tức là nếu server mà hệ thống quản lý học tập chạy, bỗng dưng không hoạt động (fail) hoặc bị quá tải, nó sẽ tự động chuyển sang server khác.
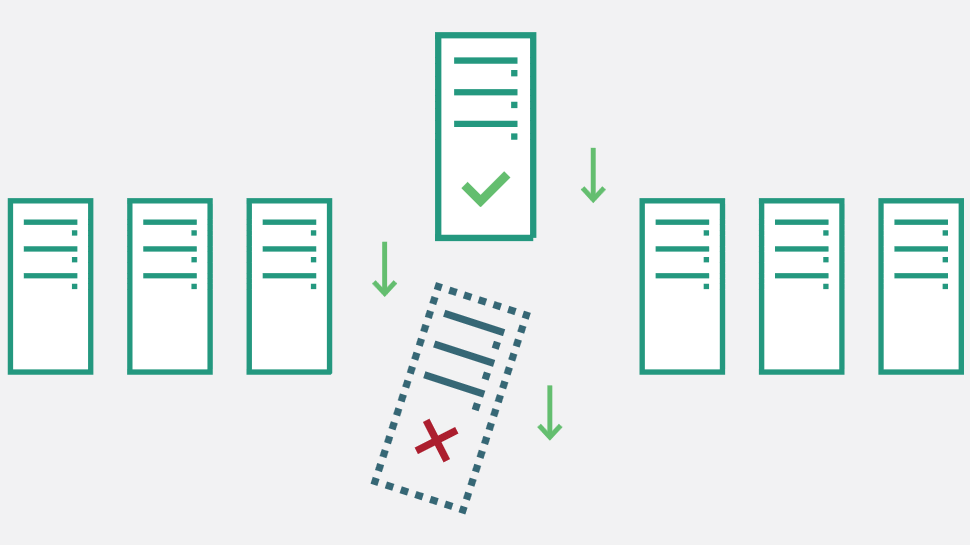
Về cơ bản, failover system hoạt động bằng cách chuyển đổi qua lại giữa hai hoặc nhiều server khác nhau. Khi một máy chủ dự phòng cảm nhận trạng thái failover từ production server đang chạy LMS, nó sẽ tiếp quản lưu lượng truy cập từ máy chủ bị lỗi đó. Có một số cách bạn có thể thiết lập failover system. Ví dụ, một số failover system yêu cầu sự can thiệp của con người để chuyển từ một máy chủ sang máy chủ tiếp theo.
Tuy nhiên, đối với các LMS được lưu trữ trên Bizfly Cloud, cung cấp failover tự động, đảm bảo các hệ thống không bị down. Failover cơ bản có nghĩa là một máy chủ dự phòng có thể cảm nhận được sự chậm chạp khi máy chủ sản xuất ngừng hoạt động. Ngay cả với các hệ thống tốt nhất, không may vẫn có những sai sót có thể xảy ra, vì vậy dự phòng theo kế hoạch là một lựa chọn khôn ngoan hơn. Có nhiều phiên bản nâng cao hơn của failover liên quan đến load balancing để giảm sự chậm trễ của hệ thống.
Failover cho quá tải máy chủ
Nếu bạn đã tăng lưu lượng truy cập đến máy chủ, failover sẽ phân bổ lưu lượng đó ra các máy chủ thay thế để tránh tình trạng quá tải. Quá tải máy chủ có thể dẫn đến sự cố ở mức tồi tệ nhất và thời gian phản hồi chậm nghiêm trọng nhất. Load balancer lan truyền lưu lượng từ một máy chủ đến nhiều máy chủ. Có một số phương pháp phổ biến để xác định cách lưu lượng truy cập mạng sẽ được định tuyến lại.
Chúng ta có thể phân phối lưu lượng truy cập dựa trên vị trí địa lý của người dùng, vì vậy tất cả lưu lượng truy cập ở khu vực A có thể đi đến các máy chủ ở A và tất cả lưu lượng truy cập ở khu vực B sẽ đến máy chủ ở B. Nếu người dùng tập trung chủ yếu nằm ở một vùng nhất định, chúng ta có thể sử dụng phương pháp weighted round robin để cân bằng tải.
Cách tiếp cận weighted round robin sẽ thăm dò tất cả các máy chủ một cách thường xuyên để xác định xem server nào đang tải nhẹ, tải nặng. Những server có tải nặng được chuyển hướng lưu lượng truy cập đến các server có tải nhẹ hơn. Weighted Round-robin cho phép chúng ta kiểm soát nơi lưu lượng truy cập được điều hướng và có thể hoạt động cùng với cân bằng địa lý (geographic balancing). Điều tuyệt vời về cân bằng tải là nó liên tục tối ưu hóa các tài nguyên để cải thiện thời gian phản hồi.
Theo Bizfly Cloud chia sẻ
>> Có thể bạn quan tâm: Failover và Load Balancing - các khái niệm cơ bản